PyTorch-Forecasting[1]使用神经网络的时间序列预测对数据科学工作者和研究人员来说都很简单。
为什么准确的预测如此重要?
预测时间序列在很多情况下都很重要,与机器学习从业者高度相关。以需求预测为例,许多用例都源于此。几乎每个制造商都会从更好地了解他们产品的需求中受益,以优化生产数量。生产不足,你将失去收入,生产过剩,你将被迫以折扣价格出售多余的产品。非常相关的是定价,它基本上是一种需求预测,特别关注价格弹性。定价几乎与所有公司有关。
对于大量额外的机器学习应用来说,时间是至关重要的:预测性维护、风险评分、欺诈检测等。事件的顺序和它们之间的时间对于创建一个可靠的预测至关重要。
事实上,虽然时间序列预测可能不像图像识别或语言处理那样闪亮,但它在工业中更常见。这是因为图像识别和语言处理是相对较新的领域,经常被用来为新产品提供动力,而预测已经存在了几十年,并且是许多决策(支持)系统的核心。采用高精度的机器学习模型,如PyTorch Forecasting 中的模型,可以更好地支持决策,甚至使其自动化,往往直接带来数百万美元的额外利润。
深度学习作为一种强大的预测工具出现
深度学习(神经网络)近年来在时间序列预测方面超过了传统方法,而且比图像和语言处理方面的表现要小。事实上,在预测纯时间序列(这意味着没有协变量,例如,价格是对需求)方面,深度学习在两年前才超过了传统的统计方法。然而,随着该领域的快速发展,与神经网络相关的准确性优势已经变得非常明显,这值得在时间序列预测中增加使用。例如,最新的架构N-BEATS[2]在M4竞赛数据集上显示,与次好的非神经网络方法(即统计方法的集合)相比,sMAPE下降了11%。这个网络也在PyTorch Forecasting[3]中实现。
此外,即使与其他流行的机器学习算法,如梯度提升树相比,深度学习也有两个优势。首先,神经网络架构的设计可以对时间有固有的理解,也就是说,它们会自动在时间上接近的数据点之间建立起联系。因此,它们可以捕获复杂的时间依赖性。相反,传统的机器学习模型需要手动创建时间序列特征,如过去x天的平均值。这削弱了这些传统机器学习算法对时间依赖性的建模能力。第二,大多数基于树的模型在设计上输出一个阶梯函数。因此,它们不能预测输入变化的边际影响,而且,在域外预测中是出了名的不可靠。例如,如果我们只观察到30欧元和50欧元的价格,基于树的模型不能评估价格从30欧元变为35欧元对需求的影响。因此,它们往往不能直接用于优化投入。然而,这往往是创建机器学习模型的全部意义所在--其价值在于优化协变量。同时,神经网络采用连续激活函数,特别擅长在高维空间内插值,也就是说,它们可以用来优化输入,如价格。
什么是 PyTorch Forecasting?

PyTorch Forecasting预测目的是利用神经网络为现实世界的案例和研究简化时间序列预测。它通过提供最先进的时间序列预测架构,可以很容易地用pandas数据进行训练。
- 高级别的API大大降低了用户的工作量,因为用户不需要具备如何使用PyTorch准备训练数据集的具体知识。TimeSeriesDataSet类负责处理变量转换、缺失值、随机子抽样、多历史长度等问题。你只需要提供pandas数据框架并指定模型应该从哪些变量中学习。
- BaseModel类提供了通用的可视化功能,如显示预测与实际情况和部分依赖关系图。在tensorboard[4]中可以自动记录指标和例子形式的训练进度。
- 最先进的网络被用于有和无协变量的预测。它们还带有专门的内置解释能力。例如,时态融合转化器[5][3],在基准测试中以36-69%的优势击败了亚马逊的DeepAR,它带有变量和时间重要性测量。在下面的例子中可以看到更多这方面的内容。
- 有许多多跨度的时间序列指标可以评估多个预测跨度的预测结果。
- 为了实现可扩展性,这些网络被设计成与PyTorch Lightning[6]一起使用,允许在CPU和单个及多个(分布式)GPU上进行开箱训练。Ranger优化器的实现是为了更快地训练模型。
- 为了方便实验和研究,添加网络是很简单的。该代码的设计明确考虑到了PyTorch专家。他们会发现即使是复杂的想法也很容易实现。事实上,人们只需要继承BaseModel类,并遵循前向方法输入和输出的惯例,就可以立即启用记录和解释功能。
要开始使用,文档中的详细教程展示了端到端的工作流程。我也将在本文后面讨论一个具体的例子。
我们为什么需要这个包?
PyTorch Forecasting 有助于克服使用深度学习的重要障碍。虽然深度学习已经在图像和语言处理中占据了主导地位,但在时间序列预测中却不尽如此。该领域仍然由传统的统计方法(如ARIMA)和机器学习算法(如梯度提升)所主导,只有贝叶斯模型是个例外。深度学习尚未成为时间序列预测的主流的原因有两个方面,所有这些都已经可以被克服:
- 训练神经网络几乎总是需要GPU,而GPU并不总是现成的。硬件要求往往是一个重要的障碍。然而,通过将计算转移到云中,这一障碍可以被克服。
- 与传统方法相比,神经网络的使用难度相对较大。这对于时间序列预测来说尤其如此。目前缺乏与流行的框架(如Facebook的PyTorch或谷歌的Tensorflow)一起使用的高级API。对于传统的机器学习,存在着sci-kit learn生态系统,它为从业者提供了一个标准化的界面。
鉴于其对用户的不友好性需要大量的软件工程,这第三个障碍在深度学习社区被认为是至关重要的。
 一个深度学习从业者的典型感言
一个深度学习从业者的典型感言
简而言之,PyTorch Forecasting的目的是做fast.ai[7]
为图像识别和自然语言处理所做的事。这大大促进了神经网络从学术界向现实世界的扩散。PyTorch Forecasting通过为PyTorch提供高水平的API,直接利用pandas数据框架,为时间序列预测做相应的工作。为了方便学习,与fast.ai不同,该软件包并没有创建一个全新的API,而是建立在完善的PyTorch和PyTorch Lightning API之上。
如何使用PyTorch Forecasting?
这个小例子展示了包的力量和它最重要的抽象。我们将
- 训练Temporal Fusion Transformer[8]。这是一个由牛津大学和谷歌开发的架构,在基准测试中以36-69%的优势击败了亚马逊的DeepAR、
注意:下面的代码只适用于PyTorch Forecasting的0.4.1版本和PyTorch Lightning的0.9.0版本。要在最新的版本中运行,需要进行最小的修改。包含最新代码的完整教程[9]。
创建用于训练和验证的数据集
首先,我们需要将我们的时间序列转换成pandas数据框架,其中每一行都可以用时间步长和时间序列来标识。幸运的是,大多数数据集已经是这种格式了。在本文中,我们将使用Kaggle的Stallion数据集[10],描述各种饮料的销售情况。我们的任务是按库存单位(SKU),即产品,对一个机构(即商店)的销售量进行六个月的预测。有大约21000个月的历史销售记录。除了历史销售记录外,我们还有关于销售价格、代理机构的位置、特殊日子(如节假日)以及整个行业的销售量的信息。
from pytorch_forecasting.data.examples
import get_stallion_data
data = get_stallion_data() # load data as pandas dataframe
该数据集已经有了正确的格式,但缺少了一些重要的特征。最重要的是,我们需要添加一个时间索引,这个索引在每个时间步长中都会递增一个。此外,增加日期特征也是有益的,在这种情况下,这意味着从日期记录中提取月份。
#添加时间索引
data["time_idx"] = data["date"].dt.year * 12 + data["date"].dt.monthdata["time_idx"] -= data["time_idx"].min()
# 添加额外的特征
# 类别必须是字符串
data["month"] = data.date.dt.month.astype(str).astype("category")
data["log_volume"] = np.log(data.volume + 1e-8)
data["avg_volume_by_sku"] = (
data
.groupby(["time_idx", "sku"], observed=True)
.volume.transform("mean")
)
data["avg_volume_by_agency"] = (
data
.groupby(["time_idx", "agency"], observed=True)
.volume.transform("mean")
)
# 我们想把特殊的日子编码为一个变量,因此需要先把一个热度倒过来。
# 因此需要先进行反向的一键编码
special_days = [
"easter_day", "good_friday", "new_year", "christmas",
"labor_day", "independence_day", "revolution_day_memorial",
"regional_games", "fifa_u_17_world_cup", "football_gold_cup",
"beer_capital", "music_fest"
]data[special_days] = (
data[special_days]
.apply(lambda x: x.map({0: "-", 1: x.name}))
.astype("category")
)
# 显示样本数据
data.sample(10, random_state=521)
 从数据框架中随机抽取行数
从数据框架中随机抽取行数
下一步是将数据框架转换为PyTorch Forecasting数据集。除了告诉数据集哪些特征是分类的,哪些是连续的,哪些是静态的,哪些是随时间变化的,我们还必须决定如何使数据正常化。在这里,我们分别对每个时间序列进行标准标度,并指出数值总是正的。
我们还选择使用过去六个月的数据作为验证集。
from pytorch_forecasting.data import (
TimeSeriesDataSet,
GroupNormalizer
)max_prediction_length = 6 #预测6个月
max_encoder_length = 24 # 使用24个月的历史数据
training_cutoff = data[
"time_idx"].max() - max_prediction_lengthtraining = TimeSeriesDataSet(
data[lambda x: x.time_idx <= training_cutoff],
time_idx="time_idx",
target="volume",
group_ids=["agency", "sku"],
min_encoder_length=0, # 允许没有历史的预测
max_encoder_length=max_encoder_length,
min_prediction_length=1,
max_prediction_length=max_prediction_length,
static_categoricals=["agency", "sku"],
static_reals=[
"avg_population_2017",
"avg_yearly_household_income_2017"
],
time_varying_known_categoricals=["special_days", "month"],
# 一组分类变量可以被视为一个变量
variable_groups={"special_days": special_days},
time_varying_known_reals=[
"time_idx",
"price_regular",
"discount_in_percent"
],
time_varying_unknown_categoricals=[],
time_varying_unknown_reals=[
"volume",
"log_volume",
"industry_volume",
"soda_volume",
"avg_max_temp",
"avg_volume_by_agency",
"avg_volume_by_sku",
],
target_normalizer=GroupNormalizer(
groups=["agency", "sku"], coerce_positive=1.0
), # 使用softplus,beta=1.0,并按组进行规范化处理
add_relative_time_idx=True, # 作为特征添加
add_target_scales=True, # 添加为特征
add_encoder_length=True, # 添加为特性
)# 创建验证集(predict=True),这意味着要预测每个系列的最后一个最大预测长度的时间点
validation = TimeSeriesDataSet.from_dataset(
training, data, predict=True, stop_randomization=True
)# 为模型创建数据加载器
batch_size = 128
train_dataloader = training.to_dataloader(
train=True, batch_size=batch_size, num_workers=0
)
val_dataloader = validation.to_dataloader(
train=False, batch_size=batch_size * 10, num_workers=0
)
训练Temporal Fusion Transformer
现在是时候创建我们的模型了。我们用PyTorch Lightning来训练这个模型。在训练之前,你可以用它的学习率查找器来确定最佳的学习率。
import pytorch_lightning as pl
from pytorch_lightning.callbacks import (
EarlyStopping,
LearningRateLogger
)
from pytorch_lightning.loggers import TensorBoardLogger
from pytorch_forecasting.metrics import QuantileLoss
from pytorch_forecasting.models import TemporalFusionTransformer# stop training, when loss metric does not improve on validation set
early_stop_callback = EarlyStopping(
monitor="val_loss",
min_delta=1e-4,
patience=10,
verbose=False,
mode="min"
)
lr_logger = LearningRateLogger() # 记录学习率
logger = TensorBoardLogger("lightning_logs") # 记录到tensorboard# 创建训练器
trainer = pl.Trainer(
max_epochs=30,
gpus=0, # 在CPU上训练,使用gpus = [0] 在GPU上运行
gradient_clip_val=0.1,
early_stop_callback=early_stop_callback,
limit_train_batches=30, # 每30个批次运行一次验证
# fast_dev_run=True, # 注释进去以快速检查bug
callbacks=[lr_logger],
logger=logger,
)# 初始化模型
tft = TemporalFusionTransformer.from_dataset(
training,
learning_rate=0.03,
hidden_size=16, # 影响最大的网络规模
attention_head_size=1,
dropout=0.1,
hidden_continuous_size=8,
output_size=7, # QuantileLoss默认有7个量纲
loss=QuantileLoss()、
log_interval=10, # 每10个批次记录一次例子
reduce_on_plateau_patience=4, # 自动减少学习。
)
tft.size() # 模型中29.6k个参数# 适合网络
trainer.fit(
tft,
train_dataloader=train_dataloader,
val_dataloaders=val_dataloader
)

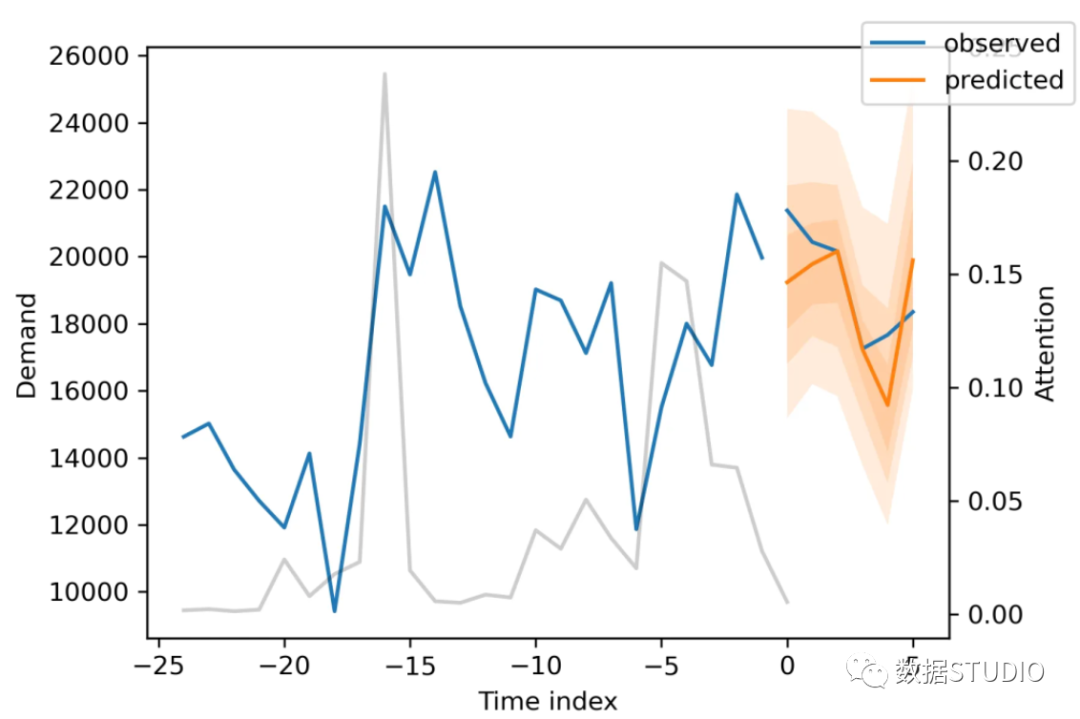
在我电脑上,训练大约需要三分钟,但对于更大的网络和数据集,它可能需要几个小时。在训练过程中,我们可以监控tensorboard,可以用tensorboard --logdir=lightning_logs来启动。例如,我们可以监控训练和验证集上的例子预测。正如你在下图中看到的,预测看起来相当准确。如果你想知道,灰色的线表示模型在进行预测时对不同时间点的关注程度。
 显示训练实例的Tensorboard面板
显示训练实例的Tensorboard面板
评估训练好的模型
训练结束后,我们可以在验证数据集和几个例子上评估这些指标,看看模型的表现如何。鉴于我们只用了21000个样本,结果是非常令人放心的,可以与梯度助推器的结果竞争。
from pytorch_forecasting.metrics import MAE
# 根据验证损失加载最佳模型(鉴于
# 我们使用早期停止,这不一定是最后一个 epoch)
best_model_path = trainer.checkpoint_callback.best_model_path
best_tft = TemporalFusionTransformer.load_from_checkpoint(best_model_path) # 计算验证集的平均绝对误差
actuals = torch.cat([y for x, y in iter(val_dataloader)] )
predictions = best_tft.predict(val_dataloader)MAE(predictions, actuals)
看一下表现最差的sMAPE,我们就可以知道模型在哪些方面存在着可靠的预测问题。这些例子可以提供关于如何改进模型的重要指针。这种实际情况与预测的对比图对所有模型都可用。
from pytorch_forecasting.metrics import SMAPE# 计算用于显示的指标
predictions, x = best_tft.predict(val_dataloader)
mean_losses = SMAPE(reduction="none")(predictions, actuals).mean(1)
indices = mean_losses.argsort(descending=True) # 对损失进行排序raw_predictions, x = best_tft.prediction(val_dataloader, mode="raw, return_x=True)# 仅显示两个例子用于演示
for idx in range(2):
best_tft.plot_prediction(
x,
raw_predictions、
idx=indices[idx]、
add_loss_to_title=SMAPE()
)
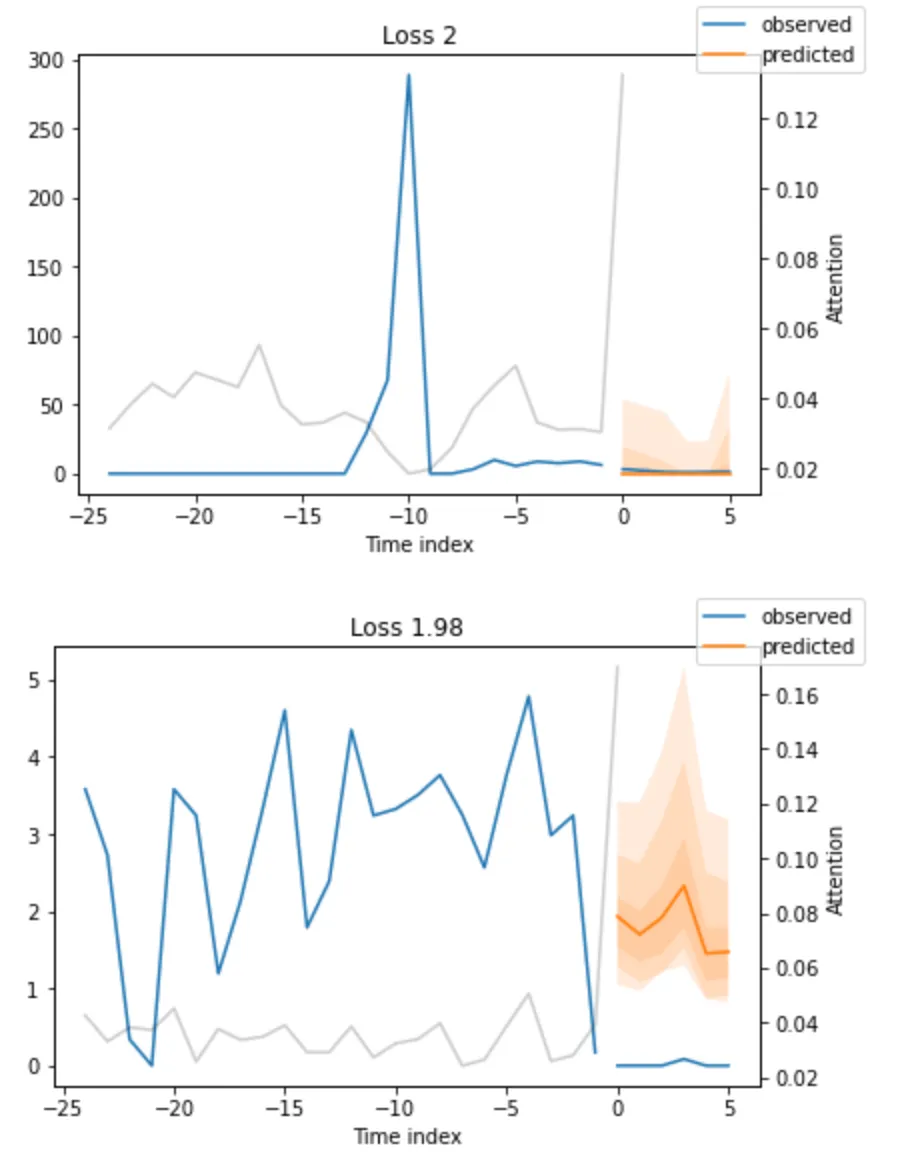
验证集上的两个最差预测。白线是转化器对某个时间点的关注程度。
同样地,我们也可以将我们的模型中的随机例子可视化。PyTorch Forecasting的另一个特点是对训练好的模型进行解释。例如,所有的模型都允许我们随时计算部分依赖图。然而,为了简洁起见,我们将在这里展示时态融合转化器的一些内置解释能力。它通过设计神经网络实现了变量的导入。
interpretation = best_tft.interpret_output(
raw_predictions, reduction="sum"
)best_tft.plot_interpretation(interpretation)
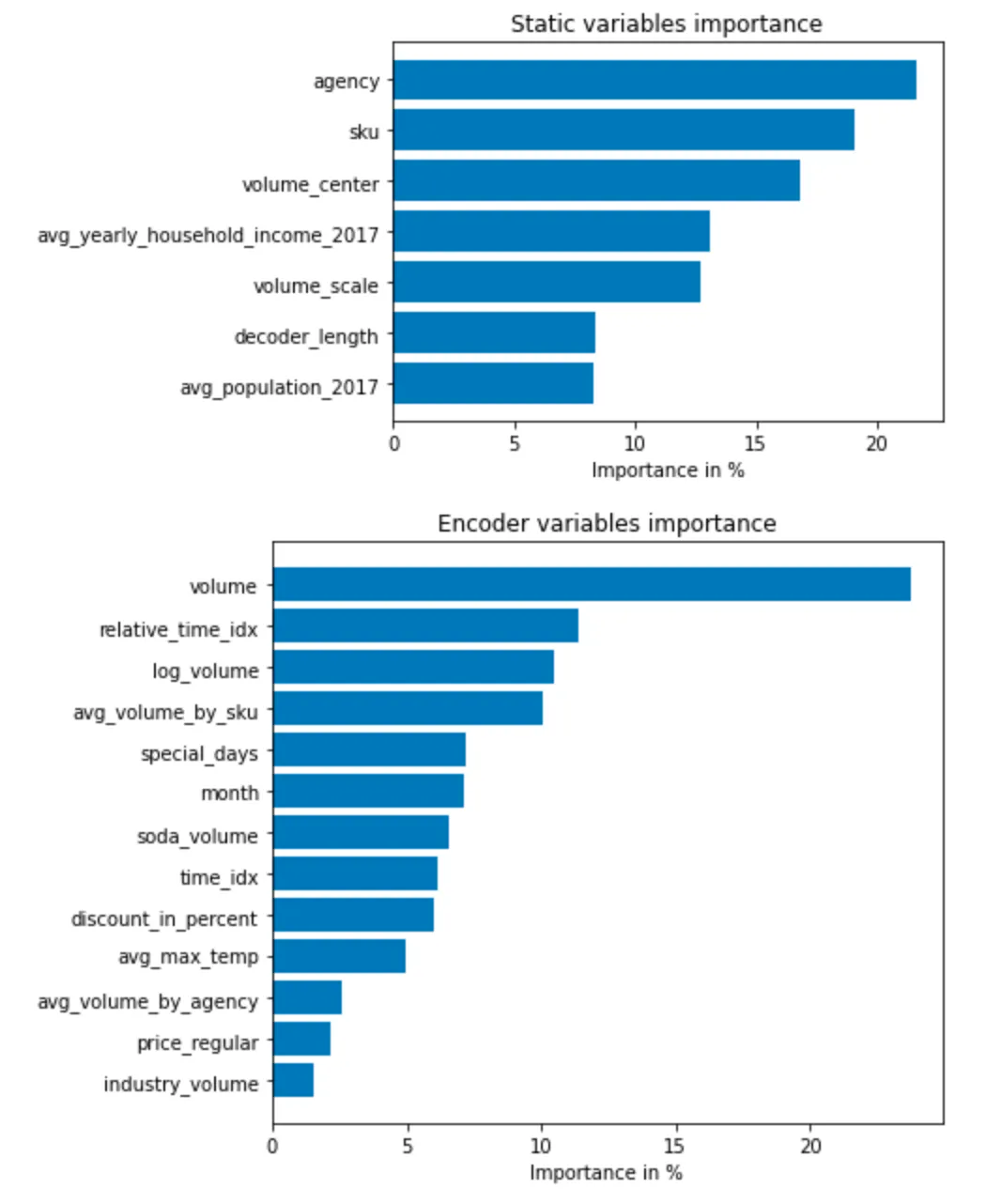
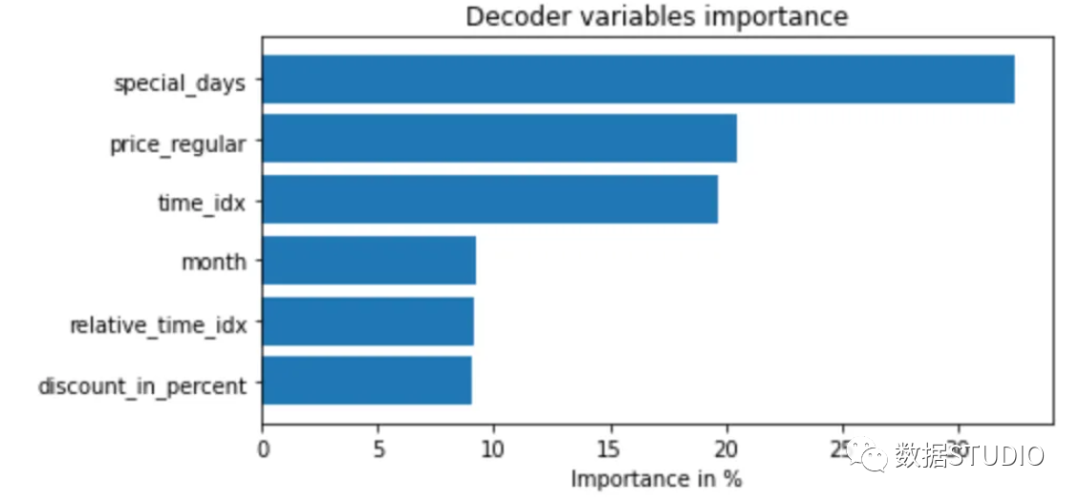
不出所料,过去观察到的成交量是编码器中的首要变量,而与价格有关的变量则是解码器中的首要预测因素。也许更有趣的是,机构在静态变量中只排在第五位。然而,鉴于第二个和第三个变量与地点有关,如果这两个变量不包括在模型中,我们可以预期代理机构的排名会高得多。
总结
使用PyTorch Forecasting软件训练一个模型并深入了解其内部运作是非常容易的。作为一名从业人员,你可以使用该软件包来训练和解释最先进的模型,即开即用。有了 PyTorch Lightning 的整合,训练和预测是可扩展的。作为一名研究人员,你可以利用该软件包为你的架构获得自动跟踪和自省能力,并将其无缝应用于多个数据集。
参考资料
[1]PyTorch-Forecasting: https://pytorch-forecasting.readthedocs.io/
[2]N-BEATS: https://openreview.net/forum?id=r1ecqn4YwB
[3]PyTorch Forecasting: https://pytorch-forecasting.readthedocs.io/en/latest/api/pytorch_forecasting.models.nbeats.NBeats.html
[4]tensorboard: https://www.tensorflow.org/tensorboard
[5]时态融合转化器: https://arxiv.org/pdf/1912.09363.pdf
[6]PyTorch Lightning: https://pytorch-lightning.readthedocs.io/
[7]fast.ai: https://www.fast.ai/
[8]Temporal Fusion Transformer: https://arxiv.org/pdf/1912.09363.pdf
[9]完整教程: https://pytorch-forecasting.readthedocs.io/en/latest/tutorials/stallion.html
[10]Kaggle的Stallion数据集: https://www.kaggle.com/utathya/future-volume-prediction
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)









