背景
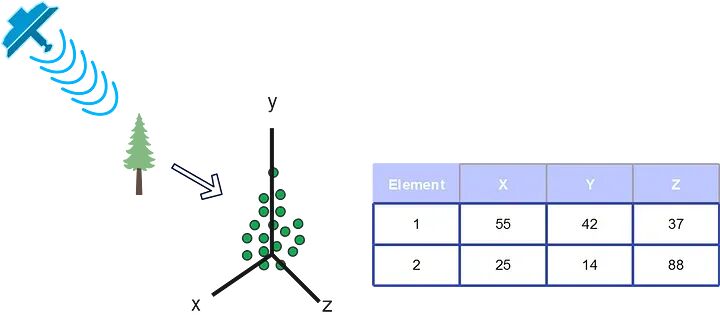
 目前,先进传感器的使用使得在自然资源监测方面能够以高效的方式进行创新,激光雷达技术就是这样一种情况。激光雷达技术是GPS技术、惯性测量单元和激光传感器的集成结果,用于通过收集以三维坐标(x、y、z)呈现的数据来测量可变距离的范围。
目前,先进传感器的使用使得在自然资源监测方面能够以高效的方式进行创新,激光雷达技术就是这样一种情况。激光雷达技术是GPS技术、惯性测量单元和激光传感器的集成结果,用于通过收集以三维坐标(x、y、z)呈现的数据来测量可变距离的范围。
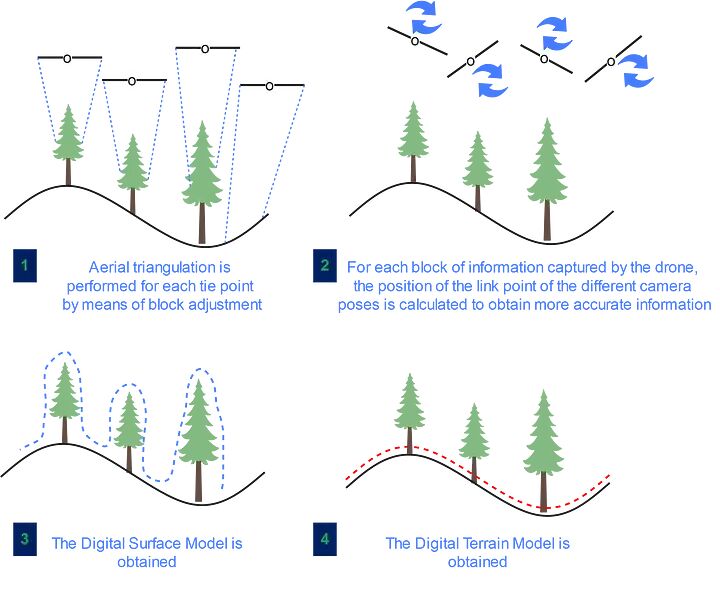
这些数据用于定义地表,并生成数字地形模型(DTM)和数字地表模型(DSM),从中生成冠高模型(CHM),该模型等于地面和地面上方对象顶部之间的高度或残余距离(图1)。
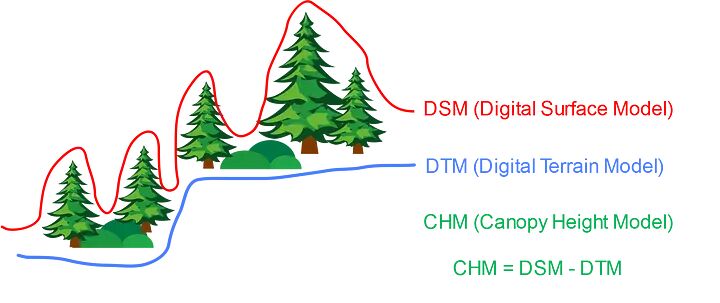
激光雷达数据模型的组成
通过这些数字模型,可以在个体树水平(总高度和冠高等)和植物水平(体积、胸径和生物量等)进行森林生物量学研究(图2)。

从激光雷达数据模型中提取的信息类型。
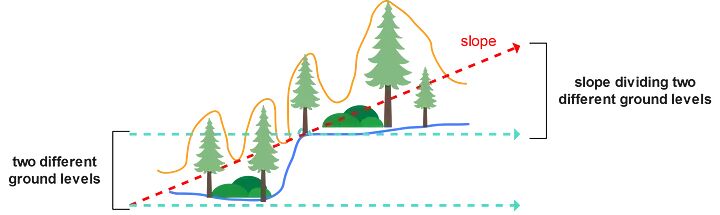
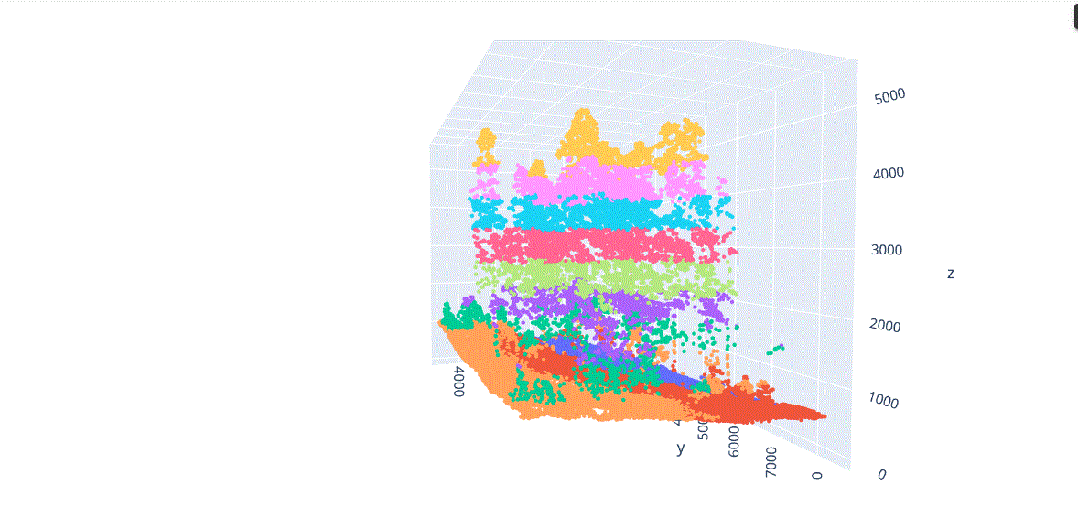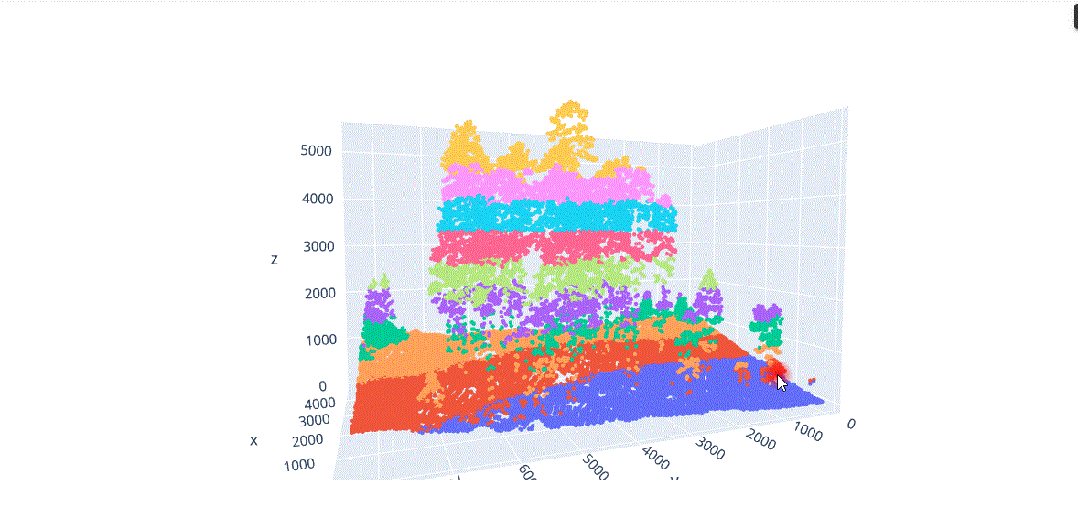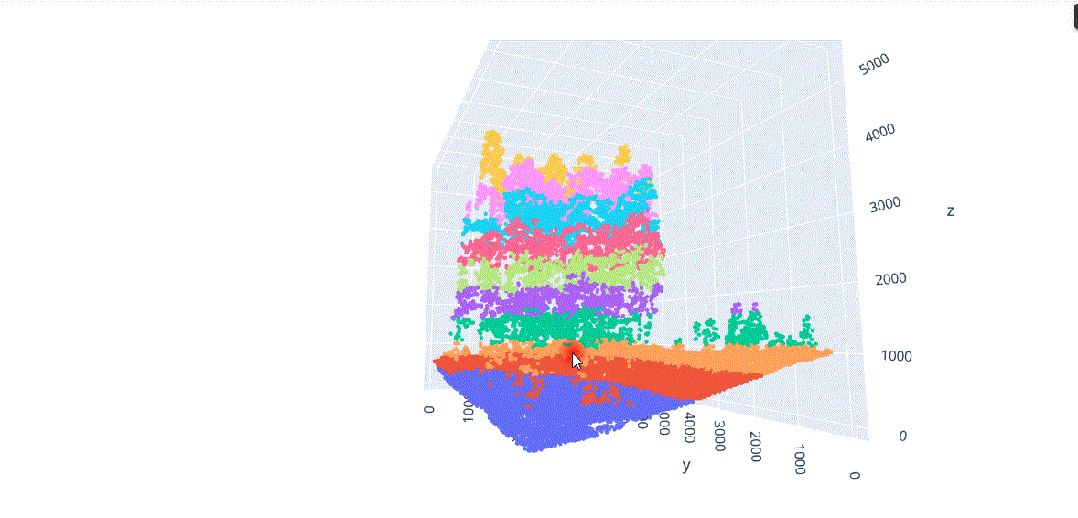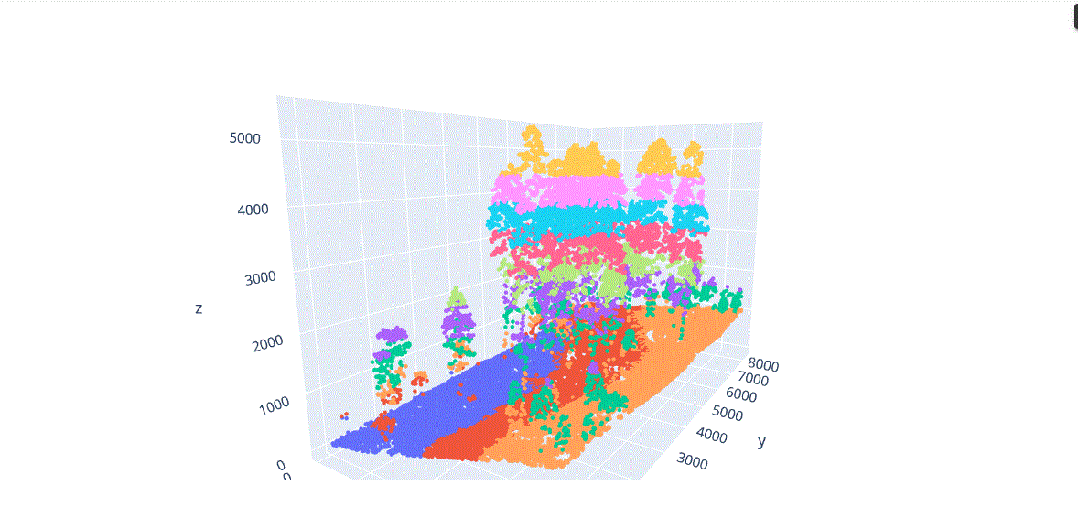
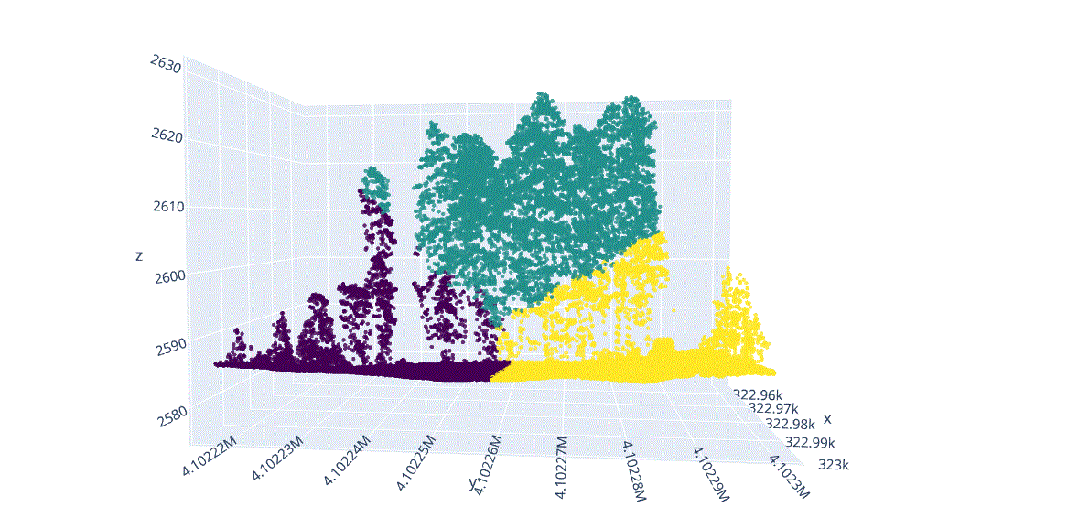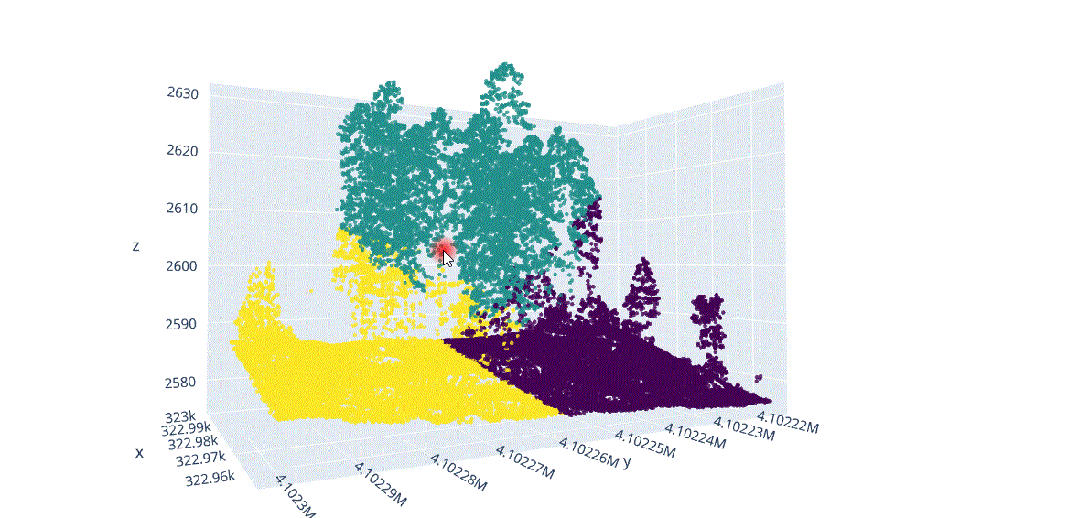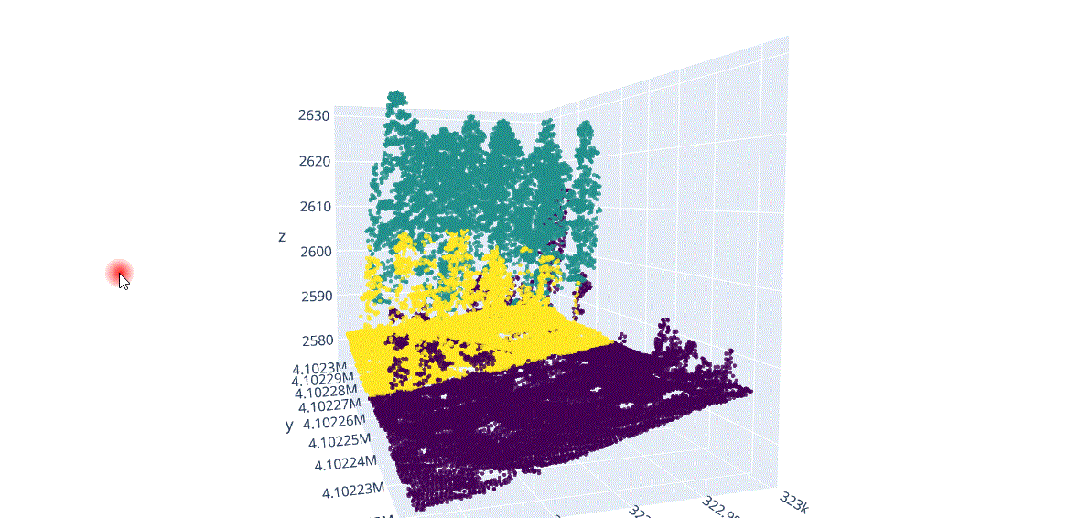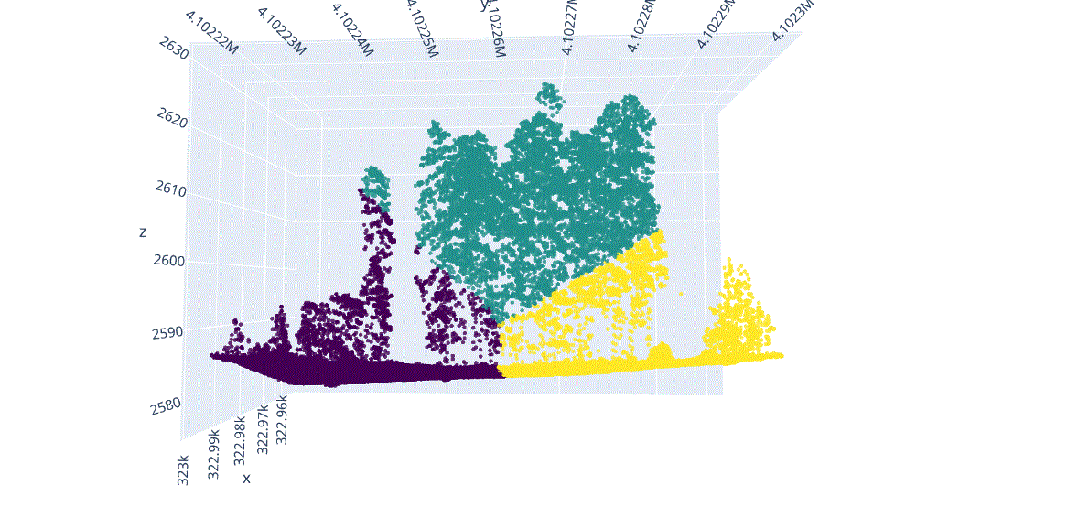
在这种背景下,我们将对这种多维信息进行数据科学处理,以解决不同类型植被结构分离的问题(图3),其中在(x、y、z)中的不同分布导致了对象之间的分割冲突,主要是由于研究区域的坡度(图4)。
由于地形坡度不均匀而导致的不同x.y.z分布的激光雷达元素。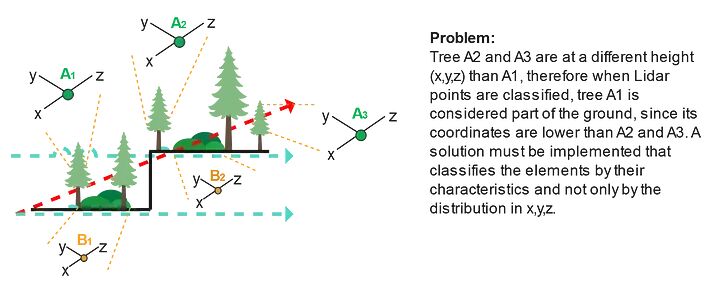
地形坡度影响的激光雷达数据分布。
随后,寻求图像的语义分割,以查看地表的森林和非森林覆盖。最后,通过聚类和过滤最佳阈值,将从CHM图像中分离出不同元素的定量信息。
方法论
数据
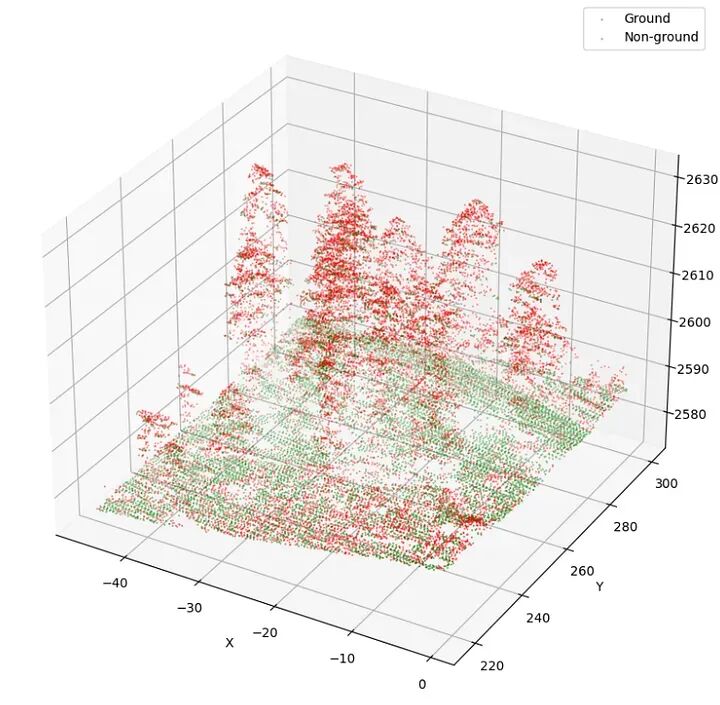
将通过无人机进行激光雷达测量,覆盖一小块土地。由于环境和树木生长的巨大差异,将带宽设置为10米,以获取更广泛范围的样本数据。飞行高度设置为80米,以获取精细的点云数据(图5)。从这些信息中,将从DTM和DSM生成冠高模型(CHM)。
使用无人机获取激光雷达数据。
开发
1 大数据处理
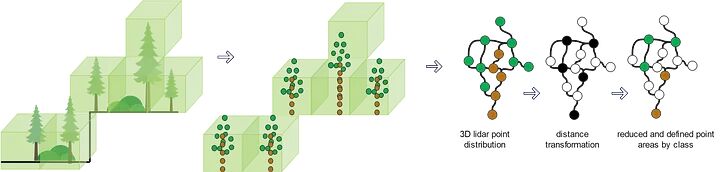
3D点云的一个主要问题是数据密度。这导致数据处理和可视化方面的更高计算成本。为此,需要实施子采样方法来减少点云中的数据密度。其中一些最具代表性的方法包括:
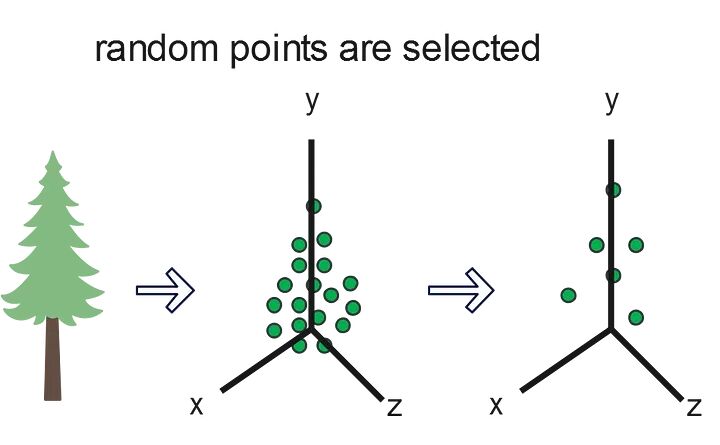
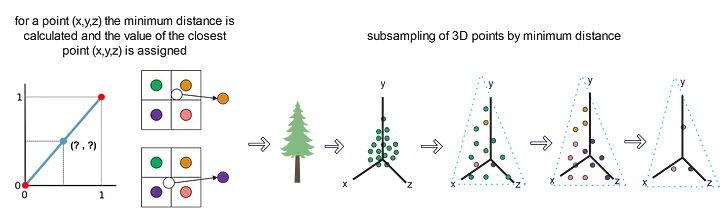
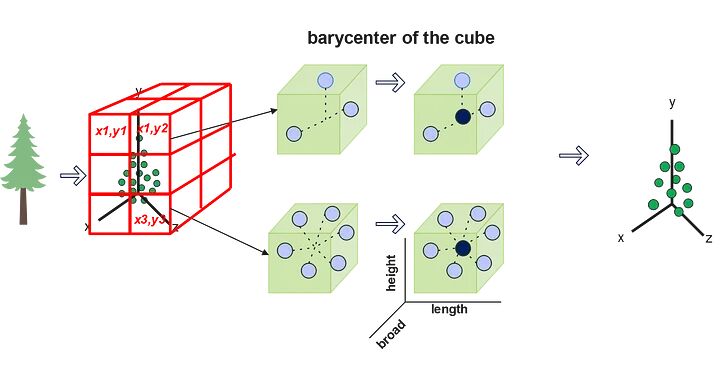
A. 定义边界框的尺寸(体素的长度、宽度和高度)
B. 对于每个体素,检查它是否包含一个或多个点。
C. 最后,计算体素的代表性,即质心。
通过体素子采样的数据压缩,目标现在是能够清楚地从激光雷达数据中分离出属于土壤类别的部分和属于植被类别加草地的部分。为此,将应用分组和分割技术。
2 通过多维度分组分离地面点
我们将首先实现的模型是高维数据聚类。然而,组的目的是包含根据它们的(x、y、z)属性值观察的相关对象,因此可能存在一些属性是相关的,且可能存在任意方向的同类子空间。
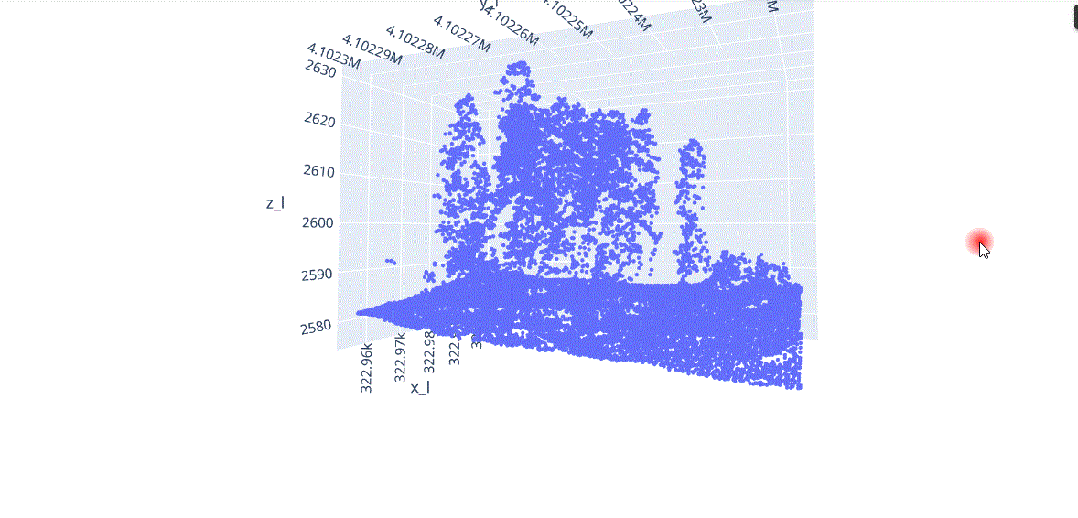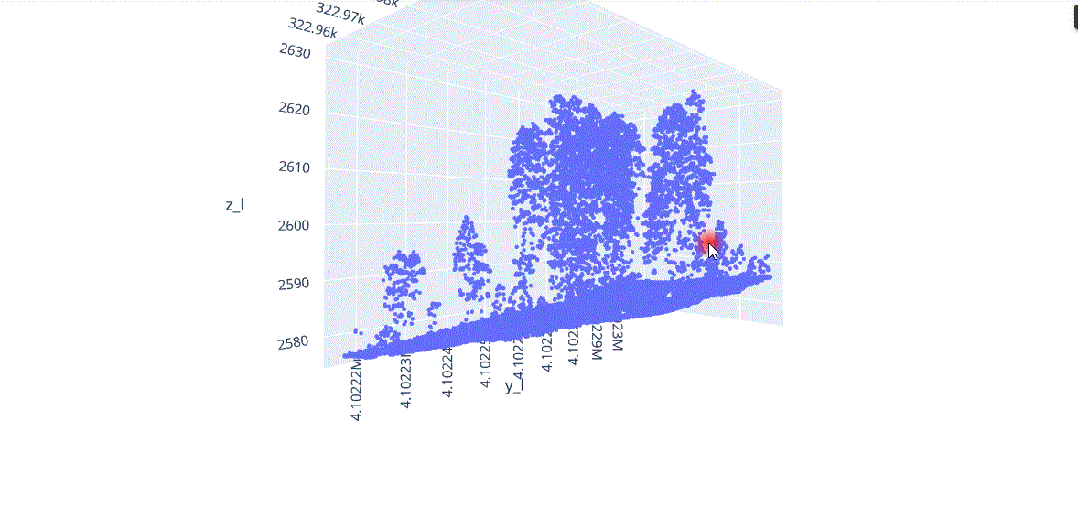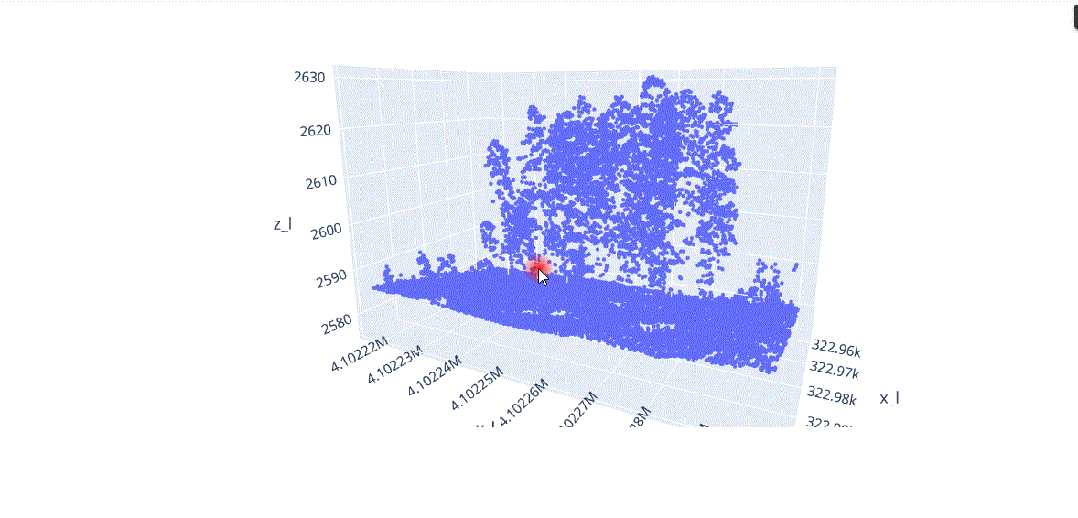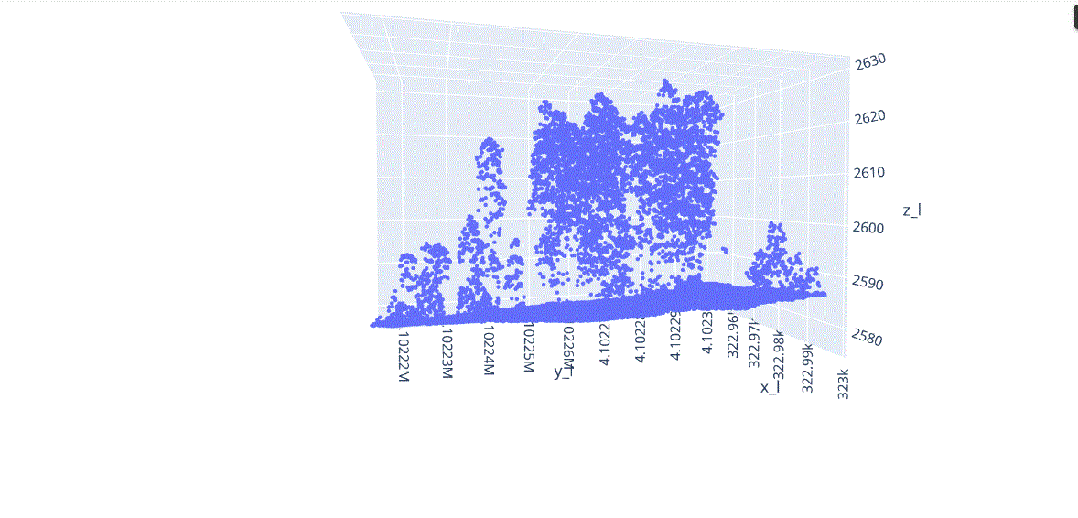
随着维度的增加,距离的概念变得不太精确,因为在给定数据集中,两点之间的距离趋于收敛,因此特别是在区分特定点的最近点和最远点时失去了意义。
3 通过一维分组分离地面点
第二个模型是所谓的Jenks自然断点分类法。其中,根据激光雷达数据的Z值,试图将一系列数字划分为相邻的类别,以最小化每个类别内的平方偏差。这试图将数据分组成最小化组内方差和最大化组间方差的组。
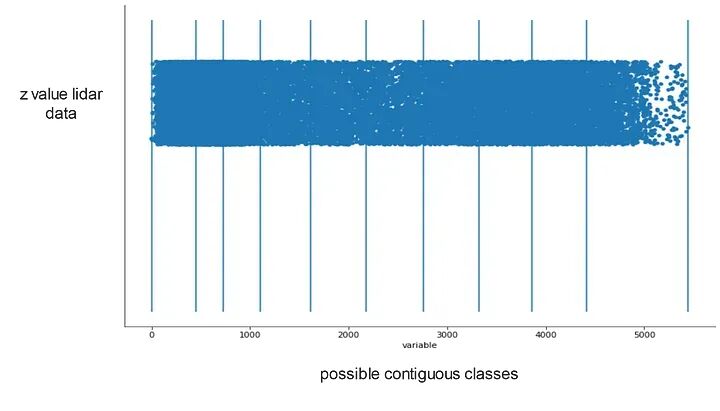
类别中断是以最佳方式创建的,以便将相似的值归为一组并最大化类之间的差异。特征被划分为其边界设置在数据值之间相对较大差异的地方的类。
4 通过使用K-MEANS计算的坡度分离地面点
定义了一个函数,使用简单的算法(K-MEANS)过滤点云的地面点。该算法计算每个点的k个最近邻点,计算每个点对其k个最近邻点的坡度,并根据最大坡度阈值过滤地形点。
重要的是要注意,过滤函数接受三个参数:
points:表示(x、y、z)坐标的形状的数值数组的输入点云。
neighbors:计算每个点的坡度时要考虑的最近邻点的数量。
最大坡度:允许点被视为地形的最大坡度(以弧度为单位)。
5 通过多维图像处理分离地面点
a. 在CHM中进行高斯滤波以平滑数据
使用LiDAR导出的冠高模型(CHM)平滑以去除由树枝引起的虚假局部最大值。这将有助于确保在运行分水岭分割算法之前正确找到树梢。

b. 分割
通过分水岭分割,分水岭算法将像素值视为局部地形(高程)。该算法从标记处泛洪流域,直到与分水岭线上的不同标记相关联的流域相遇。
选择此距离的最大值(即距离的相反的最小值)作为标记,以及这些标记的流域的泛洪定义了分水岭沿着的分离函数。通过这种方式实现了相邻对象的明确分割。
c. 统计网格的最低点
通过执行分割,我们可以正确获取3D激光雷达数据的最低点,从而弥补包含的各种对象的不同地面水平。
为此,生成了一个循环,其中对于每个点(x、y、z),将其与一个掩模进行比较,如果与分割中获得的最小值不同,则标记为1,如果类似于分割值,则标记为0。循环将继续,直到尝试使用相邻数据填充所有值。
d. 形态学运算进行分离
最后,为了更好地精炼激光雷达数据的分类,将基于其邻居进行形态学处理(x、y、z)图像的值,以最小化最终分割的计算计算。形态学膨胀使对象更加可见并填补对象中的小孔。形态学侵蚀去除浮动点和孤立点,因此只保留相关的对象。这计算了基于相邻值之间的差异的加权高度差。


本文仅供学习交流使用,如有侵权请联系作者删除











