原文 | CSDN Tom Hardy
一、介绍
缺陷检测被广泛使用于布匹瑕疵检测、工件表面质量检测、航空航天领域等。传统的算法对规则缺陷以及场景比较简单的场合,能够很好工作,但是对特征不明显的、形状多样、场景比较混乱的场合,则不再适用。近年来,基于深度学习的识别算法越来越成熟,许多公司开始尝试把深度学习算法应用到工业场合中。二、缺陷数据
如下图所示,这里以布匹数据作为案例,常见的有以下三种缺陷,磨损、白点、多线。

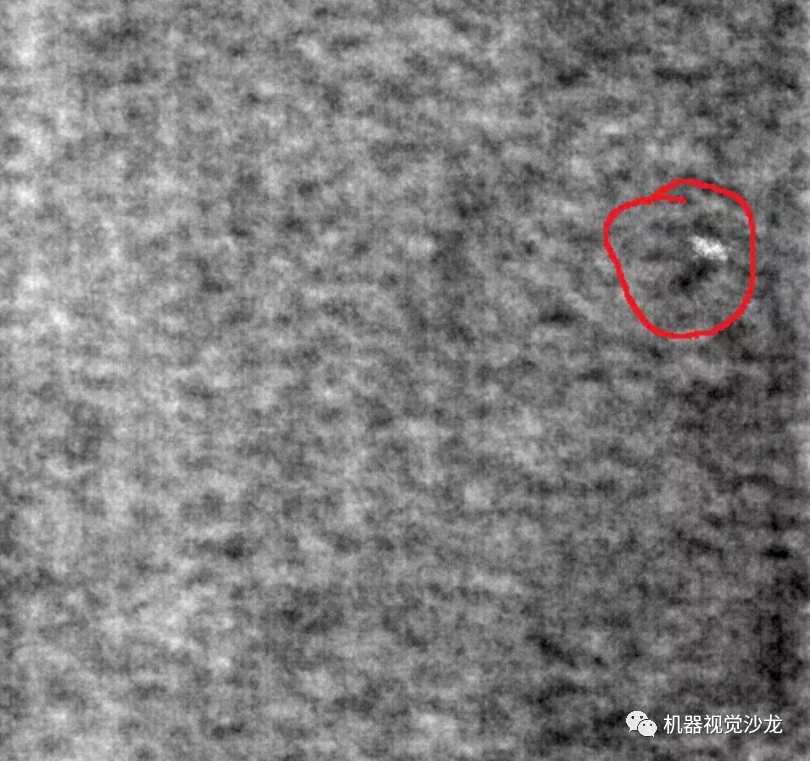

如何制作训练数据呢?这里是在原图像上进行截取,截取到小图像,比如上述图像是512x512,这里我裁剪成64x64的小图像。这里以第一类缺陷为例,下面是制作数据的方法。


注意:在制作缺陷数据的时候,缺陷面积至少占截取图像的2/3,否则舍弃掉,不做为缺陷图像。一般来说,缺陷数据都要比背景数据少很多,此外通过增强后的数据,缺陷:背景=1:1,每类在1000幅左右~~~
三、网络结构
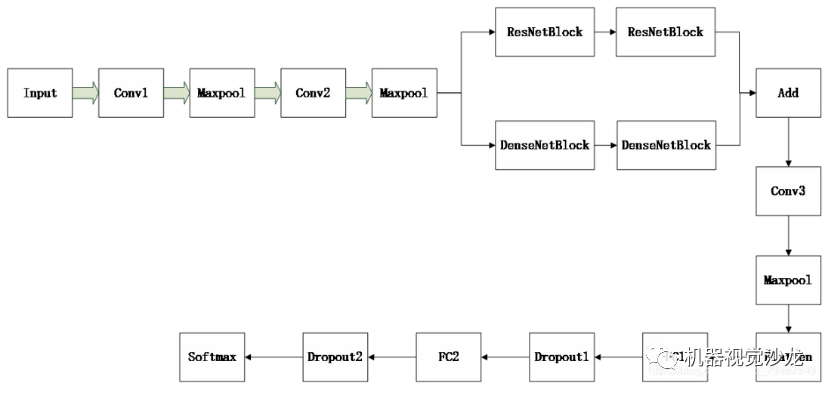
具体使用的网络结构如下所示,输入大小就是64x64x3,采用的是截取的小图像的大小。每个Conv卷积层后都接BN层,具体层参数如下所示。Conv1:64x3x3
Conv2:128x3x3
ResNetBlock和DenseNetBlock各两个,具体细节请参考残差网络和DenseNet。
Add:把残差模块输出的结果和DenseNetBlock输出的结果在对应feature map上进行相加,相加方式和残差模块相同。注意,其实这里是为了更好的提取特征,方式不一定就是残差模块+DenseNetBlock,也可以是inception,或者其它。
Conv3:128x3x3
Maxpool:stride=2,size=2x2
FC1:4096
Dropout1:0.5
FC2:1024
Dropout1:0.5
Softmax:对应的就是要分的类别,在这里我是二分类。
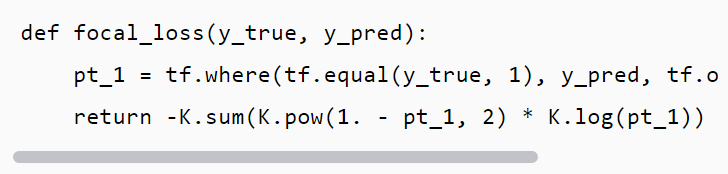
关于最后的损失函数,建议选择Focal Loss,这是何凯明大神的杰作,源码如下所示:
四、整幅场景图像的缺陷检测
上述训练的网络,输入是64x64x3的,但是整幅场景图像却是512x512的,这个输入和模型的输入对不上号,这怎么办呢?其实,可以把训练好的模型参数提取出来,然后赋值到另外一个新的模型中,然后把新的模型的输入改成512x512就好,只是最后在conv3+maxpool层提取的feature map比较大,这个时候把feature map映射到原图,比如原模型在最后一个maxpool层后,输出的feature map尺寸是8x8x128,其中128是通道数。如果输入改成512x512,那输出的feature map就成了64x64x128,这里的每个8x8就对应原图上的64x64,这样就可以使用一个8x8的滑动窗口在64x64x128的feature map上进行滑动裁剪特征。然后把裁剪的特征进行fatten,送入到全连接层。具体如下图所示。
全连接层也需要重新建立一个模型,输入是flatten之后的输入,输出是softmax层的输出。这是一个简单的小模型。
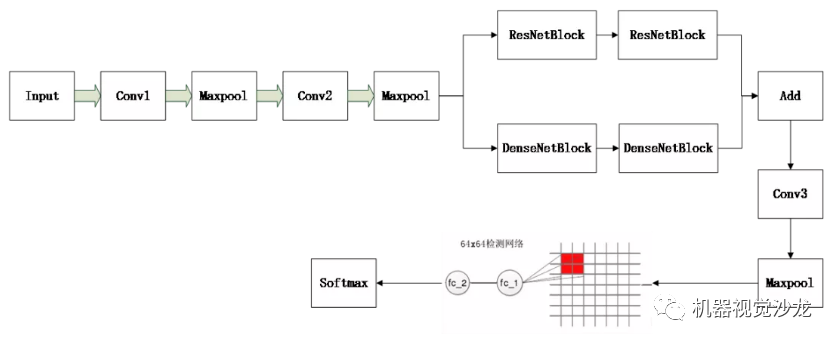
在这里提供一个把训练好的模型参数,读取到另外一个模型中的代码
#提取特征的大模型
def read_big_model(inputs):
# 第一个卷积和最大池化层
X = Conv2D(16, (3, 3), name="conv2d_1")(inputs)
X = BatchNormalization(name="batch_normalization_1")(X)
X = Activation('relu', name="activation_1")(X)
X = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name="max_pooling2d_1")(X)
# google_inception模块
conv_1 = Conv2D(32, (1, 1), padding='same', name='conv2d_2')(X)
conv_1 = BatchNormalization(name='batch_normalization_2')(conv_1)
conv_1 = Activation('relu', name='activation_2')(conv_1)
conv_2 = Conv2D(32, (3, 3), padding='same', name='conv2d_3')(X)
conv_2 = BatchNormalization(name='batch_normalization_3')(conv_2)
conv_2 = Activation('relu', name='activation_3')(conv_2)
conv_3 = Conv2D(32, (5, 5), padding='same', name='conv2d_4')(X)
conv_3 = BatchNormalization(name='batch_normalization_4')(conv_3)
conv_3 = Activation('relu', name='activation_4')(conv_3)
pooling_1 = MaxPooling2D(pool_size=(2, 2), strides=(1, 1), padding='same', name='max_pooling2d_2')(X)
X = merge([conv_1, conv_2, conv_3, pooling_1], mode='concat', name='merge_1')
X = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name='max_pooling2d_3')(X) # 这里的尺寸变成16x16x112
X = Conv2D(64, (3, 3), kernel_regularizer=regularizers.l2(0.01), padding='same', name='conv2d_5')(X)
X = BatchNormalization(name='batch_normalization_5')(X)
X = Activation('relu', name='activation_5')(X)
X = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), name='max_pooling2d_4')(X) # 这里尺寸变成8x8x64
X = Conv2D(128, (3, 3), padding='same', name='conv2d_6')(X)
X = BatchNormalization(name='batch_normalization_6')(X)
X = Activation('relu', name='activation_6')(X)
X = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same', name='max_pooling2d_5')(X) # 这里尺寸变成4x4x128
return X
def read_big_model_classify(inputs_sec):
X_ = Flatten(name='flatten_1')(inputs_sec)
X_ = Dense(256, activation='relu', name="dense_1")(X_)
X_ = Dropout(0.5, name="dropout_1")(X_)
predictions = Dense(2, activation='softmax', name="dense_2")(X_)
return predictions
#建立的小模型
inputs=Input(shape=(512,512,3))
X=read_big_model(inputs)#读取训练好模型的网络参数
#建立第一个model
model=Model(inputs=inputs, outputs=X)
model.load_weights('model_halcon.h5', by_name=True)
五、识别定位结果
上述的滑窗方式可以定位到原图像,8x8的滑窗定位到原图就是64x64,同样,在原图中根据滑窗方式不同(在这里选择的是左右和上下的步长为16个像素)识别定位到的缺陷位置也不止一个,这样就涉及到定位精度了。在这里选择投票的方式,其实就是对原图像上每个被标记的像素位置进行计数,当数字大于指定的阈值,就被判断为缺陷像素。
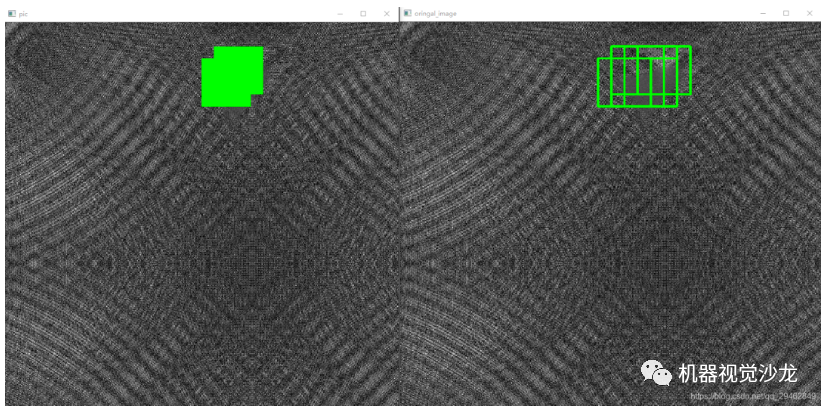

六、一些Trick
对上述案例来说,其实64x64大小的定位框不够准确,可以考虑训练一个32x32大小的模型,然后应用方式和64x64的模型相同,最后基于32x32的定位位置和64x64的定位位置进行投票,但是这会涉及到一个问题,就是时间上会增加很多,要慎用。对背景和前景相差不大的时候,网络尽量不要太深,因为太深的网络到后面基本学到的东西都是相同的,没有很好的区分能力,这也是我在这里为什么不用object detection的原因,这些检测模型网络,深度动辄都是50+,效果反而不好,虽然有残差模块作为backbone。
但是对背景和前景相差很大的时候,可以选择较深的网络,这个时候,object detection方式就派上用场了。








