
从探索性数据分析(EDA)到数据分析再到机器学习模型,数据集的质量和完整性都是确保分析和建模过程有效的关键因素。高质量、完整的数据集能够提供更可靠、更准确的分析结果,有助于制定基于数据的决策。
然而,由于模型之前的数据预处理和操作、模型本身,以及输出结果的任何后处理都存在大量复杂性,许多过程节点可能会出错。而在一些关键领域(如金融、医疗或安全),没有任何误差的余地,因为基于机器学习模型生成的洞见做出的决策至关重要。在数据建模和数据应用中,对数据处理和操作流程进行验证,可以提供保障并有助于排查问题。
接下来,我们将讨论数据验证的重要性。我们将首先描述什么是数据验证,然后介绍五种最流行的(Python)工具,这些工具用于验证输入/输出数据。选择这些工具是因为它们被最大的公司广泛采用,具有强大而多功能的特性,并且拥有活跃的社区支持。
什么是数据验证(Data Validation)
数据验证是指在数据用于分析、决策或输入机器学习模型之前,确保数据准确、可靠和一致的过程。通过验证数据,我们旨在减少错误或不一致性,防止引入任何可能扭曲分析结果的偏差。
数据验证的目标是消除数据集中存在的任何错误。要适当地解决手头的问题,追踪这些错误的根本原因至关重要。尽管导致数据错误的原因有很多,以下是一些常见的例子:
人为错误:只要涉及人类输入的数据,就可能会出错。例如,设想一个人在填写调查问卷以确定是否有资格获得抵押贷款时,错误地在薪水末尾添加了几个零,或者遗漏了年龄中的一位数字。错误不可避免地会发生,但重要的是在数据用于任何决策模型之前,识别和解决数据输入的错误。
不完整数据:在许多情况下,经常会遇到不完整的数据。有时这是由于调查问卷中的可选字段,其他情况下可能是错误或数据丢失。
重复数据:重复记录可能会扭曲汇总统计数据并影响我们的分析。
格式不一致:格式(如日期)或单位(如货币)的不一致在分析数据和比较/合并数据集时可能成为严重的数据质量问题。
验证ML模型的输出:在一个模型的输出作为另一个模型的输入的情况下,如估计个人薪水的模型随后用于评估其信用评分,验证每个模型的准确性和可靠性至关重要。在这种情况下,我们也应验证第一个模型的正确性。在某些极端情况下,特别是处理线性模型时,预测的薪水可能会不成比例地增加或为负数。我们应该在这些问题传播到下游模型之前加以防范。
显然,可能出错的地方有很多,因此没有一种放之四海而皆准的解决方案。这进一步强调了制定特定流程以尽可能捕捉潜在问题的重要性。在基于不准确数据做出任何决策之前解决问题显然要容易得多。在验证数据时,有几个关键检查需要实施以确保数据的完整性和适用性:
检查数据类型:确保数据类型与我们的预期一致。例如,年龄应该是整数。
检查格式:确保输入数据的格式(如日期或货币)与我们的预期一致,并且与我们可能希望对这些数据点执行的操作兼容。
验证正确性/约束条件:例如,确保代表月份的数值不超过12。
进行唯一性检查:确保数据没有重复。如果唯一标识符(如客户ID、银行账号等)不是唯一的,进一步处理数据时可能会遇到严重问题。
从数据科学家的角度来看,拥有这些程序性检查和流程允许他们专注于调试和改进机器学习模型,而不是费力地检查高度复杂的ETL管道的每一步。确保数据的可靠性是一个显著优势,因为它使数据专业人员能够专注于他们的专长。持续通过探索性数据分析(EDA)探索数据至关重要,因为这可能揭示在初始验证过程中未检测到的任何差异或新问题。
数据验证的十分重要,要引起我们的高度重视。数据专业人员经常在数据验证上十分矛盾的:一方面,他们知道数据验证的重要性;另一方面,数据验证是十分枯燥、费时、费力、很少有成就感的任务。幸运的是:有相当多的工具/库使这项工作变得更加轻松和简单。
数据验证(Data Validation)工具
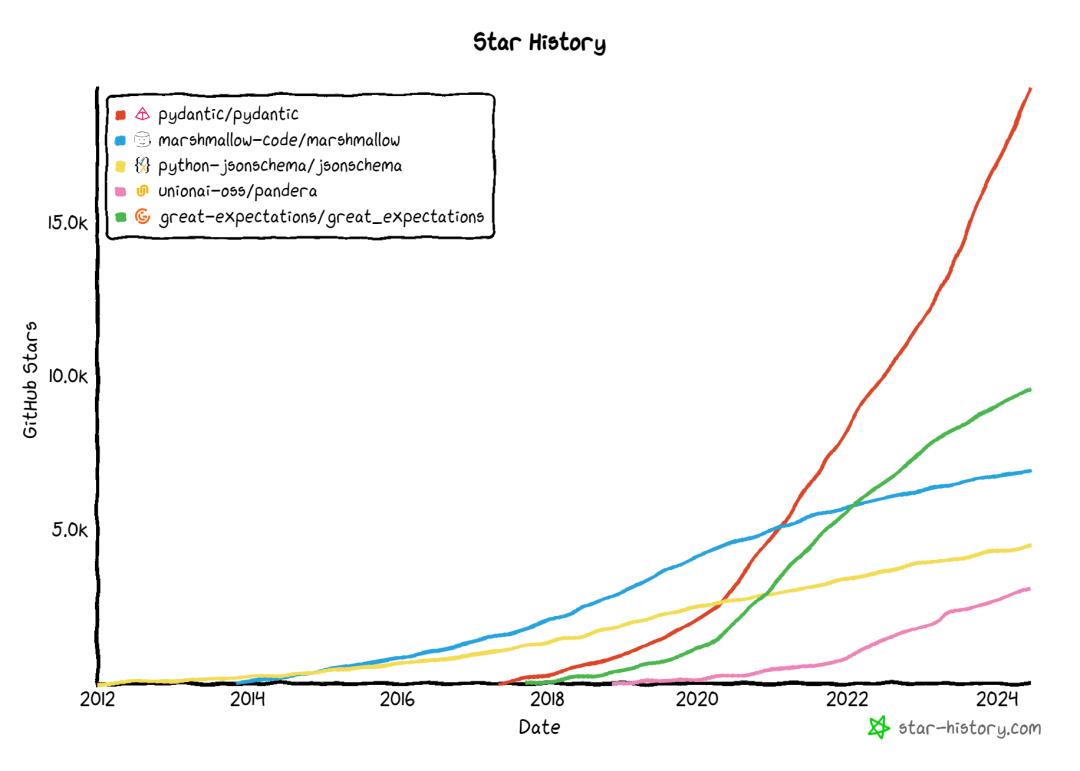
接下来我们将介绍一些最流行的用于数据验证的Python工具,我们抽取了五个数据验证的工具:Pydantic、Great Expectations、Marshmallow、jsonschema和Pandera;下图是五种工具在github的星星增长情况。下面的内容只是简要描述每个工具,并提供一个简单的使用示例。每个工具都足够复杂,如果想详细理解和应用这个工具请参阅相应的文档或GitHub库。
Pydantic
Pydantic 是最广泛使用的Python数据验证库。它之所以如此受欢迎的原因如下:
使用类型注解进行模式验证:这减少了学习曲线和用户需要编写的代码量。
无缝集成流行的IDE和静态分析工具。
由于其验证逻辑是用Rust编写的,Pydantic 是速度最快的数据验证库之一。
Pydantic 支持多种现成的验证器(如示例、电话号码、国家代码等),并且还提供了构建自定义验证器的可能性。这意味着用户几乎没有限制,可以为他们的使用案例实现自定义解决方案。
Pydantic 经过了严格的测试,广泛应用于科技公司。

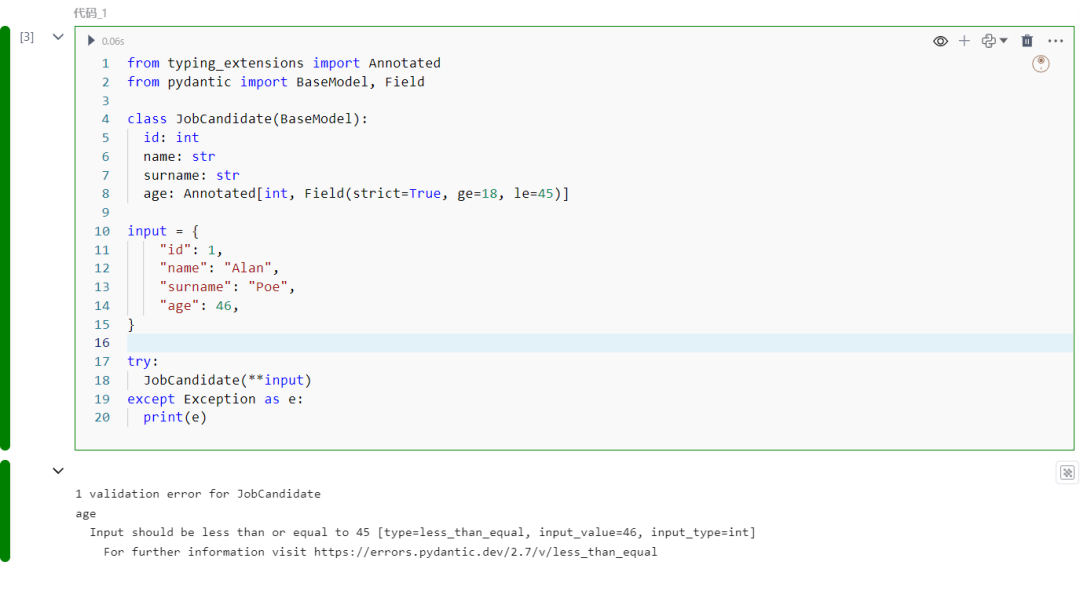
下面是Pydantic的一个实际示例。我们首先创建一个数据模型。我们假设对象是一个求职者,并希望存储他们的ID、名字、姓氏和年龄。我们将年龄限制在18到45岁之间。然后,我们创建一个包含所需值的字典。
from typing_extensions import Annotatedfrom pydantic import BaseModel, Field
class JobCandidate(BaseModel): id: int name: str surname: str age: Annotated[int, Field(strict=True, ge=18, le=45)]
input = { "id": 1, "name": "Alan", "surname": "Poe", "age": 46,}
try: JobCandidate(**input)except Exception as e: print(e)
运行代码片段后,得到以下错误:
在机器学习的情况下,Pydantic 的一个潜在缺点是它并不是针对DataFrame设计的。因此,我们需要编写大量的样板代码将DataFrame的行映射到数据类,然后再用 Pydantic 验证每一行。
Great Expectations
Great Expectations 是数据科学和数据工程工作流中最流行且最全面的数据验证工具。其主要特点包括:
与多种数据环境集成,如 Pandas、Spark 和 SQL 数据库。
我们可以定义包含一组检查的数据期望套件。
该库还处理文档,包括关于检查失败原因的详细报告和分析,并提供关于可以应用于数据帧的质量检查建议。
由于其可扩展性,用户可以创建自定义期望、数据连接器和插件,以根据其特定需求定制验证过程。

下面的示例使用 Great Expectations 进行验证:
import pandas as pdimport great_expectations as ge
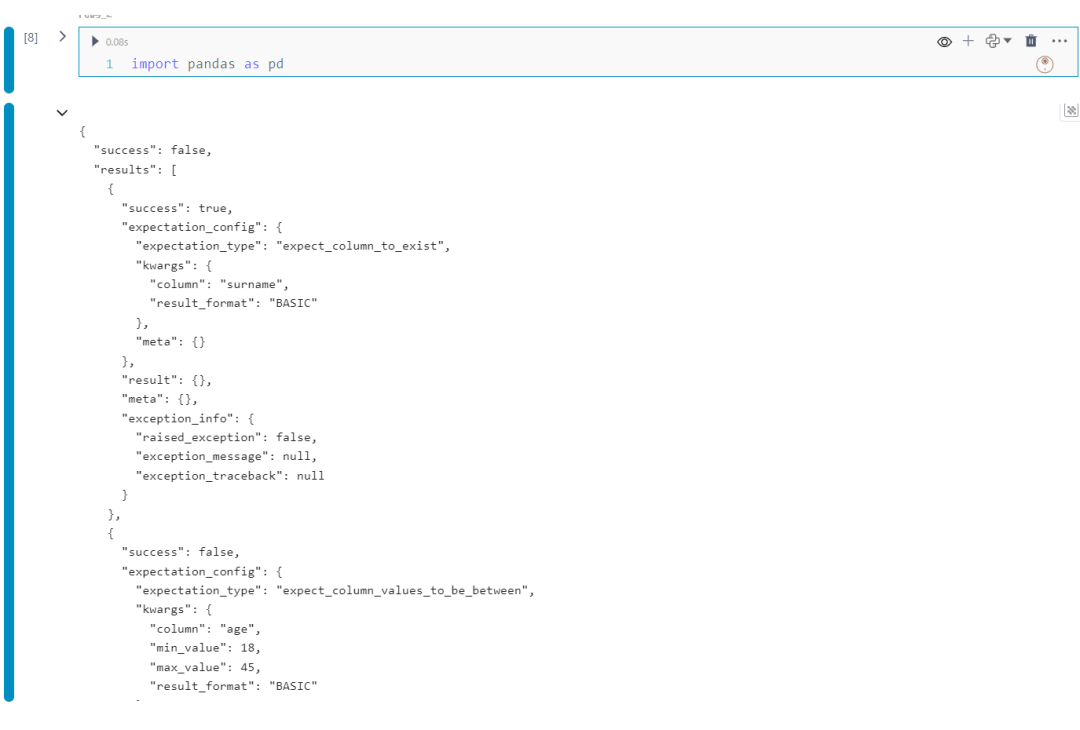
test_df = pd.DataFrame( {"id": [1, 2], "name": ["Alan", "John"], "surname": ["Poe", "Doe"], "age": [46, 19]})expectation_suite = ge.dataset.PandasDataset(test_df)expectation_suite.expect_column_to_exist("surname")expectation_suite.expect_column_values_to_be_between( column="age", min_value=18, max_value=45,)validation_result = expectation_suite.validate()validation_result
运行代码片段后会输出整个报告,关注其中两个元素:
检查套件未能通过,因为至少有一个期望未能满足。首先是成功的检查,验证了surname列的存在。
下面片段将展示一个测试失败的结果:
{ "success": false, "expectation_config": { "expectation_type": "expect_column_values_to_be_between", "kwargs": { "column": "age", "min_value": 18, "max_value": 45, "result_format": "BASIC" }, "meta": {} }, "result": { "element_count": 2, "missing_count": 0, "missing_percent": 0.0, "unexpected_count": 1, "unexpected_percent": 50.0, "unexpected_percent_total": 50.0, "unexpected_percent_nonmissing": 50.0, "partial_unexpected_list": [ 46 ] }, "meta": {}, "exception_info": { "raised_exception": false, "exception_message": null, "exception_traceback": null } }
在这份报告中,我们可以看到两个值中有一个未能通过验证检查,而不符合规则的值是46。
总体而言,由于Great Expectations生成的详尽报告,我们可以根据需要允许一些错误发生,如果错误不经常发生,或者如果即使一个观察值未能通过检查,我们也可以停止整个流程。
Marshmallow
Marshmallow 是一个库,它能够轻松地将复杂数据类型与原生Python数据类型相互转换。它还允许我们通过定义和强制执行规则来验证数据,确保输入数据遵循指定的规则。
接下来,我们演示使用 Marshmallow 实现与我们之前用 Pydantic 看到的示例相当的功能。
from marshmallow import Schema, fields, validate
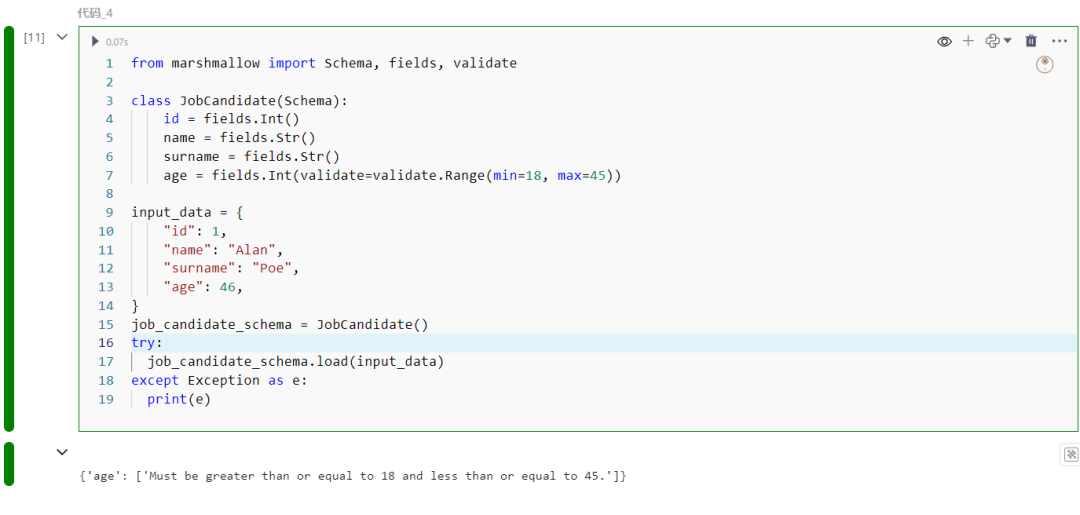
class JobCandidate(Schema): id = fields.Int() name = fields.Str() surname = fields.Str() age = fields.Int(validate=validate.Range(min=18, max=45))
input_data = { "id": 1, "name": "Alan", "surname": "Poe", "age": 46,}job_candidate_schema = JobCandidate()try: job_candidate_schema.load(input_data)except Exception as e: print(e)
运行代码片段后,得到以下错误:
Marshmallow 和 Pydantic 相似,它也并未专门设计用于支持DataFrame。
jsonschema

jsonschema 是 JSON Schema 规范的 Python 实现,能够在规模化处理 JSON 数据时确保一致性和有效性。接下来,我们将再次使用 jsonschema 库演示相同的示例。您会注意到,最大的区别在于我们使用字典来创建一个求职者的模式。
from jsonschema import validate
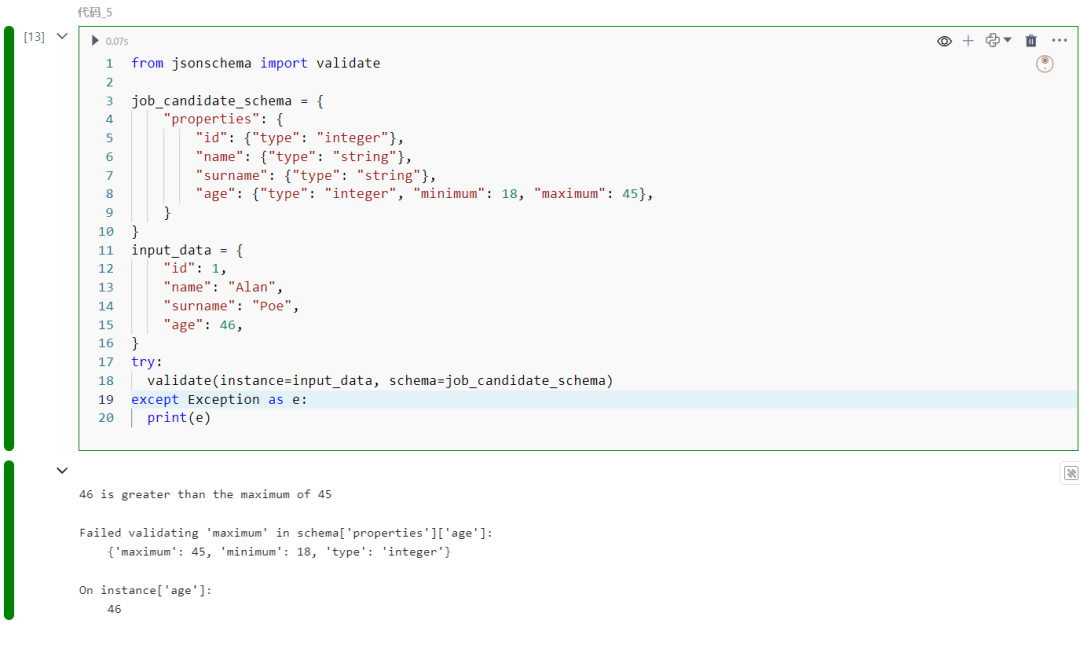
job_candidate_schema = { "properties": { "id": {"type": "integer"}, "name": {"type": "string"}, "surname": {"type": "string"}, "age": {"type": "integer", "minimum": 18, "maximum": 45}, }}input_data = { "id": 1, "name": "Alan", "surname": "Poe", "age": 46,}try: validate(instance=input_data, schema=job_candidate_schema)except Exception as e: print(e)
运行代码片段后,得到以下错误:
Pandera
Pandera 是专门为数据帧设计的数据验证库。使用 Pandera,我们可以在运行时验证数据帧中的数据,这对于在生产环境中运行的关键数据流水线特别有用。Pandera 的一个便利功能是其能够重用定义的模式,并将其应用于各种类型的数据帧,包括 pandas、dask、modin 和 pyspark.pandas。此外,该库支持检查 pandas 数据帧中的列类型,并执行诸如假设检验等统计分析。

参考上面的数据示例创建DataFrame,示例如下:
import pandas as pdimport pandera as pa
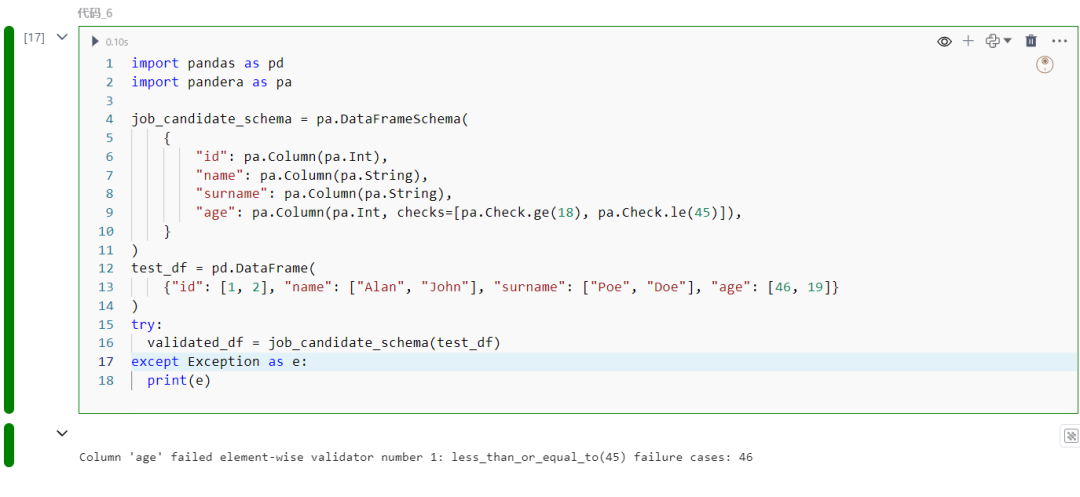
job_candidate_schema = pa.DataFrameSchema(
{ "id": pa.Column(pa.Int), "name": pa.Column(pa.String), "surname": pa.Column(pa.String), "age": pa.Column(pa.Int, checks=[pa.Check.ge(18), pa.Check.le(45)]), })test_df = pd.DataFrame( {"id": [1, 2], "name": ["Alan", "John"], "surname": ["Poe", "Doe"], "age": [46, 19]})try: validated_df = job_candidate_schema(test_df)except Exception as e: print(e)
运行代码片段后,得到以下错误:
以上内容介绍五种数据验证的工具:Pydantic、Great Expectations、Marshmallow、jsonschema和Pandera。通过使用这些工具,可以主动识别和纠正数据问题,从而增强模型输出的可靠性。我们需要重点关注:Great Expectations和Pydantic。
如果您需要验证模型的单个输入/输出,则可以使用 Pydantic。例如,如果您的模型正在生产环境中运行,并接受一个包含特征值的 JSON 字符串作为输入,那么您可以使用 Pydantic 来验证该输入,以确保一切井然有序。同样,在将ML模型的输出提供给利益相关者之前,也可以使用 Pydantic 进行验证。
如果您需要评估多个观察结果,则选择 Great Expectations 更为适合。由于该库生成的全面报告以及其可定制性,您可以在工作流程中创建几乎任何您需要的检查。
本文阐述了数据验证在数据科学和机器学习中的关键作用,并介绍了几种流行的Python工具,如Pydantic和Great Expectations。通过这些工具,组织可以有效地识别和修复数据问题,从而提升模型输出的可靠性和准确性。






