信号处理 在众多数据科学任务中至关重要,尤其是在我们深入探索 音频文件处理、图像解析乃至生物测量数据分析 等复杂场景时,掌握并优化这些数据处理技术是非常有必要的
本文将介绍三种基于机器学习的算法,它们分别适用于两个应用场景:主成分分析(PCA)用于降维和特征提取,独立成分分析(ICA)和 非负矩阵分解(NMF)用于源信号分离。
这三种方法都在scikit-learn中有现成的实现,可直接用于你的项目。
但本文将展示如何从零开始实现这些方法,仅使用OpenCV来打开和保存图像,以及NumPy来处理矩阵。
另外大家想更系统的学习机器学习在信号处理中的应用,可以看看下面这篇文章中推荐的书籍。
点击图片即可跳转
本文将概括PCA的实现要点,PCA的主要目的是找出数据集中最能捕获整体信息特征的子集,以便我们在信息损失最小的情况下降低维度。
例如,在将训练图像数据送入深度神经网络进行分类之前,我们可以通过降低图像的维度来缩短计算时间。
降维有多种方法,如高相关性滤波、随机森林或反向特征消除等。
PCA通过识别主成分(即原始特征的线性组合)来完成这一任务。
这些成分被提取出来,使得第一主成分捕获数据集中的最大方差,第二主成分捕获剩余方差且与第一主成分不相关,依此类推。
作为示例,我们将使用包含982张手写数字4的图像数据集。
每张图像原始尺寸为28x28,但在应用PCA之前,我们首先将其重塑为784维的1D向量,从而使整个数据集形状变为982x784。
 输入图像
输入图像
要使用PCA将特征数量减少到k,我们首先需要计算该数据集的协方差矩阵。
然后,计算协方差矩阵的特征向量和对应的特征值。
def pca(img, n_components=9): """ Perform PCA dimensionality reduction on the input image :param img: a numpy array of shape (n_samples, dim_images) :param n_components: number of principal components for projection :return: image in PCA projection, a numpy array of shape (n_samples, n_components) """
cov_mat = np.cov(img.T)
eig_val_cov, eig_vec_cov = np.linalg.eig(cov_mat)
eig_pairs = [ (np.abs(eig_val_cov[i]), eig_vec_cov[:, i]) for i in range(len(eig_val_cov)) ]
为了选择k个主成分,我们将特征向量和特征值对按特征值降序排序,并选择特征值最大的k个特征向量,因为它们包含的数据信息最多。
最后,我们得到一个形状为784xk的矩阵W,并将其与数据集的转置相乘,得到降维后的数据,形状为kx982。
eig_pairs.sort(key=lambda x: x[0], reverse=True) eig_pairs = np.array(eig_pairs) matrix_w = np.hstack( [eig_pairs[i, 1].reshape(img.shape[1], 1) for i in range(n_components)] )
return np.dot(img, matrix_w), matrix_w
为了重构降维后的数据,我们只需将降维后的数据与先前获得的矩阵W的逆矩阵相乘,这样得到的数据维度与原始数据相同。
最后,我们将2D数据重塑为982x28x28的3D矩阵,以便重新可视化图像集。
def inverse_pca(img, components): """ Obtain the reconstruction after PCA dimensionality reduction :param img: Reduced image, a numpy array of shape (n_samples, n_components) :param components: a numpy array of size (original_dimension, n_components) :return: """ reconstruct = np.dot(img, components.T).astype(int) return reconstruct.reshape(-1,28,28) pca_images, components = pca(flat_images, k)
print(pca_images.shape)
reconstruct = inverse_pca(pca_images, components)
通过计算原始图像与重构图像之间每个像素的均方误差,我们可以得到重构误差。
 使用 PCA 进行降维的结果,使用 MSE 测量的误差
使用 PCA 进行降维的结果,使用 MSE 测量的误差
上述结果表明,选取的主成分越多,重构误差越小。
这是因为维度降低越多,用于重构的原始信息损失就越多,为了在选择组件数量时优化降维与信息保留之间的权衡,一个常见的方法是计算每个组件数量的PCA解释方差,并选择方差在95-99%之间的组件数量,以确保不会丢失太多数据信息。

从左到右:原始图像,从 2、16、64、256 个分量重建
这篇文章的完整代码和信号处理机器学习教程书一起打包好了,大家可以添加小助手获取,记得发送文章标题截图给小助手哦!

现在,我们有一个包含1000张图像的数据集,这些图像是手写数字0、1、4、7以不同比例混合而成的。
我们的目标是从这些混合图像中恢复出源图像。
 源图像
源图像
 混合数据
混合数据
分离线性混合信号的一种方法是使用独立成分分析(ICA)。
信号混合可以定义为矩阵乘积WH = X,其中H是包含不同源信号的矩阵,W定义了混合时各源的比例,X是混合输出。
ICA旨在恢复矩阵W,从而我们可以计算H = W(-1)是X的逆矩阵。
但ICA并非适用于任何混合信号,首先,混合信号必须是源信号的线性组合,正如前面的矩阵乘积所示。
其次,ICA假设源信号是独立的,而混合信号不是(因为它们共享相同的源信号),并利用这一事实进行分离。
最后,ICA还假设源信号是非高斯的,并利用中心极限定理,即两个信号的和的分布比它们自身更接近高斯分布。
我们可以使用FastICA算法高效地执行ICA。
算法初始化时,使用维度为(n_sources, n_samples)的随机权重W,其中n_sources表示我们要分离的源数量(本例中为4),n_samples表示图像样本数量(本例中为1000)。
对于每个要分离的源,我们迭代与该源相关联的权重。
def ica(X, step_size=1, tol=1e-8, max_iter=10000, n_sources=4): m, n = X.shape
W = np.random.rand(n_sources, m) for c in range(n_sources): w = W[c, :].copy().reshape(m, 1) w = w / np.sqrt((w ** 2).sum())
对于集合W中的每个权重向量w,算法旨在最大化投影v=w.TX的非高斯性(其中w.T是w的转置)。
为了度量非高斯性,算法采用了一个非二次非线性函数f(v)、其一阶导数g(v)和二阶导数g'(v)。
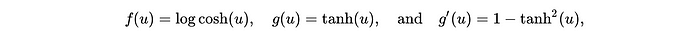
利用这些函数,我们采用梯度下降法来更新权重。
for i in range(max_iter): # Dot product of weight and input v = np.dot(w.T, X)
# Pass w*s into contrast function g gv = np.tanh(v*step_size).T
# Pass w*s into g prime gdv = (1 - np.square(np.tanh(v))) * step_size
# Update weights wNew = (X * gv.T).mean(axis=1) - gdv.mean() * w.squeeze()
随后,对权重进行归一化和去相关处理。去相关是为了确保后续源的迭代不会返回与先前迭代中获得的源相同的输出。
最后,我们检查是否收敛,以决定是停止迭代还是继续。
wNew = wNew - np.dot(np.dot(wNew, W[:c].T), W[:c]) wNew = wNew / np.sqrt((wNew ** 2).sum())
lim = np.abs(np.abs((wNew * w).sum()) - 1) w = wNew if lim < tol: break
W[c, :] = w.T return W
要从ICA的输出W中获取原始源,我们只需将W与给定的输入数据相乘,得到一个维度为(n_sources, n_features)的矩阵,然后将其重新塑形为原始的3D维度,从而得到图像。
 ICA 分隔的四个源
ICA 分隔的四个源
上述ICA的结果显示,它能够在一定程度上识别并提取出图像0、4和7,但未能提取出图像1,反而返回了一个看似多个源图像叠加在一起的图像。
分离混合信号的第二种方法是非负矩阵分解(NMF)。
与ICA类似,NMF也旨在将混合数据X分解为矩阵乘积WH=X,但这里增加了一个约束条件,即每个矩阵X、W、H均为非负。
这一约束在数据本质上为非负的应用中具有优势,同时也能提供更易于解释的结果。
应用NMF时,我们首先随机初始化W和H。
def nmf(X, tol=1e-6, max_iter=5000, n_components=4):
W = np.random.rand(X.shape[0], n_components) H = np.random.rand(n_components, X.shape[1])
oldlim = 1e9
eps = 1e-7
然后,在每次迭代中,我们先根据旧的H和W更新新的H,再根据H和旧的W更新新的W,这一过程采用乘法更新规则,直至收敛。
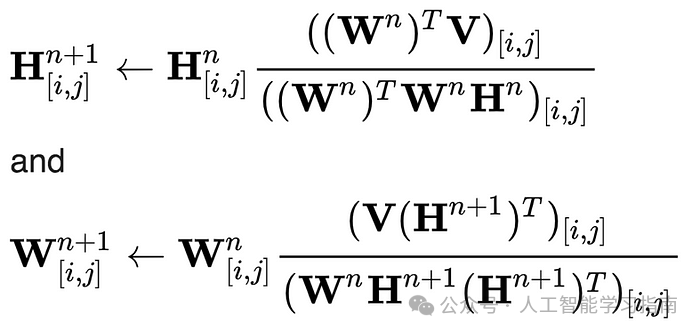
乘法更新规则
我们使用X与WH之间的弗罗贝尼乌斯范数来检查收敛性。
for i in range(max_iter): # Multiplicative update steps H = H * ((W.T.dot(X) + eps) / (W.T.dot(W).dot(H) + eps)) W = W * ((X.dot(H.T) + eps) / (W.dot(H.dot(H.T)) + eps))
# Frobenius distance between WH and X lim = np.linalg.norm(X-W.dot(H), 'fro')
# Check for convergence if abs(oldlim - lim) < tol: break
oldlim = lim
最后,对得到的H矩阵进行归一化处理,并将其重新塑形以包含2D图像,然后保存可视化结果。

通过NMF分离出的四个源
如上所述,对于我们的示例,NMF算法的效果明显优于ICA。
如果大家想更进一步学习机器学习、深度学习、神经网络技术的可以看看以下文章(文章中提到的资料都打包好了,都可以直接添加小助手获取)
大家觉得这篇文章有帮助的话记得分享给你的朋友、同学、闺蜜、敌蜜、死党!