点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

卷积核就是图像处理时,给定输入图像,输入图像中一个小区域中像素加权平均后成为输出图像中的每个对应像素,其中权值由一个函数定义,这个函数称为卷积核。
转载自作者丨计算机视觉与机器学习
在数学上,卷积核的标准定义是两个函数在反转和移位后的乘积的积分:
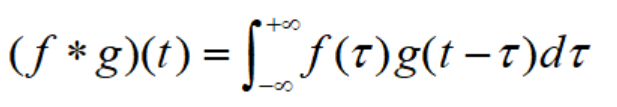
其中,函数g一般称为过滤器(filters),函数f指的是信号/图像。在卷积神经网络里,卷积核其实就是一个过滤器,但在深度学习里,它不做反转,而是直接执行逐元素的乘法和加法,我们把这个又称为互相关,在深度学习里称为卷积。
那为什么在图像处理上,需要进行卷积处理呢。实际上是借鉴于科学家的研究结果——上个世纪科学家就发现,视觉皮层的很多神经元都有一个小的局部感受野,神经元只对有限区域的感受野上的刺激物做出反应。不同的感受野可以重叠,他们共同铺满整个视野。并且发现,一些神经元仅仅对横线有反应,有一些神经元对其他方向的线条有反应,有些神经元的感受野比较大。因此,高级别的神经元的刺激是源于相邻低级别神经元的反应。
利用这个观点,经过不断的努力,逐渐发展成了现在的卷积神经网络。通过卷积核提取图像的局部特征,生成一个个神经元,再经过深层的连接,就构建出了卷积神经网络。
我们已经知道,一个卷积核一般包括核大小(Kernel Size)、步长(Stride)以及填充步数(Padding),我们逐一解释下。
卷积核大小:卷积核定义了卷积的大小范围,在网络中代表感受野的大小,二维卷积核最常见的就是 3*3 的卷积核。一般情况下,卷积核越大,感受野越大,看到的图片信息越多,所获得的全局特征越好。但大的卷积核会导致计算量的暴增,计算性能也会降低。
步长:卷积核的步长代表提取的精度, 步长定义了当卷积核在图像上面进行卷积操作的时候,每次卷积跨越的长度。对于size为2的卷积核,如果step为1,那么相邻步感受野之间就会有重复区域;如果step为2,那么相邻感受野不会重复,也不会有覆盖不到的地方;如果step为3,那么相邻步感受野之间会有一道大小为1颗像素的缝隙,从某种程度来说,这样就遗漏了原图的信息。
填充:卷积核与图像尺寸不匹配,会造成了卷积后的图片和卷积前的图片尺寸不一致,为了避免这种情况,需要先对原始图片做边界填充处理。
所谓的通道数,可以理解为有多少张二维矩阵图。
对于具有1个通道的图像,下图演示了卷积的运算形式:
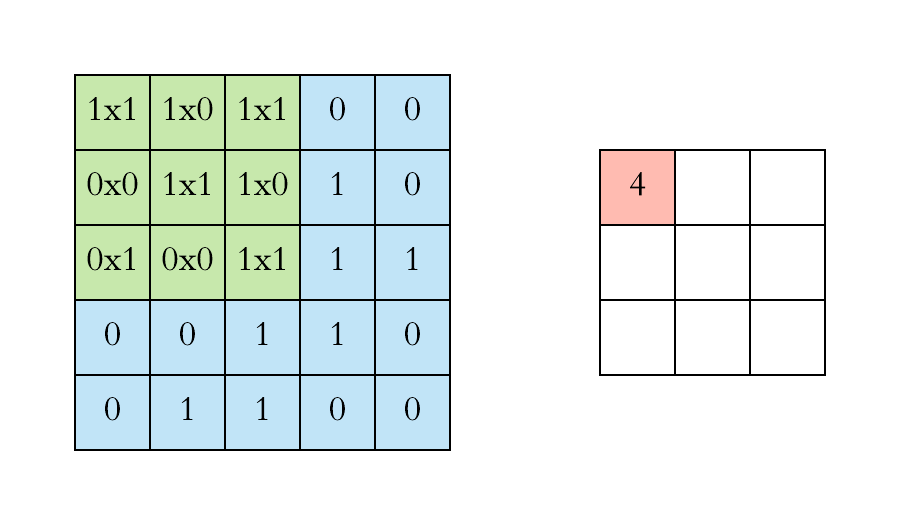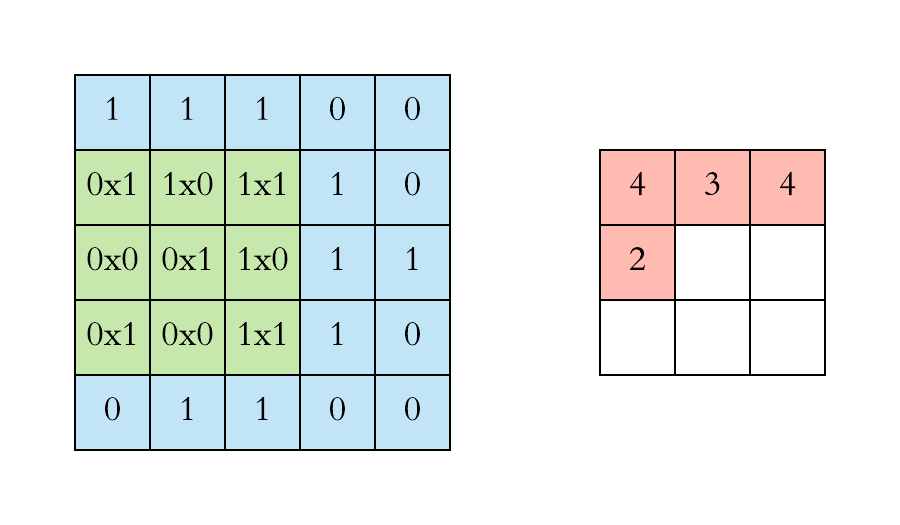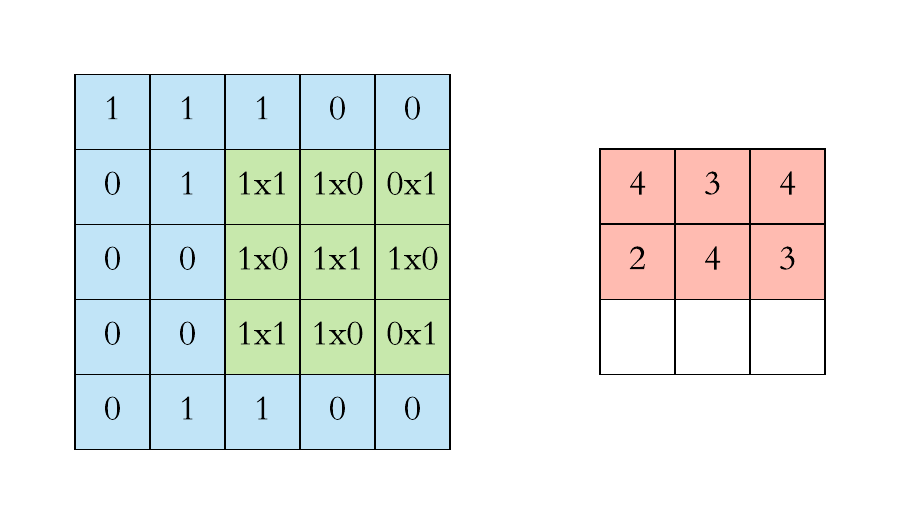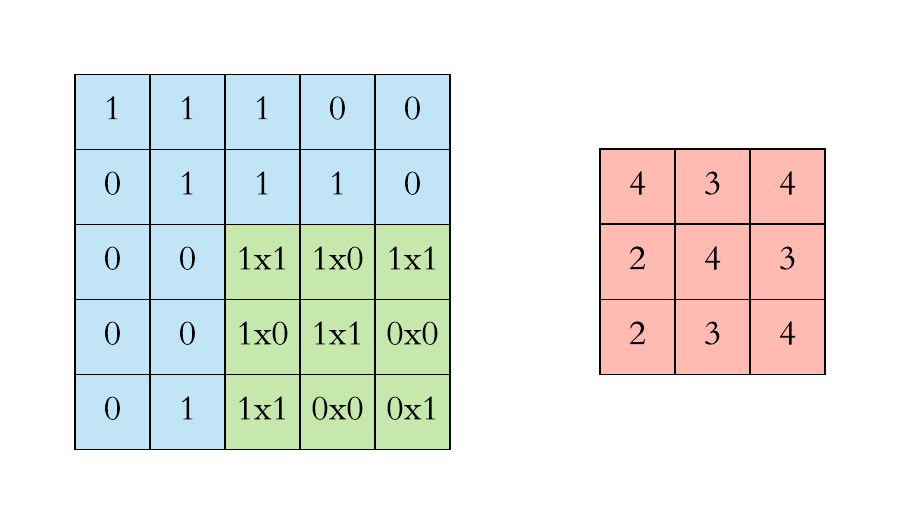
这里的filter是一个3*3矩阵,步长是1,填充为0。filter在输入数据中滑动。在每个位置,它都在进行逐元素的乘法和加法。每个滑动位置以一个数字结尾,最终输出为3 x 3矩阵。
多通道也很容易理解,最典型的就是处理彩色图片,一般有三个通道(RGB):

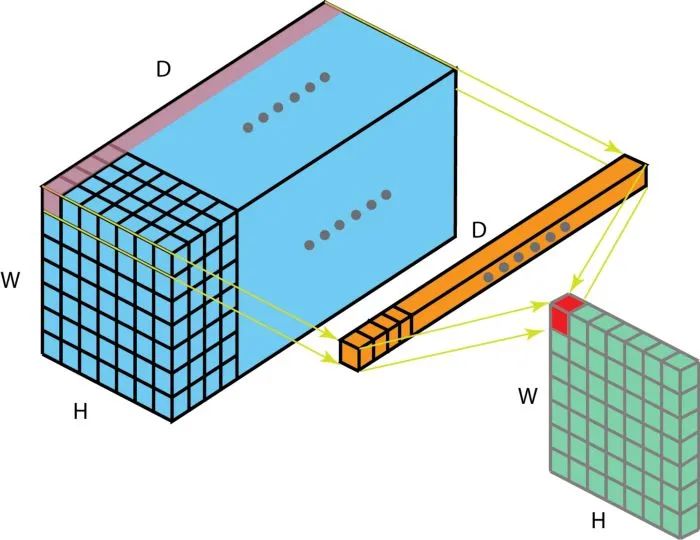
实际上,一个filter也可以包含多个矩阵,也即kernels,比如一个包含三个kernels的filter,对于输入是三个通道的图像:
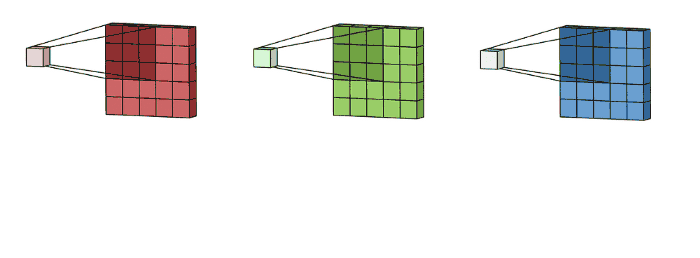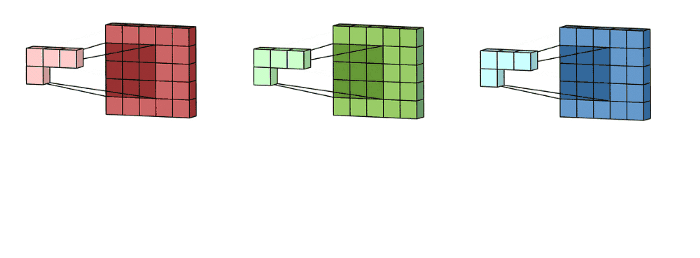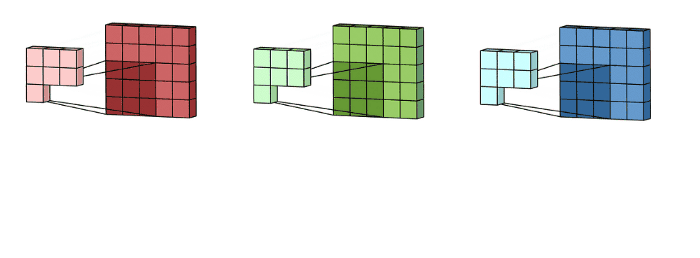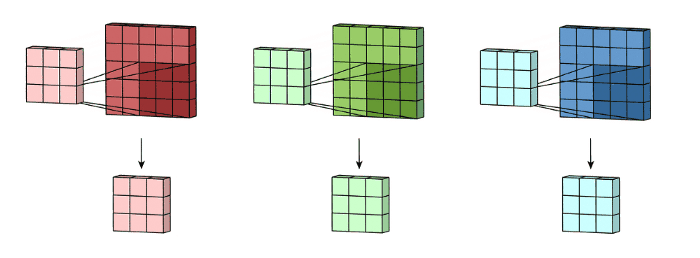
这里输入层是一个5 x 5 x 3矩阵,有3个通道,filters是3 x 3 x 3矩阵。首先,filters中的每个kernels分别应用于输入层中的三个通道,执行三次卷积,产生3个尺寸为3×3的通道。
然后,将这三个通道相加(逐个元素相加)以形成一个单个通道(3 x 3 x 1),该通道是使用filters(3 x 3 x 3矩阵)对输入层(5 x 5 x 3矩阵)进行卷积的结果:

由此,我们引出卷积核的另外一个参数——输入输出通道数。
输入和输出通道数:卷积核的输入通道数由输入矩阵的通道数所决定(输入深度);输出矩阵的通道数由卷积核的输出通道数(卷积层深度,即多少个filters)所决定。
上面的多通道过程解释的详细点:
假设输入层有 Din 个通道,而想让输出层的通道数量变成 Dout,我们需要做的仅仅是将 Dout个filters应用到输入层中。每一个filters都有Din个卷积核,都提供一个输出通道。在应用Dout个filters后,Dout个通道可以共同组成一个输出层。
我们把上面的卷积过程称为2D-卷积——通过使用Dout个filters,将深度为Din的层映射为另一个深度为Dout的层。
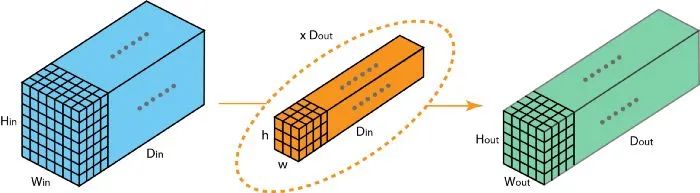
进一步,我们给出2D-卷积的公式:
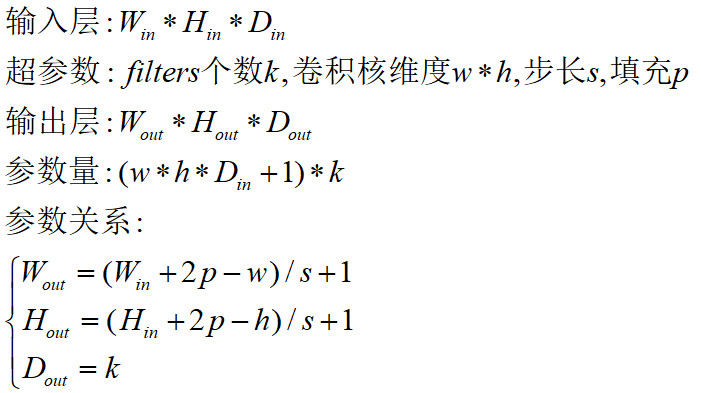
特别的,对于卷积核,如果w=h=1,那么就退化为1*1卷积核,它具有以下三个优点:
降维以实现高效计算
高效的低维嵌入特征池
卷积后再次应用非线性
下图是一个例子:
在一个维度为 H x W x D 的输入层上经过大小为 1 x 1 x D 的filters的 1 x 1 卷积,输出通道的维度为 H x W x 1。如果我们执行 N 次这样的 1 x 1 卷积,然后将这些结果结合起来,我们能得到一个维度为 H x W x N 的输出层。
通过将2D-卷积的推广,在3D-卷积定义为filters的深度小于输入层的深度(即卷积核的个数小于输入层通道数)
因此,3D-filters需要在三个维度上滑动(输入层的长、宽、高)。在filters上滑动的每个位置执行一次卷积操作,得到一个数值。当filters滑过整个3D空间,输出的结构也是3D的:
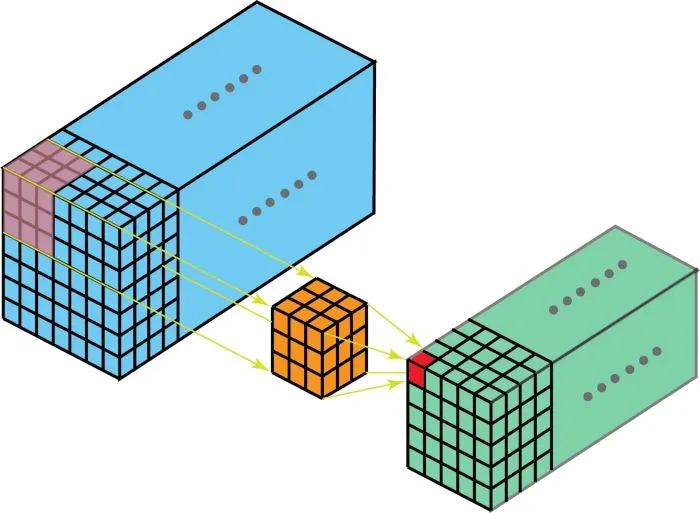
2D-卷积和3D-卷积的主要区别为filters滑动的空间维度,3D-卷积的优势在于描述3D空间中的对象关系,它的计算过程是:
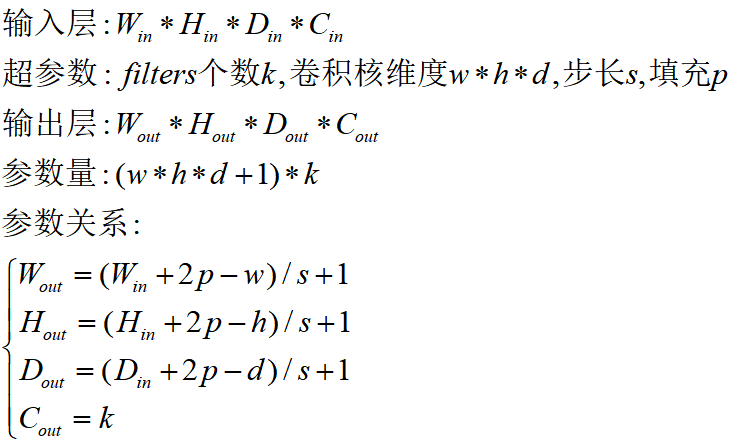
除了普通的卷积操作外,也有一些变种,本文我们先介绍概念,对于每一种卷积的作用,我们会再出文章介绍。
一般正常卷积称为下采样,相反方向的转换称为上采样。转置卷积是相对正常卷积的相反操作,但它只恢复尺寸,因为卷积是一个不可逆操作。下面通过一个例子来说明转置卷积的具体操作过程。
假设一个3*3的卷积核,其输入矩阵是4*4的形状,经过步长为1,填充为0的卷积结果为:

转置卷积过程为,第一步,将卷积核矩阵重新排列为4*16形状:

第二步,将卷积结果重新排列为1维行向量:
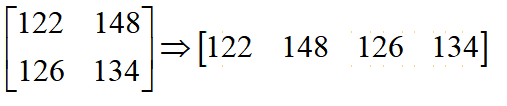
第三步,将重排矩阵转置后与行向量转置后相乘,得到16个元素的1维列向量:
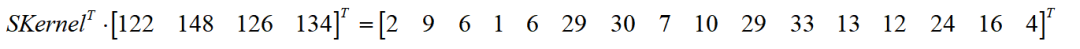
第四步,对列向量进行重排为4*4的矩阵,得到最终结果:
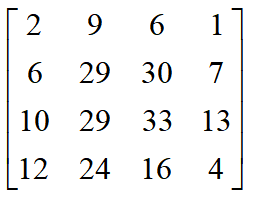
这样就通过转置卷积将2x2的矩阵反卷为一个4x4的矩阵,但从结果也可以看出反卷积的结果与原始输入信号不同。只是保留了位置信息,以及得到了想要的形状。
空洞卷积也叫扩张卷积,指的是在正常的卷积核的点之间插入空洞。它是相对正常的离散卷积而言的,对于步长为2,填充为1的正常卷积如下图:
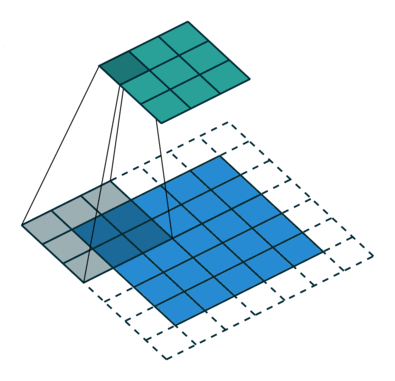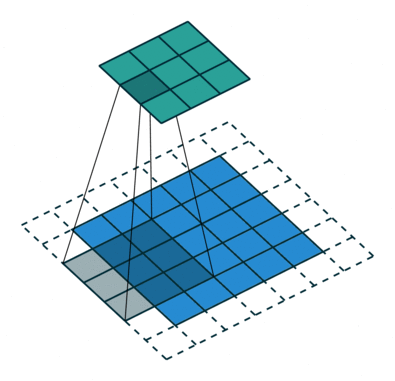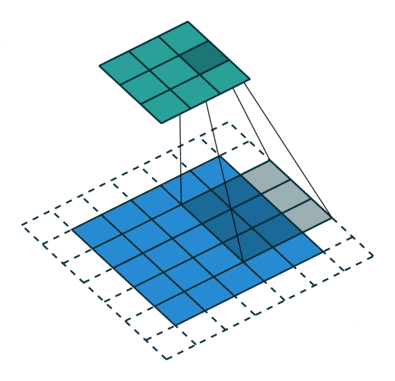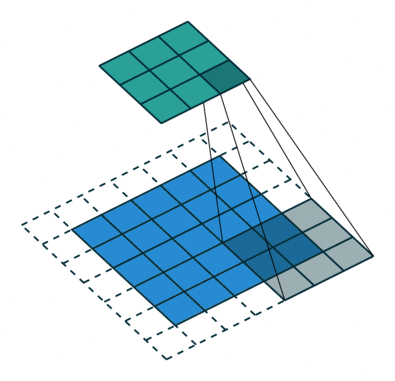
插入空洞后,卷积过程变为:
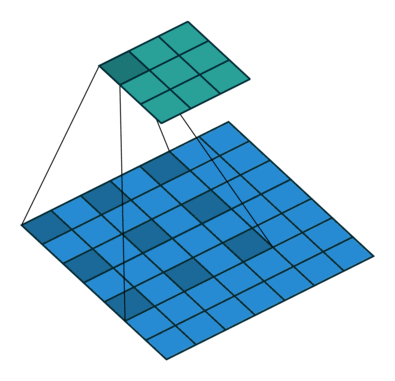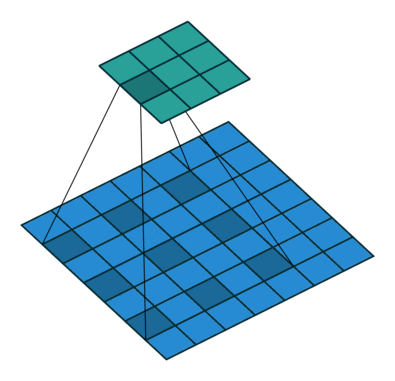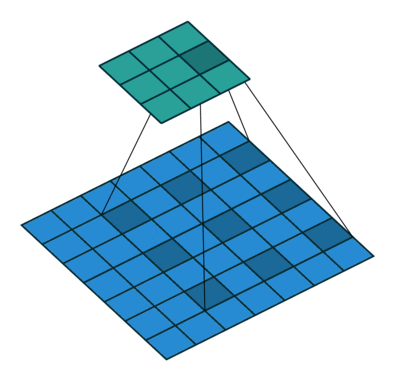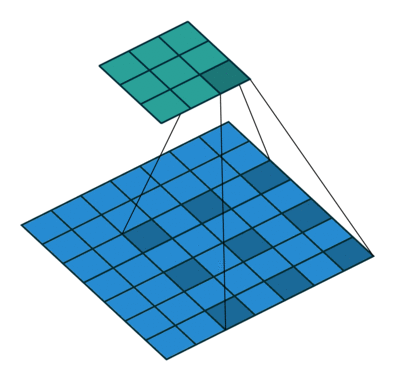
空洞卷积通过空洞率(dilation_rate)控制,上图是空洞率为2的情况。
可分离卷积分为空间可分离卷积和深度可分离卷积。
空间可分离卷积有个前提条件,就是卷积核可以表示为两个向量的乘积:
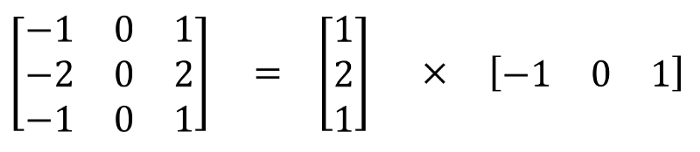
这样,
3x1的kennel首先与图像进行卷积,然后应用1x3的kennel。在执行相同操作时,可以减少参数数量。所以,空间可分离卷积节省了成本,但是一般不使用它做训练,而深度可分离卷积是更常见的形式。
深度可分离卷积包括两个步骤:深度卷积和1*1卷积.下面是一个深度可分离卷积的例子:
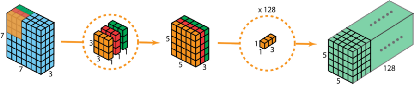
对于形状是7*7*3的输入层,有3个通道。
第一步在输入层上应用深度卷积。我们在2D-卷积中分别使用 3 个卷积核(每个filter的大小为3*3*1),每个卷积核仅对输入层的 1 个通道做卷积,这样的卷积每次都得到大小为5*5*1 的映射,之后再将这些映射堆叠在一起创建一个 5*5*3 的特征图:
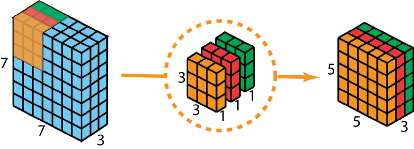
第二步进行扩大深度。我们用大小为1*1*3的卷积核做1x1卷积。每个卷积核对5*5*3输入图像做卷积后都得到一个大小为5*5*1的特征图,重复做128次1*1卷积,就得到了最终的结果:
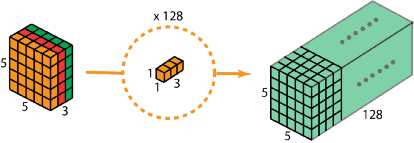
从本质上说,深度可分离卷积就是3D卷积kernels的分解(在深度上的分解),而空间可分离卷积就是2D卷积kernels的分解(在WH上的分解)
分组卷积,顾名思义,filters被拆分为不同的组,每一个组都负责具有一定深度的传统 2D 卷积的工作。
比如下面这张图就展示了分组卷积的原理:
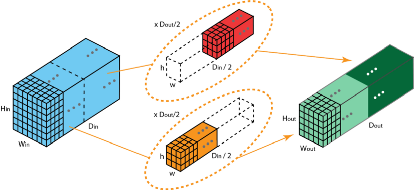
上图表示的是被拆分为 2 个filters组的分组卷积。在每一组中,其深度仅为传统2D-卷积的一半——Din/2,而每个filters组都包含Dout/2个filters。第一个filters组(红色)对输入层的前半部分做卷积([:,:,0:Din/2]),第二个filters组(蓝色)对输入层的后半部分做卷积([:,:,Din/2:Din])。最终,每个filters组都输出了Dout/2个通道。整体上,两个组输出的通道数为Dout ,之后,我们再将这些通道堆叠到输出层.
分组卷积有三个优点:有效的训练;模型参数随着filters组数的增加而减少;可以提供比标准2D卷积更好的模型。
参考资料:
https://www.zhihu.com/question/30888762
https://www.jianshu.com/p/1c9fe3b4dc55
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~












