本文是一份从0到100的指南,旨在帮助你在深度学习中开始视频处理。包括图像处理、视频格式、重新编码、通过HTTP、WebSockets和WebRTC进行流媒体传输。
近来,整个机器学习领域似乎被大型语言模型(LLM)和检索增强生成(RAG)所掩盖。虽然许多用例可以从这些新的基础模型中受益,但在非文本数据方面仍存在差距。我常把当前的机器学习阶段比作汽车工业中从燃油车向电动车的转变。燃油车已经有完善的基础设施(如汽车服务、加油站等),而电动车的充电站和专用服务地点尚未成熟——但它们正在追赶。
这个比较的重点在于:基于变压器的模型在许多用例中已经证明了它们的实用性,但在视觉任务上,它们仍需要时间来超越已有且成熟的系统。然而,今天的重点是工程——特别是如何解决使用机器学习的嵌入式视频流应用中的延迟问题,因为视频读取/处理/流媒体是视觉系统的核心。
目录
什么是视频处理?
1.1 视频编码器
1.2 比特率
1.3 分辨率
1.4 帧率
1.5 视频容器
1.6 视频重新编码的工作原理
常见的视觉库
2.1 OpenCV
2.2 Albumentations
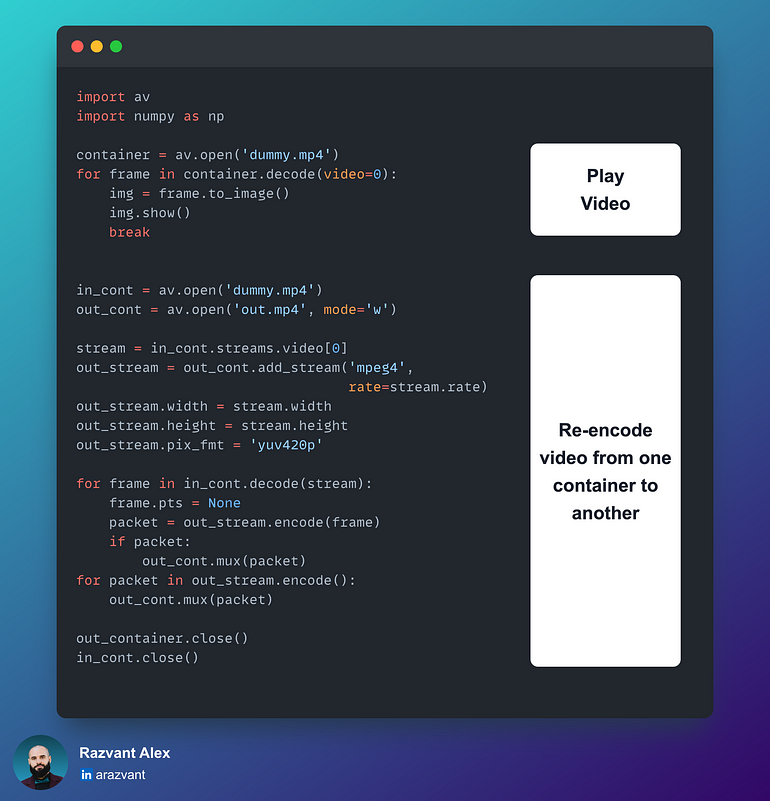
2.3 PyAV(FFmpeg 绑定)
视频流方法
3.1 使用HTTP流
3.2 使用WebSockets流
3.3 使用WebRTC流
结论
什么是视频处理?
视频处理是指一组用于操作和分析视频流的技术和方法。我们来看看描述视频处理时必须了解的关键组件:
1. 编码器
编码器是一种硬件或软件过程,用于压缩(编码)和解压缩(解码)大量视频和音频数据。它们对于减少视频/音频文件大小和流媒体至关重要,因为一个原始视频文件可能占用非常大的空间。例如,一个60秒、1920x1080、30 FPS的视频文件的原始大小计算如下:
W = Width (pixels)H = Height (pixels)FPS = Frame Rate (frames/s)BIT = Bit Depth (bits per pixel)DUR = Duration (video length in seconds)
File Size (bytes) = W x H × FPS x BIT x DURFile Size (bytes) = 1920 x 1080 x 30 x (24 / 8) x 60 = 11197440000 (bytes)File Size (mbytes) = 11197440000 / (1024 ** 2) = 10678,71 (mbytes)File Size (gbytes) = 10678,71 / 1024 = 10,42 (gbytes)
如果要存储和流传输视频,YouTube只能存储和流传输Pewdiepie的频道——由于存储和网络限制,不会有其他内容。
常用的视频压缩编码器包括:
H.264(AVC):高效,兼顾质量和相对较小的文件大小,兼容几乎所有视频播放器和流媒体服务。
H.265(HEVC):在相同的视频质量水平下提供更好的数据压缩。
VP9:由Google开发,主要用于YouTube等平台的高清流媒体。
2. 比特率
指在给定时间内处理的数据量,通常以每秒比特数(bps)来衡量。在视频中,比特率至关重要,因为它直接影响视频的质量和大小:
3. 分辨率
表示每个维度可以显示的像素数。常见的分辨率有HD(1280x720)、FHD(1920x1080)和4K(3840x2160)。
4. 帧率
描述每秒显示的单独图像数量。我还记得在一台破旧的电脑上玩GTA4时得到的9FPS。
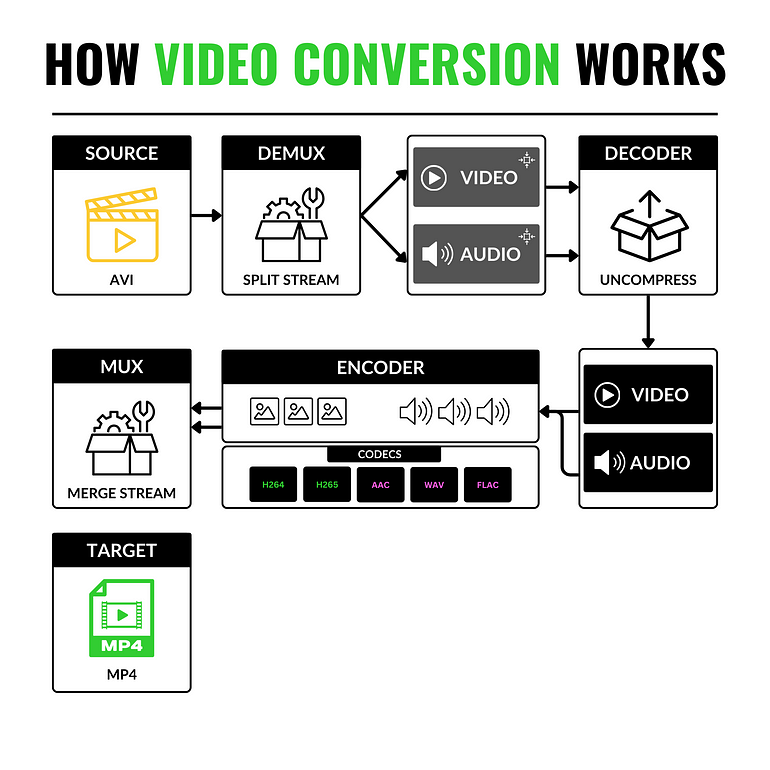
5. 容器格式
如MP4和AVI,封装视频、音频和元数据,管理数据的存储和交换,而不影响质量。由于视频容器的结构,它使得从一种视频格式转换为另一种视频格式变得简单。
具体术语包括:
源(SOURCE):格式A的视频。
解复用器(DEMUX):将视频流与音频流分离的组件。
解码器(DECODER):将两个流解压缩为原始格式。
编码器(ENCODER):使用新的视频和音频编码器重新压缩原始流。
复用器(MUX):重新链接并同步视频流和音频流。
目标(TARGET):将新数据流(视频+音频)转储到新容器中。
使用Python进行视频处理的常见库
在计算机视觉项目中,图像处理和操作是必不可少的。从数据准备、标注、质量保证、增强和模型训练,到模型部署后所需的预处理/后处理步骤,以下是计算机视觉工程师必须了解/使用的库和工具:
OpenCV

Albumentations
用于数据集增强的快速高效库,主要增强实现为GPU内核。
PyAV
+----------------+-----------------+--------------------------------+| Feature | YUV420 | RGB |+----------------+-----------------+--------------------------------+| | Y, U, V | Red, Green, Blue || Channels | (Luminance and | || | two chrominance)| |+----------------+-----------------+--------------------------------+| Storage | Less storage | More storage required due to || Efficiency | due to | for all three color channels. || | subsampling | |+----------------+-----------------+--------------------------------+| Bandwidth | Highly | Requires more bandwidth, all || Usage | efficient for | channels are fully sampled. || | transmission | |+----------------+-----------------+--------------------------------+| Complexity | Higher | Lower |+----------------+-----------------+--------------------------------+| Suitability | Better | Better for image editing || | for video | Universal compatibility || | compression and | || | transmission | | |+----------------+-----------------+--------------------------------+
视频流方法
在需要实时流媒体的生产用例中,计算机视觉工程师经常需要开发优化的低计算视频处理工作流程,尤其是在部署用例还包括目标检测或分割模型并打算在边缘设备上运行时。视频解码消耗大量CPU资源,部署在边缘时,由于硬件资源有限,应尽可能利用已部署系统,同时保持资源和能源足迹较低。
在大多数计算机视觉项目中,处理是在边缘完成的,要么是在可以访问RTSP摄像头的服务器上,要么是在本地转储帧或通过以太网流传输的设备上。例如,为了解决工厂生产线中检测不合格产品的问题,可以训练和部署使用实时视频流和分割模型的系统来识别风险区域。

另一个例子是通过目标检测、深度预测和语义分割来识别商店货架补货时间的问题,实时提醒员工补货。

本文将首先介绍使用Python实现的常见视频流方法,以解决从API到客户端应用实时流传输帧的问题。我们将使用FastAPI作为我们的流媒体API,并使用一个基本的React应用程序作为客户端来演示这个概念。
我们将介绍三种方法:HTTP、WebSockets和WebRTC。对于每种方法,我们将迭代代码,包括FastAPI和React,并说明该方法的最佳适用场景。
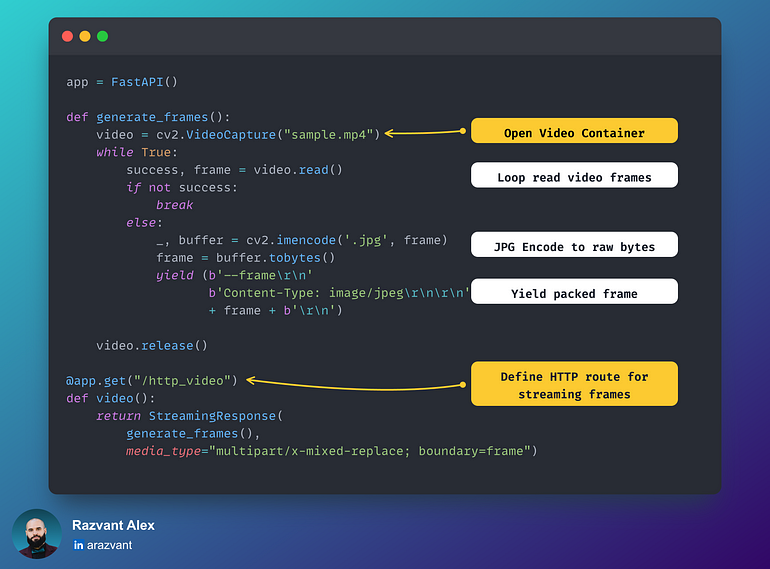
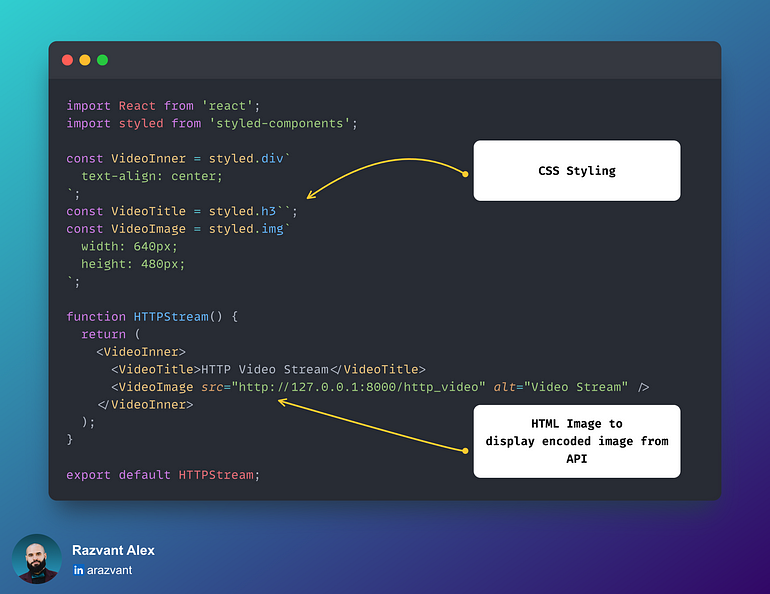
使用HTTP流媒体
这是一种快速且实用的方法,是验证将视频流传输到Web应用程序的最直接的方法。对于小规模用例,这可能会奏效,但一旦应用程序扩展并需要支持许多设备或工作流流,由HTTP头添加的延迟、开销和带宽就开始带来挑战。
使用WebSockets流媒体
与HTTP相比,Websockets提供了一种更高效的方法,因为它们允许更低的延迟、实时交互和更优化的数据传输方式。与HTTP相比,HTTP是无状态的,意味着你触发端点并得到响应,在套接字上——一旦握手完成,只要连接处于Open状态,数据就会流式传输。这导致了管理和“存储”套接字状态的需求,使它们成为有状态的。
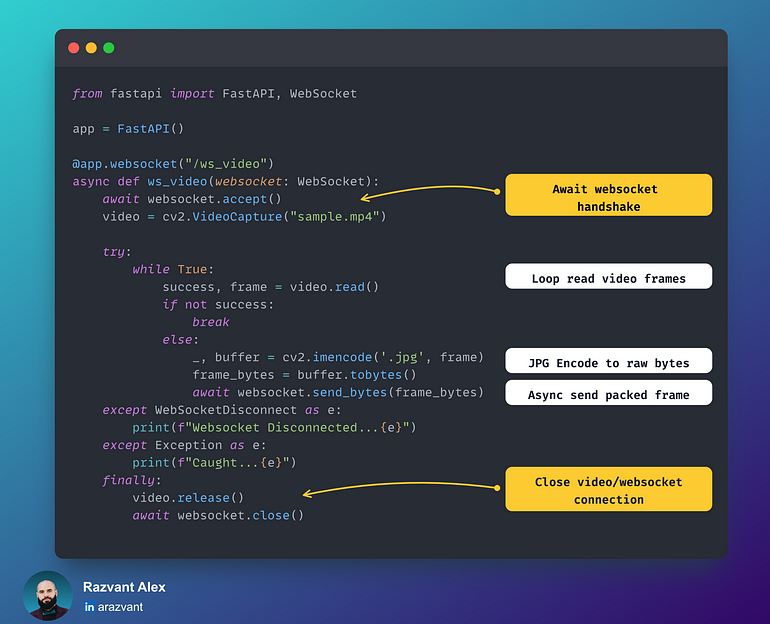
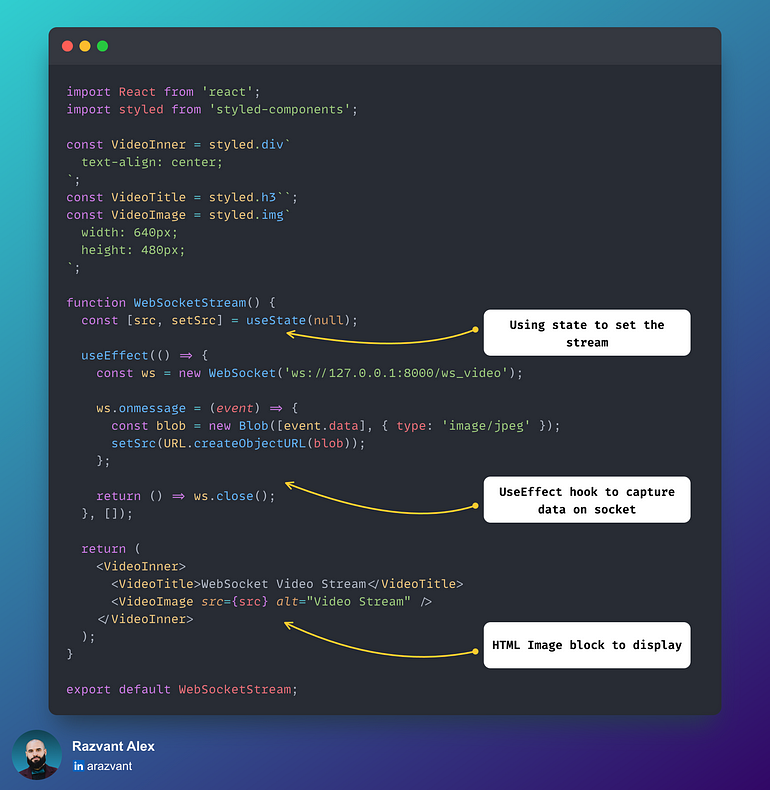
使用WebRTC流媒体
WebRTC(Web实时通信)是一种技术标准,它允许在不需要复杂的服务器端实现的情况下,通过P2P(点对点)连接进行实时通信。与HTTP和Websockets相比,这是一个更复杂的协议,它专门处理视频/音频流式传输。
无论是Zoom通话、Facetime、Teams还是Google会议——都是RTC在起作用!以下是它的主要组件:
数据通道:允许不同对等方之间任意交换数据,无论是浏览器到浏览器还是API到客户端。
加密:所有通信、音频和视频都经过加密,确保通信安全。
SDP(会话描述协议):在WebRTC握手期间,两个对等方交换SDP提议和答复。简而言之,SDP描述了对等方的媒体能力,以便他们可以收集有关会话的信息。SDP提议描述了对等方请求的媒体类型,而SDP答复确认已收到提议,并相应地交换其媒体配置。
信令:实现提议-响应通信的方法(套接字,REST API)。在我们的用例中,我们使用POST端点来打开通道。
随着我们迭代了流式传输方法,让我们看看它们的实际效果。完整代码可以参考:
https://github.com/decodingml/articles-code/tree/main/articles/computer_vision,
安装README文件中描述的所需软件包,请运行以下命令:
当你启动了FastAPI后端和ReactWeb前端,可以转到浏览器中的localhost:3000并检查结果。
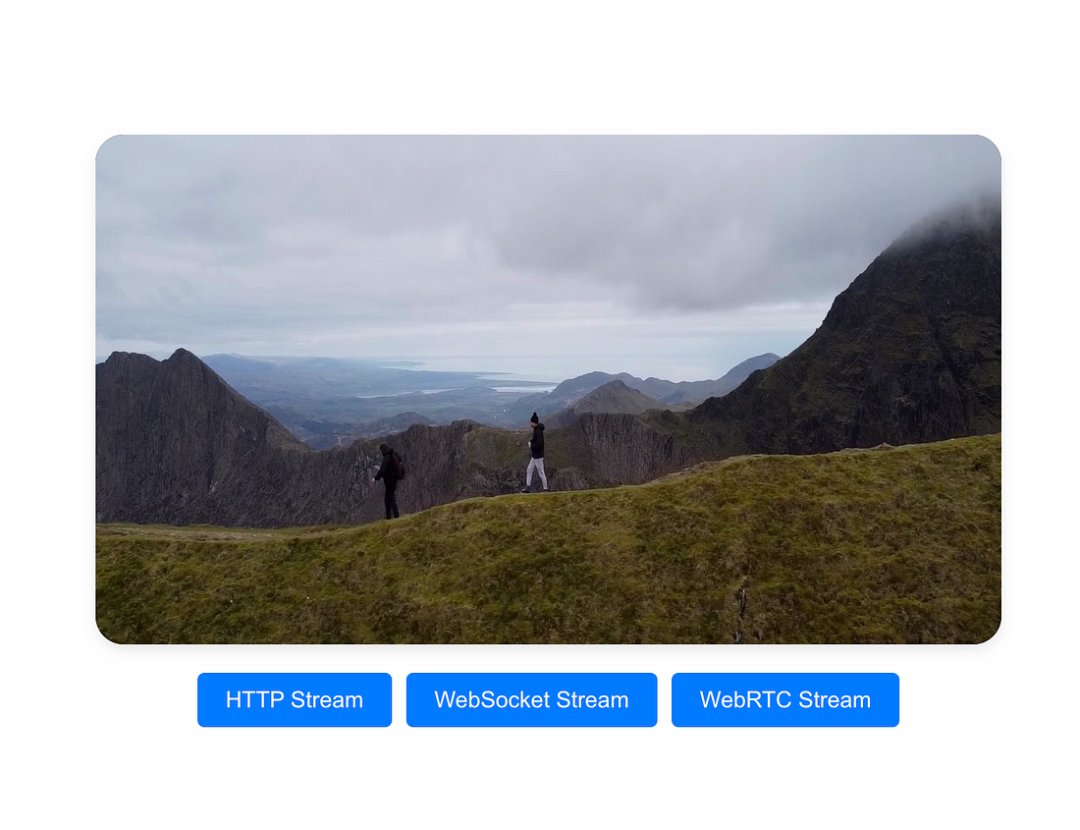
结论
在本文中,我们介绍了视频格式的结构及其关键组件,以理解视频的工作原理。我们还介绍了一些广为人知的库,使得处理视频/图像数据变得容易。最后,我们逐步介绍了三种视频流方法:HTTP、WebSockets和WebRTC。








