0.前言
简单容易的套路科研要掌握,顶刊研究也要跟进。学习要覆盖不同等级,不同方向,不同难易程度的研究。本文介绍自监督在心动超声中的诊断应用,是一个有意思的研究。
本篇是以前助理写的推文,一直库存没有发。
超声心动图,是一种使用超声波检查心脏的医学成像技术。使用深度学习,建立模型可以提高医学图像诊断的效率和准确性。
0.1论文信息

0.2期刊信息

0.3研究背景
SS自监督的缩写,自监督,半监督在病理图像处理应用的也比较多
(1)SSL技术已经发展到可以从小型标记数据集中实现高水平的自动化医学图像诊断。
(2)尽管SSL在医学成像领域取得了进展,但大多数方法并未针对视频模态进行优化,例如超声心动图这类动态影像技术。
说的对,绝大多是对静态影像数据处理的,动态影像处理难度高,所以门槛高,可以出好的研究成果。
0.4概念介绍
(1)自监督学习(Self-Supervised Learning, SSL)
一种机器学习方法,它允许模型从未标记的数据中学习。在SSL中,模型通过预测数据的某些属性或通过解决预定义的“预训练”任务来生成自己的标签。
(2)
多实例学习(Multi-Instance Learning)
一种学习方法,其中模型使用多个实例(在这个研究中是视频)来表示单个训练样本,并从这些实例中学习共同的特征。
(3)帧重排序(Frame Reordering)
一种预训练任务,模型被训练来预测视频帧在随机打乱后的顺序,以学习视频的时间结构信息。
1研究介绍
1.1 目的
(1)解决在医学图像识别中需要大量专家标注数据的难题,通过使用少量标记数据实现高效的模型训练和诊断。
(2)针对超声心动图这种视频模态的医学影像,改进SSL方法,使其能够处理动态的、时间序列的医学数据。
1.2 方法
研究人员为超声心动图视频开发了一种自监督对比学习方法,EchoCLR,其目标是学习有效的特征表示,以便在下游心脏疾病诊断中进行高效的微调。EchoCLR预训练包括:
1.3 结果
在少量标记数据微调时,EchoCLR预训练在LVH和AS的分类性能上显著优于其他迁移学习和自监督学习方法。
2 数据介绍
2.1 数据来源
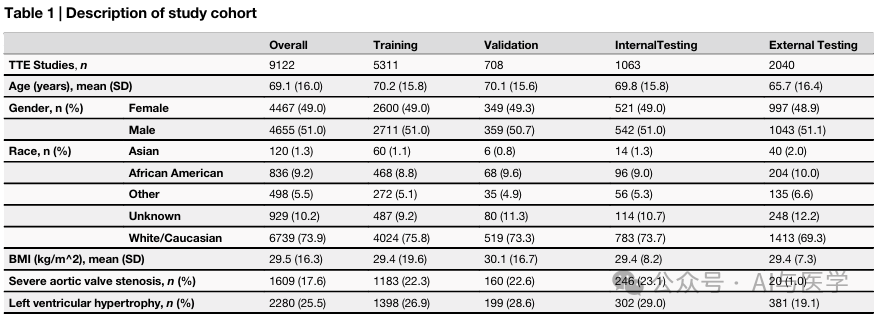
(1)研究提取了2016至2021年间在耶鲁纽黑文医院进行的12,500项TTE研究数据。其中10,000项用于模型开发,2500项用于模型评估。
(2)由于严重的主动脉瓣狭窄(AS)是一种不常见的病症,因此:
2016年至2020年的10,000项研究中,严重AS的样本被过采样了50倍,非严重AS的样本被过采样了5倍,以确保有足够的阳性样本进行可靠的模型开发和验证。
2021年的2500项研究没有针对AS进行富集,作为时间上不同的外部测试集。
2.2 视图分类
(1)研究采用了胸骨旁长轴(PLAX)视角的单视角超声心动图
(2)使用预训练TTE视角分类器,从447,653个视频中随机选取了十个去标识化的帧,并将10个帧级别的预测视角概率平均,形成单个视频的视角预测。
(3)预训练的视角分类器能够区分PLAX视角的不同变体,只保留了被分类器置信度最好高的“PLAX”视角的视频。
3 方法细节
3.1 数据预处理与分类
(1)排除不符合要求的超声心动图。
(2)将2016至2020年的研究视频随机分为训练集、验证集和内部测试集。
(3)AS的严重程度由原始超声心动图报告确定,并反映了解读医生最终评定的严重程度等级。
(4)由于严重AS的检测被制定为二元分类任务,所有非“严重AS”的AS指派都被归入“非严重AS”类别。
(5)左心室肥厚(LVH)的定义基于性别特定的左心室质量指数阈值,即女性的指数大于95克/平方米,男性的指数大于115克/平方米。
3.2 自监督预训练
(1)通过自监督预训练学习PLAX超声心动图视频的可转移特征,以便在下游心脏疾病分类任务中使用。
(2)设计了一个针对超声心动图名为EchoCLR的SSL算法,该算法组成:
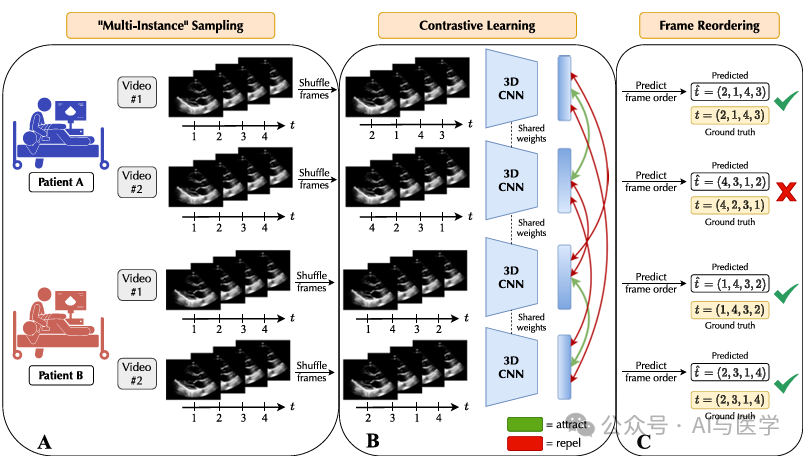
(3)采用SimCLR框架进行对比学习,通过随机图像增强产生图像的两个视图,并学习它们的表示。
(4)使用温度归一化的交叉熵(NT-Xent)损失函数来鼓励模型学习来自同一图像的相似表示和来自不同图像的不同表示。
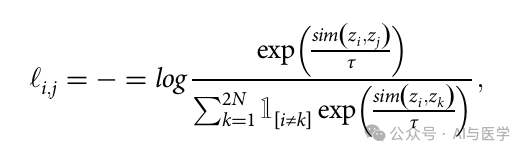
(5)预训练参数:
(6)MI-SimCLR和EchoCLR模型训练300个周期,SimCLR模型训练520个周期以匹配优化步骤数。
(7)预训练使用了随机采样的4连续帧视频片段,平衡了计算效率和心脏周期的重复阶段。
3.3 监督微调
(1)使用监督学习对三种不同初始化方法(SSL、Kinetics-400、随机初始化)的模型进行微调。
(2)在不同比例的标记训练数据上微调模型,并进行训练。
3.4模型可解释性与性能评估
(1)使用Grad-CAM方法对严重AS诊断进行显著性图分析,以评估EchoCLR模型的可解释性。
(2)利用AUROC和AUPR评估微调后的严重AS和LVH分类模型的性能。
(3)通过自助法计算95%置信区间,使用百分位数方法生成非参数置信区间,并通过pROC库进行p值计算,确保实验的统计意义和可复现性。
4 详细结果
4.1 标记高效的重度 AS 分类
(1)在严重AS分类任务中,EchoCLR和Kinetics-400预训练表现类似。
(2)使用所有可用微调数据,EchoCLR和Kinetics-400预训练在内部和外部测试集上都实现了高AUROC值。
(3)在小规模标记数据集上,EchoCLR预训练在严重AS分类任务上优于Kinetics-400和随机初始化模型。
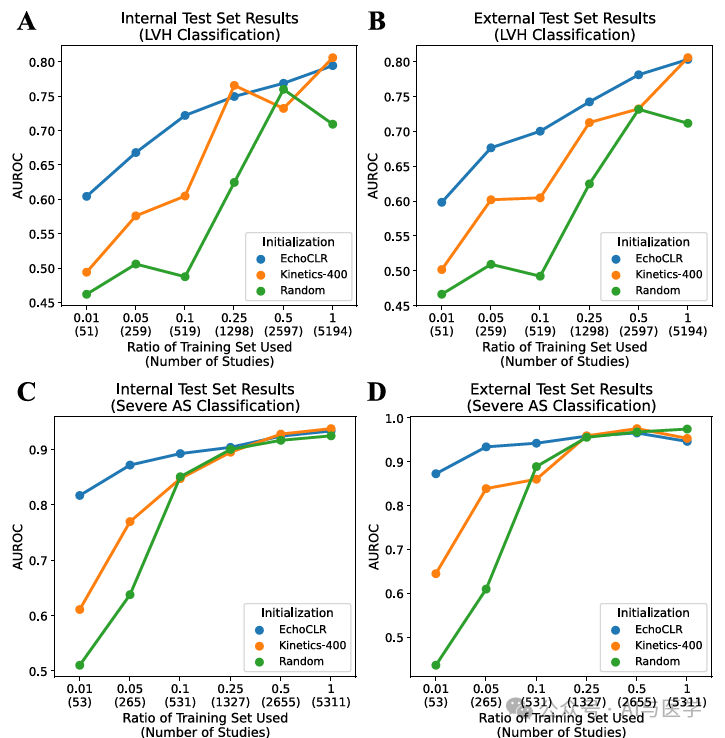
(4)EchoCLR预训练在1%的训练数据上的性能提升在统计上显著优于其他方法。
(5)在微调至少25%的数据后,所有初始化方法的性能相当。
(6)在AUPR评估指标上也观察到与AUROC一致的趋势。
4.2 多实例采样和帧重排序对 EchoCLR 的影响
(1)比较了EchoCLR及其两个变体的分类性能,EchoCLR预训练在LVH和严重AS分类上显著优于其他自监督预训练方法。多实例采样和帧重排序为疾病诊断提供了互补的改进。
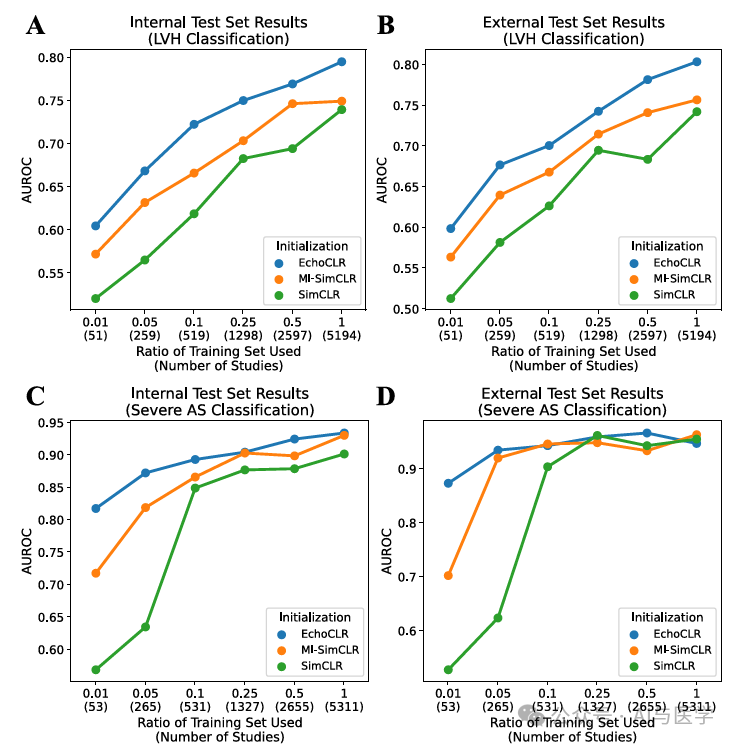
(2)使用1%和10%的训练数据进行微调时,EchoCLR预训练模型在AUROC上均优于MI-SimCLR和SimCLR预训练模型。
4.3 使用EchoCLR提高可解释性
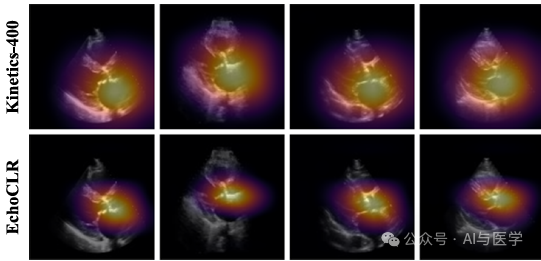
(1)采用Grad-CAM方法生成显著性热图以确保EchoCLR模型的预测依赖于与临床诊断相关的图像区域。
(2) 将EchoCLR与标准迁移学习方法(Kinetics-400预训练)进行比较,发现:
5 学习心得
(1)论文中的EchoCLR通过结合多实例学习和帧重排序任务来增强模型的时间序列理解能力,这表明创新的算法设计可以显著提升模型性能。
(2)在标记数据稀缺的情况下,EchoCLR模型的开发展示了自监督学习在医学图像分析中的巨大潜力。
(3)研究的技术相对难一些,自监督可以解决需要大量标注的问题,是一个好方向。
引用
[1] Holste G, Oikonomou EK, Mortazavi BJ, Wang Z, Khera R. Efficient deep learning-based automated diagnosis from echocardiography with contrastive self-supervised learning. Commun Med (Lond). 2024 Jul 6;4(1):133. doi: 10.1038/s43856-024-00538-3. PMID: 38971887; PMCID: PMC11227494.
感谢您的阅读,如果您对这项研究感兴趣或想了解更多关于AI在医学中的应用,请继续关注我们,我们会定期分享最新的科研成果和健康资讯。别忘了点赞和转发哦!👍🔄










