论文推荐:基于机器学习算法的合成控制法评估论文
1、合成控制法回顾
合成控制法被称为过去15年政策评估文献中最重要的创新--综合控制法
 图片
图片 图片
图片 图片
图片 图片
图片 图片
图片 图片
图片 图片
图片 图片
图片 图片
图片
 图片
图片 图片
图片2、基于机器学习算法的合成控制法
来源:中国知网2024年7月5日网络首发,数量经济技术经济研究,大小城市合并与行政边界地区经济增长:基于机器学习算法的合成控制评估
据悉这是中文期刊上 将机器学习与合成控制法相结合的政策评估实证应用论文。
以“菜芜并入济南"为自然实验,利用卫星灯光数据和基于机器学习算法的合成控制法,评估了大小两个城市合并对原边界地区经济增长产生的影响。
传统合成控制法不足如下:
传统SCM会带来内插偏差(interpolation bias)的问题,即因预测能力不足而无法很好地复制政策干预前的结果变量
过拟合(overfiting)的问题,会导致无法判断干预后产生的结果是否是因为过度拟合了控制组
因此该文主要借鉴Doudchenko和Imbens(2016)等提出的基于机器学习进行合成控制的方法。该方法放松了权重非负、权重和为1、不能有截距项等假定,使得基于机器学习的合成控制法可以得到更灵活目更精确的政策发生前合成路径。
选取2012年4月~2018年12月数据作为训练集,2019年1月~2021年12月作为测试集
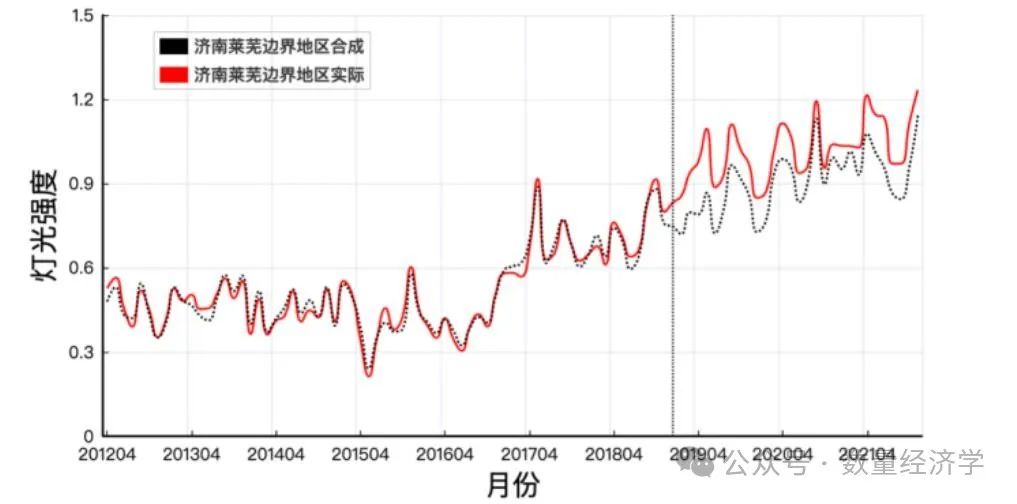
结果表明:
- 如图所示,红色实线与黑色点线在2019年1月政策实施前较为接近,说明机器学习合成控制法较好地合成了处理组的趋势
- 而在2019年1月政策实施后,两条线发生了一定偏离,而这部分偏离,即红色实线与黑色点线差距,即为济南莱芜合并对其原边界地区经济增长的政策效应。
稳健性
更换城市边界地区度量方式、更换对照组样本,以及采用其他机,器学习算法等来检验本文实证结论的稳健性。
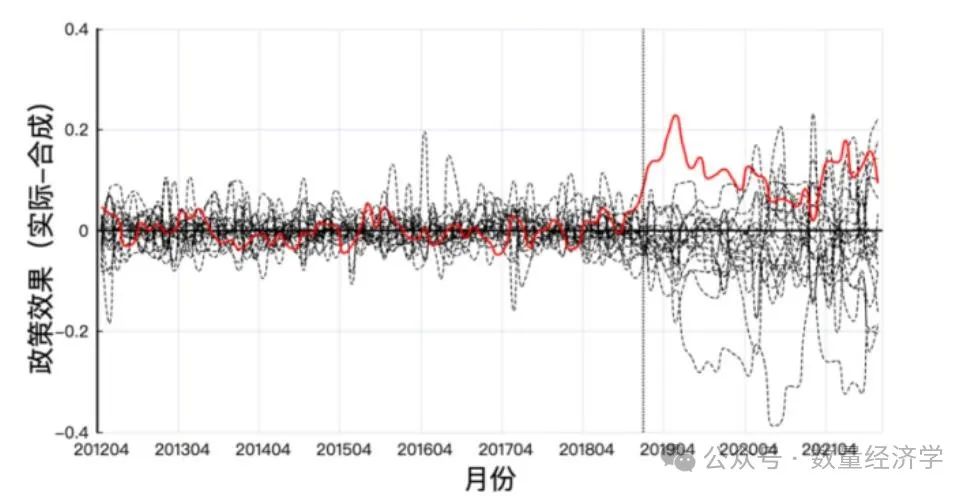
安慰剂检验
合成控制法中安慰剂检验方法,在合成控制法文献中又被称为置换检验方法(Permutation test),常被用于检验根据合成控制法得到的政策效果是否在统计上显著
在进行安慰剂检验的过程中,如果控制组中RMSPE高于处理组RMSPE的两倍,则可以事前合成效果差,应当在可视化呈现时剔除这些没有较好合成的地区,仅保留政策冲击前RMSPE小于两倍处理组的安慰剂结果。
更多内容,请阅读原文!










