
作者 | 番茄爱鸡蛋
整理 | NewBeeNLP
https://zhuanlan.zhihu.com/p/688913185
大家好,这里是 NewBeeNLP。今天看看 Meta 关于深度学习推荐系统 Scaling Law 的研究。
零、论文信息
- 论文题目:Wukong: Towards a Scaling Law for Large-Scale Recommendation
- 论文链接:https://arxiv.org/abs/2403.02545
一、整体总结
本篇剑指一个问题,随着推荐系统Dense层(即除了embedding table以外的计算层)的参数量不断增加,推荐的指标会不会逐步增大呢。
本文给出了肯定的答案,在 一个拥有1460亿条目、720个特征的内部数据集 上逐步扩大Dense层的参数, 本文提出的模型WuKong的训练计算量从 1GFLOP/example扩展到100 GFLOP/example(100 GFLOP/example相当于GPT3的计算规模),Dense层参数规模从0.74B到17B,对应的性能指标展现出了不断提升的趋势。
本文整体贡献:
- 提出了一个新的特征交叉结构,名为Wukong,在离线数据集上取得了最好结果
- 汇报了推荐系统中的Scale Law, 在计算复杂度上,Wokong模型维持了大约两个数量级的增长稳定性,训练计算量翻两番,对应的性能就有0.1%的提升。
指的指出的是,Meta最近有不同的组在一个生成式推荐模型上也汇报了Scale Law这个现象,具体参看如下提问:
- 如何评价Meta最新的推荐算法论文:统一的生成式推荐第一次打败了分层架构的深度推荐系统?https://www.zhihu.com/question/646766849
二、Wukong和Scale策略
2.1 特征模块
特征采取了分块设计:每个特征的维度采用一个 更小的子维度作为基本单元 (例如一般采用32维度,可以分为4个8维度的基本单元),然后可以给重要的特征采用更多的基本单元,从而获得更长的特征维度。
变长特征是可以带来一些效果的,也可以训练的时候先分块全长训练,之后采用featuredropout删减对应的单元。
再特征交叉的时候,每一个单元会作为独立的特征做参与交叉(保持单元长度一致就是为了方便做特征交叉)。
2.2 Wukong
整体而言,Wukong是一个比较常见的CTR模型类别,采用了是先利用Wukong Layer进行特征交叉,之后再利用MLP生成预测结果的结构。
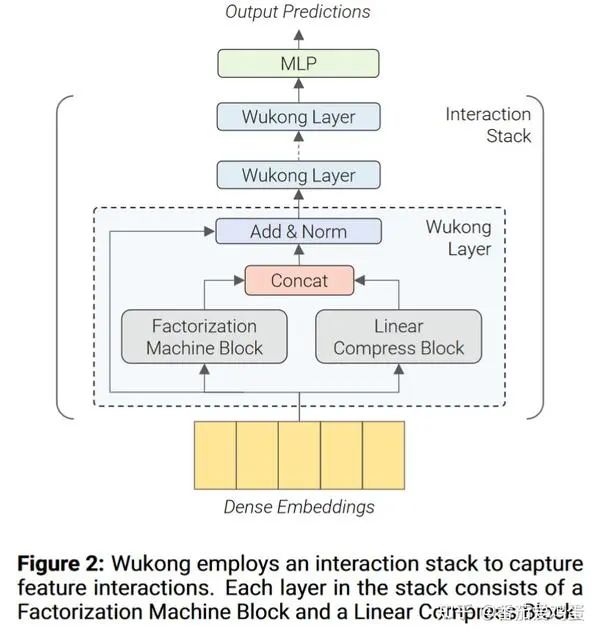
如上图,每一个 Wukong Layer包含一个分解机模块(Factorization Machine Block, 简称FMB)和一个线性压缩模块(Linear Compress Block,简称LCB),最后将两个模块的output拼接,添加残差链接和LayerNorm。
假设某一个样本的特征矩阵是 具体Wukong Layer计算公式如下
其中FMB如下:
FM是一个特征交叉模块,文中采用了类似DCNv2的构造 来捕获高阶交叉。其中 , 即先压缩特征个数到 ,再计算交叉结果。最后FMB输出一个 的特征矩阵。
LCB如下
其中 是一个权重矩阵, 是一个超参数来指定输出的压缩后的embedding个数, 是第i层的embedding个数。
2.3 Scale 对应的参数
Wukong主要调节以下参数进行Scale。
- MLP:FMB 的 MLP 中的层数和 FC 大小
论文中提及,他们首先放大 l ,接着才放大别的参数。
三、实验结果
3.1 公开数据集离线对比
这里直接简略看一下对比结果,详细的设定可以直接参看论文。
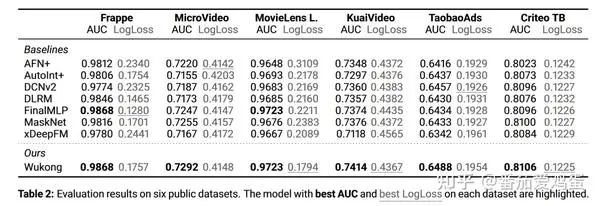
可以看到Wukong再这些数据集上效果也是不错的。
3.2 在Meta的内部数据集上的实验
这个就是这篇论文的核心内容了。我们详细关注下他的设置内容
3.2.1 数据集和实验设置
数据集:该数据集总共包含 146B 个条目,有 720 个不同的特征。每个特征描述了项目或用户的属性。有两个与此数据集相关的任务:(Task1)预测用户是否对某个项目表现出兴趣(例如,单击)和(Task2)是否发生转换(例如,喜欢、关注)。
训练设置: 所有embedding长度设置为160,不随着Dense层的Scale而增大维度 。训练dense层用Adam,训练embedding table用 Rowwise Adagrad。 Batch Size 设置为 262,144,每个训练实例都会利用128或者256个H100 GPU 。
- GFLOP/example:每个示例的千兆浮点运算(Giga Floating Point Operations per example)
- PF-days:PF-days 训练计算总量相当于运行一台以 1 PetaFLOP/s 运行的机器 1 天。
- #Params:模型大小通过模型中参数的数量来衡量。embedding table大小固定为 627B 参数。
- Relative LogLoss:相对于固定基线的 LogLoss 改进。 在此数据集上0.02% 的相对 LogLoss 改进被认为是显著 。
3.2.2 实验结果
根据附录,每一个Wukong样本点的参数设置如下:
根据计算量绘制性能提升图如下
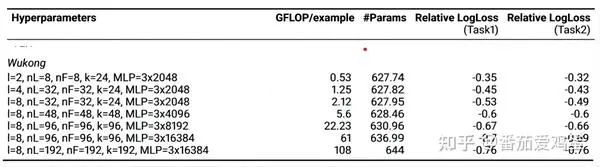
可以看到,随着训练计算量的膨胀,logloss稳定下降。根据论文的结论, Wukong 在模型复杂性上保持了两个数量级的缩放法则——大约相当于复杂性每翻两番就提高 0.1%。
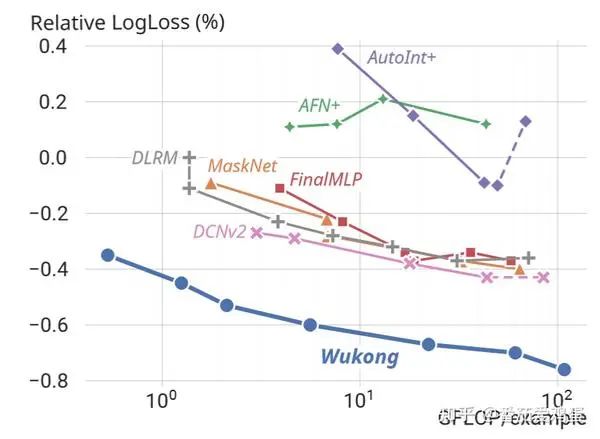
作者也根据模型参数量绘制了类似的结果
那么究竟给哪些模块加参数加计算是比较有效果的呢,下图也给出了一定的解答

可以观察到 n_F 和 l 这些与特征交叉相关的参数提升比较显著。k,n_F,n_L 的组合效果也不错,提升MLP的参数也有效果,但是单独提升 n_L 没什么效果。(感觉大部分与特征交叉还有最后MLP相关的都是比较有效果的)
附录:胡言乱语
Scale Law还是展示的比较清晰的,通过加大对特征交互的计算成本投入,可以获得性能提升也很符合直觉,有一点小遗憾是没有涉及序列建模的部分。当然推荐的计算时延要求也远超LLM,如何在单位时间内塞下更多的计算量也是技术活。









