本文最初发布于 The Register。
作为生成式人工智能的早期用例,代码助手实践已经获得了相当多的关注——尤其是在微软推出 GitHub Copilot 之后。但是,如果你不喜欢让微软动你的代码,或者不愿意每月支付 10 美元的费用,那么你可以构建自己的助手。
虽然微软是最早将人工智能代码助手 商业化 并集成到 IDE 中的公司之一,但它远不是唯一选项。事实上,有许多为代码生成而训练的大型语言模型(LLM)。
而且,你现在正在使用的电脑很有可能就能够运行这些模型。关键是以一种有实际用处的方式将它们集成到 IDE 中。
这就轮到像 Continue 这样的应用程序发挥作用了。这个 开源的代码助手 被设计成可以嵌入流行的 IDE,如 JetBrains 或 Visual Studio Code,并连接到你可能已经比较熟悉的流行的 LLM 运行程序,如 Ollama、Llama.cpp 和 LM Studio。
像其他流行的代码助手一样,Continue 支持代码补全和生成,并且能够针对不同的用例优化、注释或重构代码。此外,Continue 还提供了一个具有 RAG 功能的集成聊天机器人,让你可以有效地与代码库对话。
在本指南中,我们将搭配使用 Continue 与 Ollama,但 Continue 也可以与多个专有模型(包括 OpenAI 和 Anthropic)搭配使用——通过各模型的 API,如果你愿意按令牌付费而不是每月支付固定费用的话。
一台能够运行普通 LLM 的机器。一个处理器相对比较新的系统就可以,但为了获得最佳性能,我们建议使用 Nvidia、AMD 或 Intel GPU ,且 vRAM 至少为 6GB。如果你更喜欢用 Mac 电脑,那么任何 Apple Silicon 系统应该都可以,包括最初的 M1。不过,为了能达到最佳效果,我们建议内存至少要有 16GB。
本指南还假设,你已经在机器上安装并运行了 Ollama 模型运行程序。如果没有,可以看下我们提供的 这份指南,它应该可以帮你在十分钟内运行起来。对于那些使用 Intel Integrated 或 Arc 显卡的用户,这里 有一份使用 IPEX-LLM 部署 Ollama 的指南。
兼容的 IDE。在撰写本文时,Continue 支持 JetBrains 和 Visual Studio Code。如果你想完全避开微软的遥测技术,像我们一样,开源社区构建的 VSCodium 是个不错的选择。
在本指南中,我们将在 VSCodium 中部署 Continue。首先,启动 IDE 并打开扩展管理面板,搜索并安装 Continue。
几秒钟后,Continue 的初始设置向导启动,你可以选择是在本地托管模型还是使用另一个提供商的 API。
在这个例子中,我们将通过 Ollama 在本地托管我们的模型,因此,我们将选择“Local models(本地模型)”。该配置使 Continue 可以使用下列开箱即用的模型。稍后,我们会讨论如何将这些模型更换为其他选项,但现在,我们先从这些模型开始:
Llama 3 8B: 来自 Meta 的通用 LLM,用于注释、优化和 / 或重构代码。要了解关于 Llama 3 的更多信息,请阅读 我们的发布日报道。
Nomic-embed-text: 用于在本地索引代码库的嵌入式模型,使你能够在给集成聊天机器人提示时引用代码库。
Starcoder2:3B: 这是 BigCode 的一个代码生成模型,为 Continue 的 Tab 自动补全功能提供支持。
如果因为某种原因,Continue 跳过了启动向导,不要担心,你可以在终端运行以下命令,使用 Ollama 手动拉取这些模型:
ollama pull llama3ollama pull nomic-embed-textollama pull starcoder2:3b
有关使用 Ollama 设置和部署模型的更多信息,请查看我们的 快速入门指南。
在继续之前,需要提醒一下,在默认情况下,Continue 会收集匿名遥测数据,包括:
是否接受或拒绝建议(不包括代码或提示);
使用的模型名称和命令;
生成的令牌数量;
操作系统和 IDE 的名称;
访问量。
如果你不想自己的数据被收集的话,则可以修改主目录下的.continue文件,或者取消 VS Code 设置中的“Continue: Telemetry Enabled”复选框。

要进一步了解 Continue 的数据收集政策,可以查看 这里。
安装完成后,我们可以开始深入研究将 Continue 集成到工作流中的各种方法了。第一种方法可以说显而易见:从零开始生成代码片段。
例如,如果你想为一个项目生成一个基本的网页,只需按下键盘上的Ctrl-I或Command-I,然后在操作栏中输入提示。
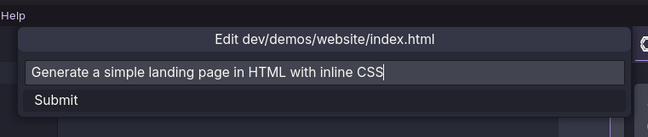
在这里,我们的提示是“Generate a simple landing page in HTML with inline CSS(使用 HTML 生成一个包含内联 CSS 的简单登录页)”。提交提示后,Continue 将加载相关模型(这可能需要几秒钟,取决于你的硬件),然后它会向我们提供一个代码片段,我们可以选择接受或拒绝。
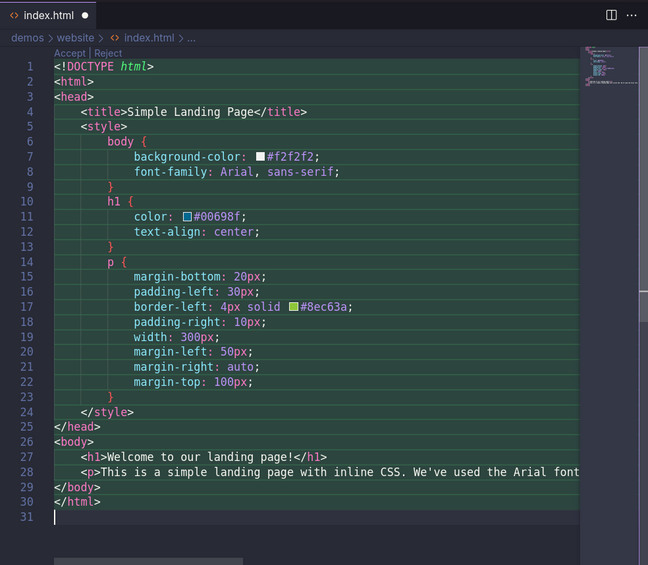
在 Continue 中生成的代码将以绿色代码块的形式出现在 VS Code 中,你可以接受或拒绝。
Continue 还可以用于重构、注释、优化或编辑现有代码。
例如,假设你有一个用于在 PyTorch 中运行 LLM 的 Python 脚本,你想重构它然后在 Apple Silicon Mac 上运行。首先,选择需要重构的文档,按下键盘上的Ctrl-I并给助手输入提示。
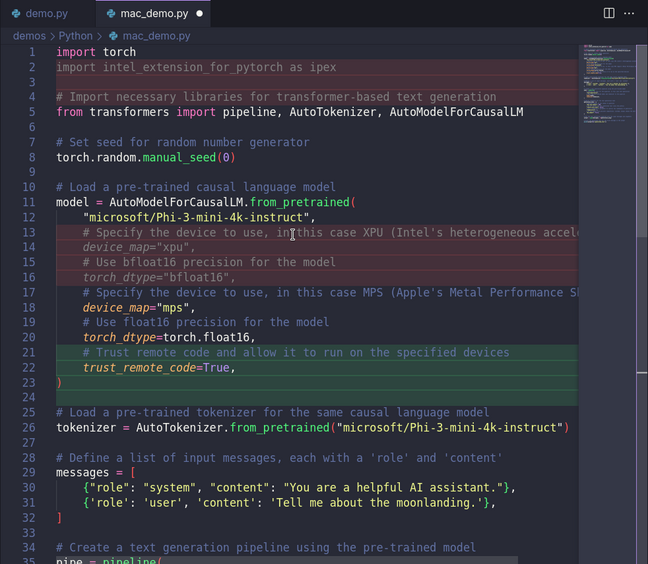
几秒钟后,Continue 会传出模型的建议——新生成代码用绿色高亮显示,而需要删除的代码则用红色标记。
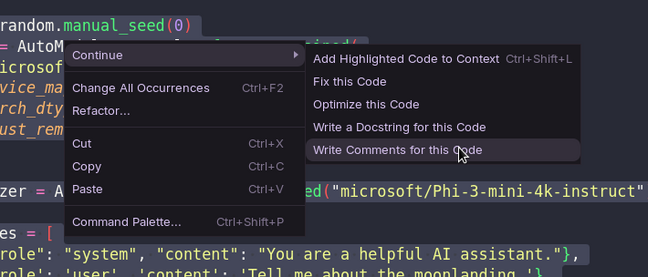
除了重构现有代码外,该功能还可用于事后生成注释和 / 或文档字符串。这些功能可以在右键菜单中的“Continue”下找到。
虽然代码生成对于快速实现模型进行概念验证或重构现有代码很有用,但根据所使用的模型的不同,仍然可能存在一些偶然性。
任何曾经要求 ChatGPT 生成代码块的人都知道,有时它会产生幻觉包或函数。这些幻觉相当明显,因为糟糕的代码往往会导致令人印象深刻的失败。但是,正如我们之前 讨论 过的那样,如果频繁提供这样的幻觉包,可能会造成安全威胁。
如果不需要 AI 模型为你编写代码,那么 Continue 还支持代码补全功能。这让你可以更好地控制模型进行或不进行哪些编辑或更改。
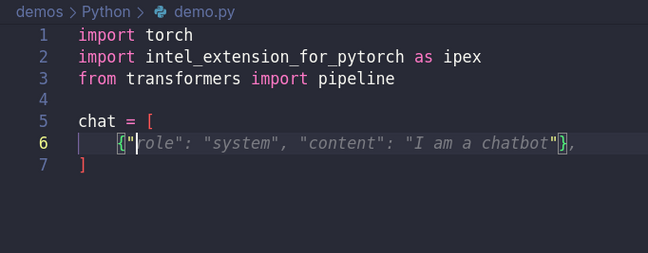
这个功能的工作方式有点像终端中的 Tab 补全。当你进行输入时,Continue 会自动将你的代码输入到一个模型中——比如 Starcoder2 或 Codestral——并提供补全字符串或函数的建议。
建议显示为灰色,并且会随着你每次敲击键盘而更新。如果 Continue 猜测正确,那么你可以按下键盘上的Tab键来接受建议。
除了代码生成和预测之外,Continue 还提供了一个集成聊天机器人。该机器人具有 RAG 风格的功能。要了解更多关于 RAG 的信息,可以在 这里 查看我们的实践指南,但在 Continue 中,它综合运用 Llama 38b 和 nomic-embed-text 嵌入式模型来实现代码库可搜索。
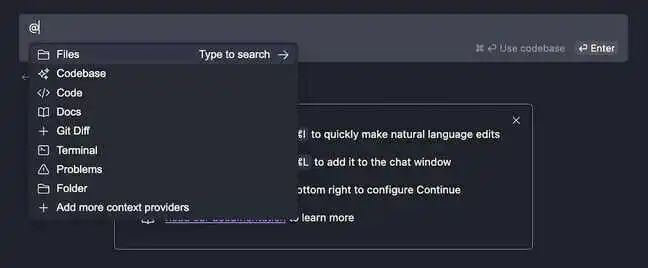
Continue 提供了一个集成聊天机器人,它可以接入你选择的 LLM。
诚然,这个功能存在一些不确定性,但下面这几个例子可以说明如何使用它来提高工作流效率:
输入@docs,然后输入你的应用程序或服务的名称—— 例如Docker,最后输入你的请求。
要查询关于工作目录的信息,输入@codebase ,然后输入你的请求。
将文件或文档加入模型的上下文:输入@files ,然后选择你想要添加到下拉选项中的文件。
按 Ctrl-L将你在编辑器中选中的代码添加到聊天机器人。
按Ctrl-Shift-R 将来自 VS Code 终端模拟器的错误信息直接发送给聊天机器人进行诊断。
在实践中,Continue 的可靠性实际上取决于你选用的模型,因为这个插件本身实际上更像是一个将 LLM 和代码模型集成到 IDE 中的框架。虽然它定义了用户如何与这些模型交互,但它无法控制所生成代码的实际质量。
好消息是,Continue 没有与任何一种模式或技术绑定。正如我们前面提到的,它可以接入各种 LLM 运行程序和 API。如果有新发布的模型针对你的首选编程语言进行了优化,那么除了硬件之外,没有什么可以阻止你使用它。
由于我们使用 Ollama 作为模型服务器,所以在大多数情况下,更换模型是一项相对比较简单的任务。例如,如果你想把 Llama 3 换成谷歌的 Gemma 29b,把 Starcoder2 换成 Codestral,则可以运行以下命令:
ollama pull gemma2ollama pull codestral
注意:Codestral 有 220 亿个参数和 32000 个令牌的上下文窗口,即使精度量化到 4 位,在本地运行的话,也是一个相当庞大的模型。如果遇到了程序崩溃的问题,那么你可能会想试一下小一点的东西,比如 DeepSeek Coder 的 1B 或 7B 变体。
要更换用于聊天机器人和代码生成器的模型,你可以在 Continue 的选择菜单中选择它。或者,你可以使用Ctrl-'循环遍历下载好的模型。
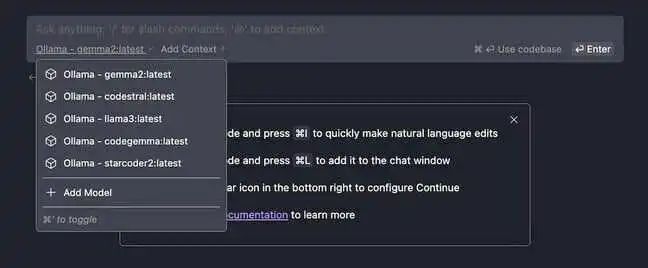
更改 Tab 自动补全功能使用的模型有点麻烦,需要修改插件的配置文件。
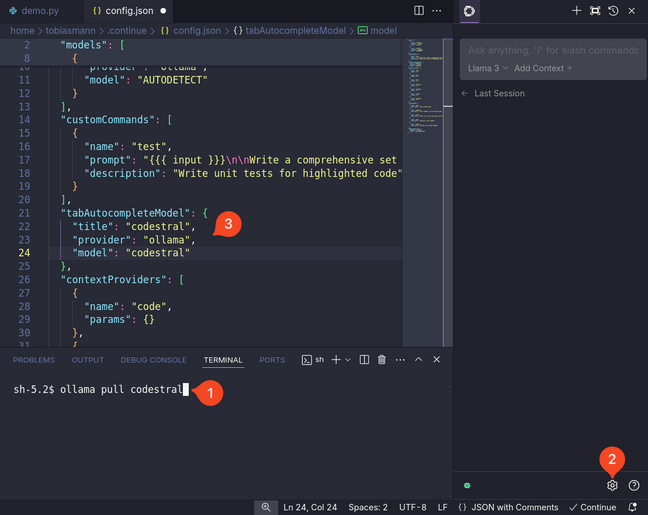
拉取选择的模型后 [1],点击 Continue 侧边栏右下角的齿轮图标 [2],修改“tabAutocompleteModel”小节下的“title”和“model”条目 [3]。如果你使用的是 Codestral,那么这一部分配置应该是这样的:
"tabAutocompleteModel": { "title": "codestral", "provider": "ollama", "model": "codestral" },
默认情况下,Continue 会自动收集有关你如何构建软件的数据。这些数据可用于根据你的特定风格和工作流进行自定义模型调优。
需要说明的是,这些数据存储在本地主目录下的.continue/dev_data文件夹下。而且,据我们所知,默认情况下,这些数据并没有包含在 Continue 收集的遥测数据中。不过,如果你还是担心的话,建议你把它关掉。
大型语言模型调优的具体内容超出了本文的范围,但你可以读下这篇文章,从中了解 Continue 收集了哪类数据以及如何利用这些数据。
我们希望可以在未来的实践中进一步探索调优过程,所以请务必在评论区分享你对本地 AI 工具(如 Continue)的看法以及你希望我们下一步做何种尝试。
原文链接:
https://www.theregister.com/2024/08/18/self_hosted_github_copilot/?td=rt-3a
声明:本文由 InfoQ 翻译,未经许可禁止转载。








