接下来,我们来谈谈缺失值,它们就像是派对上的不速之客。
如果你不小心处理,它们可能会搞砸你的数据,破坏你的模型。
我们应该怎么解决它?主要有两种方法:
插补:这就像用估计值填补空白,你可以使用其他值的均值、中位数或众数,或者使用某种逻辑来填补空白。
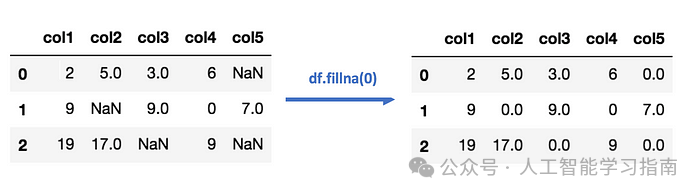
删除处理:这就像是把不请自来的客人请出,你可以移除包含缺失值的行或列。
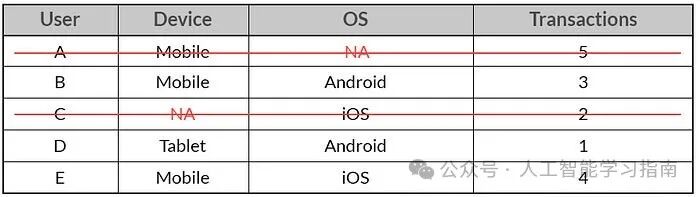
哪种方法最好?这要取决于你的数据, 如果缺失值很多,你可以使用插补法。
但如果只有少量缺失值,你可以直接删除它们。
处理分类值
数据可以分为两大类:数值型和分类型。
分类数据又可以进一步分为名义型和序数型,根据数据的类型,有不同的方法将分类数据转换为数值数据,这个过程叫做编码。
“编码指的是将分类数据转换为数值格式的过程。”
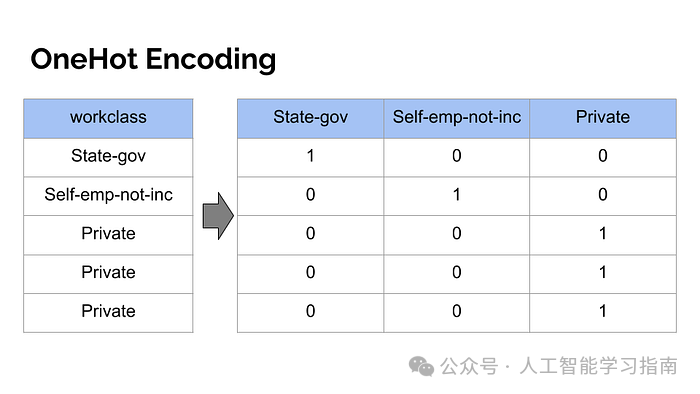
名义型数据是没有顺序的分类数据,比如地名或部门(就像你的领域一样)。
可以使用独热编码(One-Hot Encoding)将其转换为数值数据,这是Python中的一个库,叫做OneHotEncoder()。
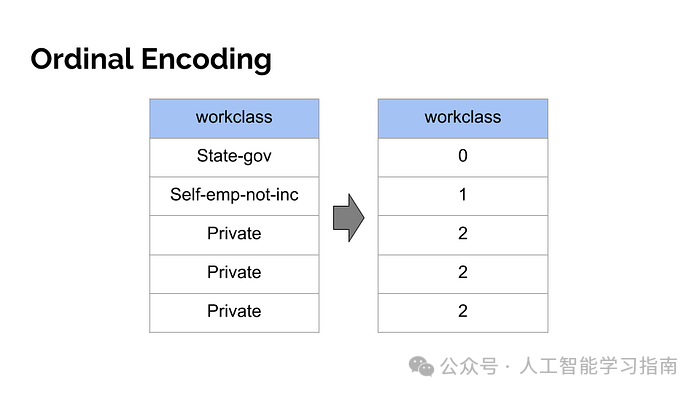
序数型数据是有顺序的数据,比如成绩等级(A+、A、B+、B、C)。
可以使用序数编码(Ordinal Encoding)来转换,对应的Python库是OrdinalEncoder()。
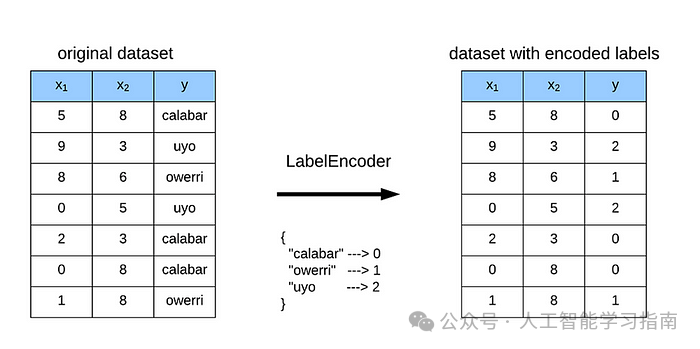
上述两种编码器通常用于解释变量(x),对于预测变量(y),我们应该使用标签编码(Label Encoding),即LabelEncoder(),标签编码是专门为输出变量设计的。
处理异常值
异常值与其他数据不同,可能会让你的模型表现不佳。
异常值是显著不同于数据集中其他数据点的数据,它们会影响我们模型的准确性。
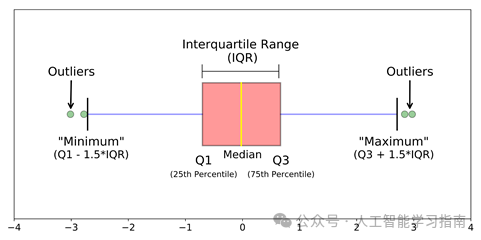
使用IQR(四分位距)进行检测
处理异常值主要有两种方法:
修剪:你可以从数据集中移除异常值。
封顶(Capping):你可以将异常值替换为数据集中其他数据的范围内的值。
如果异常值数量较少,你可以修剪它们。
如果异常值数量较多,你可以使用Capping。
有许多方法可以用来检测和移除异常值,包括z分数、IQR(四分位距)、百分位数和Winsorization等。
特征缩放
在机器学习模型中,并非所有特征都是平等的。
一些特征的范围可能远大于其他特征,从而给它们带来不公平的优势。
特征缩放通过确保所有特征具有相同的尺度来帮助平衡这种差异。
“特征缩放是转换数据集中特征的过程,以便它们具有共同的尺度。”
这有助于防止某些特征在模型中占据主导地位。
特征缩放主要有两种类型:
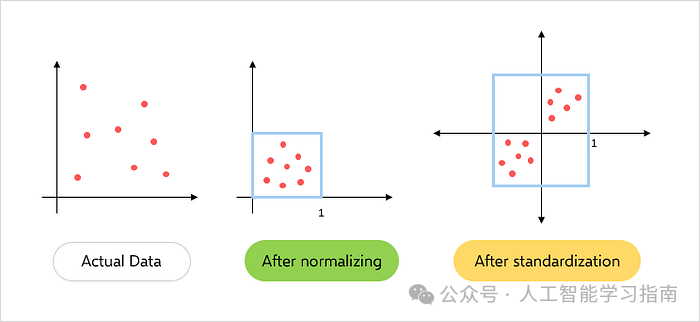
标准化:标准化是从每个特征中减去均值,然后除以标准差的过程。
这确保了每个特征的均值为0,标准差为1,标准化通常用于符合高斯分布的数据,如线性回归和逻辑回归。
归一化:归一化是将特征重新缩放到某个特定范围(如0和1之间)的过程。
这通常用于不符合高斯分布的数据,如决策树和支持向量机。
特征缩放在机器学习过程中是一个重要步骤,通过缩放特征,你可以帮助提高模型性能,并确保所有特征都有平等的机会。
特征构造就像装饰蛋糕,你从一个基本的蛋糕开始,可以通过添加各种装饰来使其更加美味和好看。
例如,你可以添加巧克力碎片、坚果或水果,但要小心不要过头!
过多的装饰会让蛋糕看起来杂乱无章且缺乏吸引力,特征构造也是如此。
如果你向数据集中添加了太多特征,它可能会变得难以解释和分析。
因此,在特征构造时,请记住蛋糕装饰的黄金法则:少即是多。
几个精心挑选的特征可以使你的数据集更加信息丰富和相关,而过多的特征则可能使其变得不那么有用。
“根据现有特征或我们的领域知识开发新特征的过程被称为特征构造。”
通过使特征更加信息丰富和与手头任务相关,这有助于机器学习模型表现更好。
构建特征的方法多种多样,但一些典型的技术包括:
重构现有特征:你可以将现有的特征以新的方式组合起来,创造出新颖有趣的东西。
从现有特征中组合、修改或创建新特征,例如,在泰坦尼克号数据集中,你可以将“sibsp”(兄弟姐妹/配偶数)和“parch”(父母与子女数)两个特征结合,创建出一个名为“家庭”的新特征。
利用领域知识:你可以根据对领域的理解,创造出对当前任务至关重要的新特征。
基于你对领域的了解,创建出对任务有益的新特征。
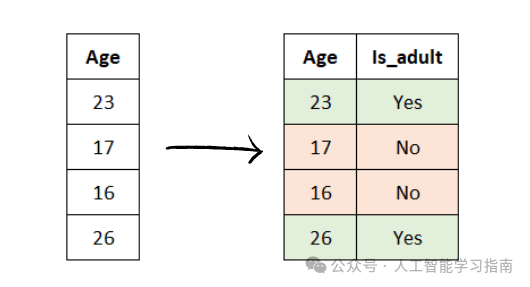
比如,如果你正在开发一个预测客户流失的模型,了解到久未购买商品的客户更可能流失,那么你可以添加一个新特征——“距上次购买月数”。
使用特征选择算法:这些算法能帮助你从数据集中确定最重要的特征,并基于这些特征构建新特征,它就像精选最佳属性来创造强大的新特征!
特征工程是机器学习中至关重要的一步,涉及从原始数据中转换、构建、选择和提取有意义的特征。
就像烘焙美味的蛋糕一样,我们从优质食材(数据)开始,运用我们的专业知识创造新的、相关的特征,以提升机器学习模型的性能。
在本文的第一部分,我们探讨了特征转换的重要性、缺失值处理、类别数据编码、异常值处理以及特征缩放的意义。
同时,我们还讨论了特征构建的艺术,即创造性地结合现有特征和利用领域知识来构建信息丰富的属性。
记住,成功的特征工程的关键在于找到平衡点。
添加过多特征会使数据变得杂乱无章,而精心挑选的几个特征却能显著提升模型性能。
如果大家想更进一步学习机器学习、深度学习、神经网络技术的可以看看以下文章(文章中提到的资料都打包好了,都可以直接添加小助手获取)








