近年来,由于机器学习的发展与蛋白质序列和结构数据的积累,蛋白质设计发生了巨大的革新。这些由于技术革新而产生的新方法有望突破自然和实验进化的限制,加速生成用于生物技术和医学的功能性蛋白质。2024年2月15日,来自美国哈佛大学、麻省理工学院、英国牛津大学和Seismic Therapeutic的研究人员,在Nature Biotechnology上发表研究Machine learning for functional protein design。
本文总结了机器学习在功能性蛋白质设计中的应用,并讨论了这些方法的最新进展、应用挑战以及未来的趋势。蛋白质在生物系统中发挥着广泛且关键的作用。蛋白质的功能通常由其结构中的特定区域(如活性位点)决定。这些区域由序列中特定的氨基酸组成,形成了适合与特定分子(如底物、抑制剂、配体)结合的三维形状和化学环境。蛋白质设计的目标是通过发现具有特定功能的新的氨基酸序列,从而创造出能够在现有蛋白质功能基础上增强或拓展的新蛋白质。然而,由于蛋白质序列空间的庞大和功能序列的稀疏性,设计一个具有特定功能的蛋白质变得极为复杂。机器学习,尤其是在过去十年中的迅猛发展为提供了高效探索功能性蛋白质空间的新策略,并且为解决生物医药、农业和可持续性等领域的全球性问题提供了可能。蛋白质设计的应用主要分为三类:增强已有功能、设计新功能以及从头设计新蛋白质。增强已有功能通常是通过对现有蛋白质进行优化,使其在特定条件下表现出更优异的特性。而设计新功能则是基于相关功能的现有蛋白质,通过引入突变或其他设计手段,使其具备新的功能。从头设计则完全依赖计算方法,在没有天然模板的情况下设计出全新的蛋白质结构和功能。
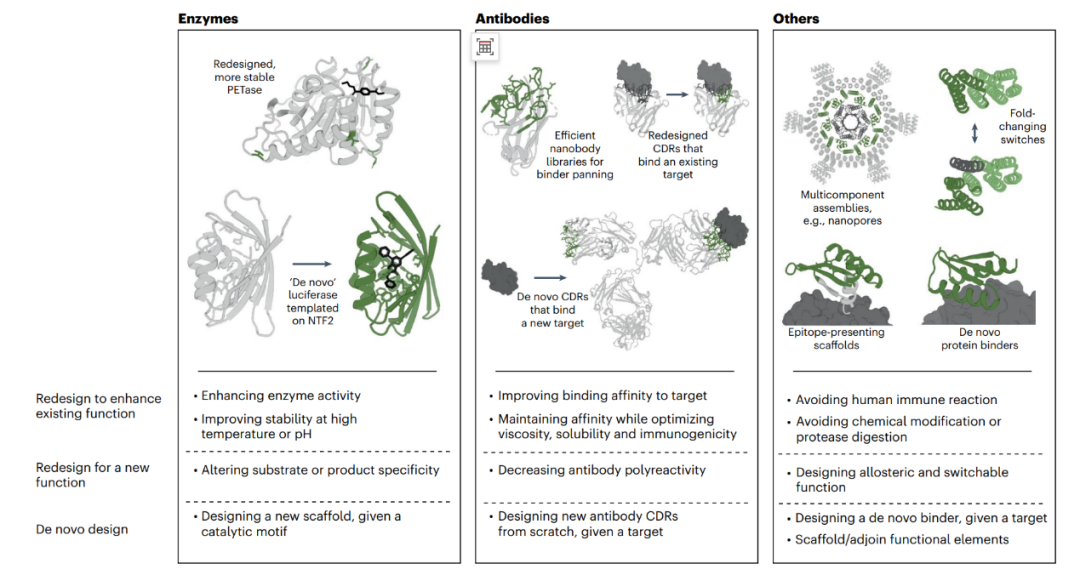
图2 蛋白质设计的应用。展示了在三类蛋白质设计目标中,不同类型蛋白质的机器学习驱动的设计应用示例。NTF2代表核转运因子2。
在机器学习驱动的蛋白质设计中,数据来源主要分为三类:序列、结构和功能标签。序列。科学家们已经在公开数据库中收集了数十亿条蛋白质序列。这些序列是从自然界中各种生物体中获取的。在这个漫长的进化过程中,只有那些有助于生物生存和繁衍的蛋白质序列才能被保留下来,这种选择过程导致了蛋白质序列中的进化约束。结构。数千个公开的蛋白质结构提供了蛋白质折叠和功能背后的生化相互作用的三维结构,帮助优化蛋白质的折叠和功能。功能标签。通过实验室生成的功能标签可以探索新的结合靶点、反应和生化条件,这些数据通常稀缺但逐渐增多。用于蛋白质设计的机器学习模型,可以分为基于序列的模型、序列-标签模型、基于结构的模型。基于序列的模型。基于序列的模型主要包括序列生成模型和条件序列模型。序列生成模型通过大规模蛋白质序列的训练,隐式捕捉蛋白质的生化约束。这类模型已经被用于生成具有特定功能的蛋白质序列。条件序列模型则通过条件生成过程,提供对生成序列性质的更大控制。
序列-标签模型。当具备足够多的功能标签时,可以训练监督模型,以预测某个给定蛋白质序列的功能表现。序列-标签模型通过标签效应的生成,可以为新的序列设计提供有效指导,减少实验筛选的工作量。
基于结构的模型。基于结构的模型则专注于预测蛋白质的三维结构,或生成新的蛋白质结构。逆折叠模型通过已知的三维结构生成相应的序列,而联合序列-结构模型则同时考虑序列与结构,生成具有目标功能的蛋白质。
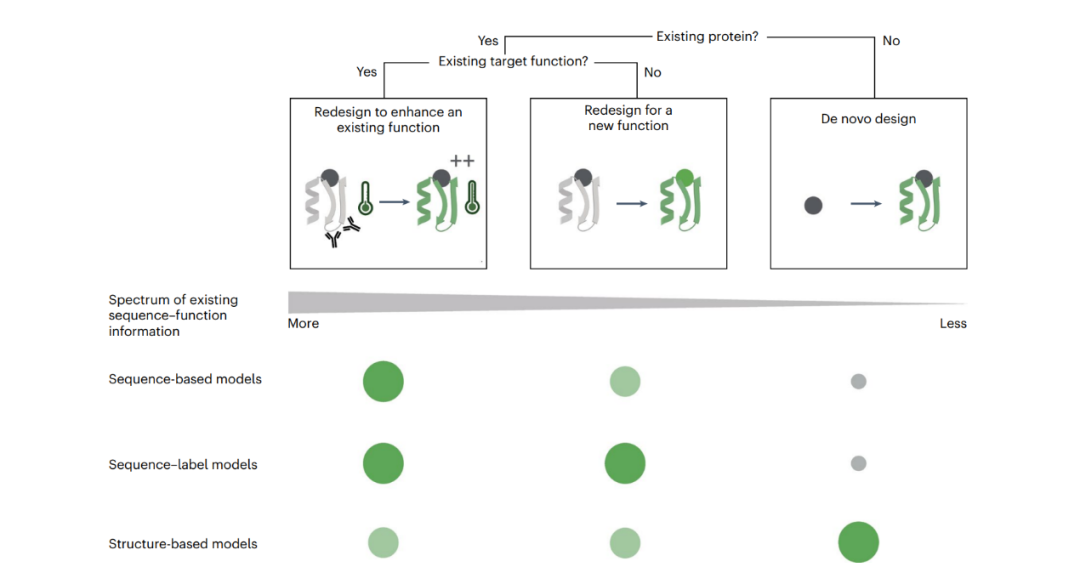
图1 蛋白质设计目标。根据设计目标与现有功能性蛋白质的距离,可以将蛋白质设计目标分为三类。圆圈的大小表示某种方法对特定设计任务的适用性。在选择设计方法时,可以选择忽略自然界中相关功能蛋白质的存在。例如,即使已有已知蛋白质能够执行所需功能,仍然可以使用从头设计方法,深入探索进化过程中尚未涉足的序列空间,但获得相同的功能。
机器学习方法已被应用于为各种蛋白质家族创建新的功能设计。酶设计。机器学习在酶设计中已显示出强大的潜力,特别是在提升酶的热稳定性和改变酶的特异性方面。例如,通过序列-标签模型,研究者能够优化酶的结构,使其在极端条件下仍能保持活性,从而提高酶的工业应用价值。抗体设计。抗体在生物医学中的应用广泛,机器学习已被用于优化抗体的亲和力和特异性,减少多重反应性,并实现从头设计抗体。例如,序列-标签模型被用于预测抗体序列的亲和力,并在此基础上优化抗体设计,减少实验筛选的成本和时间。从头设计新蛋白质。从头设计的新蛋白质是机器学习最具前景的应用之一。这些方法能够生成具有多样化三维折叠和多聚体排列的新蛋白质,并通过少量的实验设计,快速筛选出具有稳定表达的候选蛋白质。随着数据集规模的扩大和模型复杂度的提升,蛋白质语言模型在设计质量上有望进一步提高。未来可能通过扩大训练集和模型规模,提升机器学习在蛋白质设计中的应用效能。通过将越来越多的功能数据纳入模型训练中,未来的蛋白质设计将能够在更加精细的层面上实现对蛋白质功能和条件的控制,从而实现更为复杂和多样化的设计目标。
尽管现有的计算方法能够生成具有功能的蛋白质,但尚缺乏统一的评价框架来比较不同模型的设计能力。因此,开发新的评价方法和实验基准,对于推动蛋白质设计领域的发展至关重要。目前,序列模型、结构模型和序列-标签模型的界限日益模糊。未来,统一的设计模型有望融合多种方法的优点,支持高效的设计迭代和更具挑战性的从头设计任务。
Notin P, Rollins N, Gal Y, et al. Machine learning for functional protein design[J]. Nature biotechnology, 2024, 42(2): 216-228.感兴趣的读者,可以添加小邦微信加入读者实名讨论微信群。添加时请主动注明姓名-企业-职位/岗位 或 姓名-学校-职务/研究方向。











