最近关注了深度学习编译器领域,梳理了一些知识
其中 halide (论文是2013年)算是比较早的编译器,tvm 的设计灵感也是参考了 halide 的
halide 是怎么优化的?
主要有三个点: 并发(parallelism)、重复工作(Redundant work)、局部性(Locality)
并发(parallelism):

可以拆分成多个向量,并行计算

重复工作(Redundant work)
* Loading a value from memory somtimes slower than re-computing it.

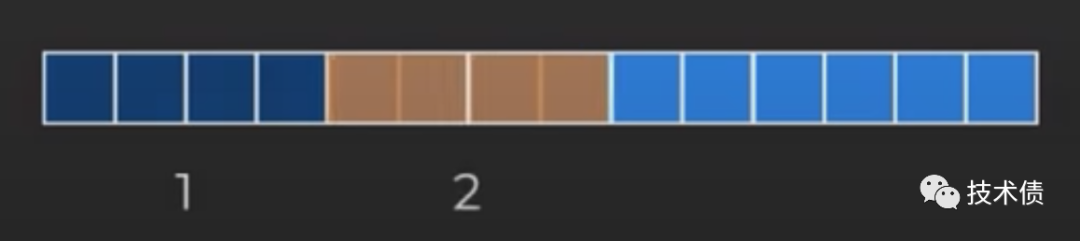
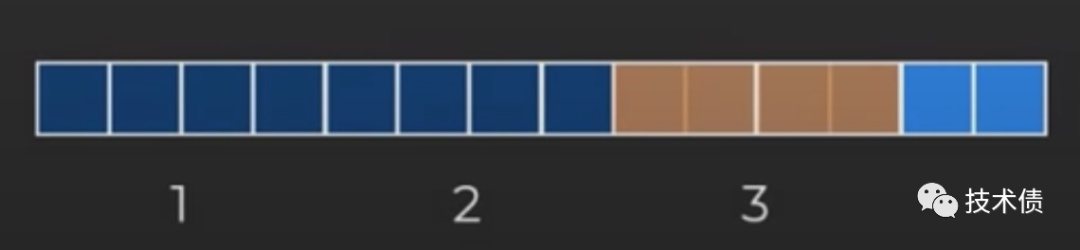

如上图: 每次计算的窗长为4,到最后剩下 2 个「正方形」,方法1是使用单个向量指令计算,最后会有2个「正方形」重复计算;方法2是将剩下2个「正方形」切换到不同的代码路径执行,需要重新 Loading value,一般方法2会比较慢
局部性(Locality)
* If you just wrote a value to memory, you should try to use it quickly, while it's still in cache.
CPU 缓存是有限的,也是相对比较小的。如果某个值在 CPU 缓存,尽量将这个值有关的计算都计算好,提高 CPU 缓存的命中率
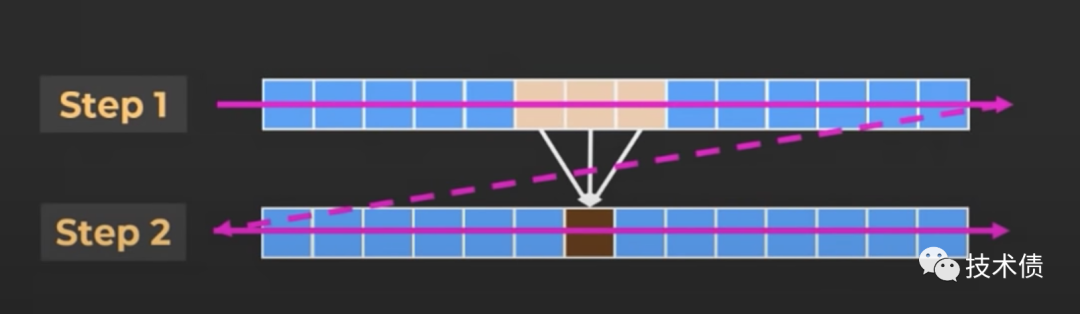
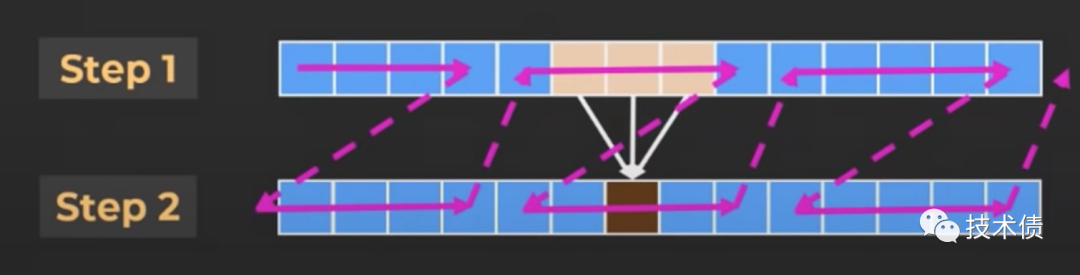
如上图,虽然step2 依赖于 step1 的值(通过3黄色的得到1个棕色的),但是不用等到 step1 都计算完之后,再计算 step2;类似上图,可以在 step1 计算一部分之后,再计算 step2,再回到 step1 这样交替计算,可以提高内存的命中率
编译器优化的例子
循环重排(loop recorder)
alloc arr[256][1024]for each y in 0..1024: for each i in 0..256: do(arr[i][y])
编译器会调整顺序, 因为按照「行」读取,内存地址是连续的,可以提高 CPU 缓存的命中率:
alloc arr[1024][1024]// 上下循环交换for each i in 0..256: for each y in 0..1024: do(arr[i][y])
向量化(vectorize)和 平铺(tiling)
alloc arr[1024][1024]for each i in 0..1024 / 4: for each y in 0..1024 / 4: for each subi in 0..4: for each suby in 0..4: arr[i * 4 + subi][y * 4 + suby] arr[i * 4 + subi + 1][y * 4 + suby] arr[i * 4 + subi][y * 4 + suby + 1] arr[i * 4 + subi + 1][y * 4 + suby + 1]
很多「算子」操作都是基于卷积的,所以根据上文的局部性(Locality),可以使用这种向量化的方式提高 CPU 缓存的命中率
这个「窗长」也不一定为4,不同卡的策略是不同的。tvm 通过 autoschedule 找到较优的策略。
当然,现实的优化还是很复杂的,tvm 是先编译成 RelayIR,然后编译成 TE 子图,对这些子图重排优化,autoschedule 找到较优的子图路径和参数(窗长等),再做推理的
体验
我用 tvm 跑 Resnet(小模型 26M) 模型简单地测试下,比用 onxx cuda 跑快 1000+ 倍(相同环境,只统计推理时间,编译时间不算),前者是 0.00249s, 后者是 3.488s,这比我预期的还要快很多,还是在没有做 tune 的结果
参考
https://halide-lang.org/
http://people.csail.mit.edu/jrk/halide-pldi13.pdf
https://zhuanlan.zhihu.com/p/358837301










