点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
链接:https://www.zhihu.com/question/320688440
仅做学术分享,侵删
https://www.zhihu.com/question/320688440/answer/2506004085这些年来我只做可解释性研究,由浅入深,寥若无人,内里支持我的是途中一次次的感慨,人工智能一个被媒体抬到国运高度的方向,依然有着大量的、重大的系统性漏洞。如果半年前聊这个问题,我的措辞不会这么激烈,但是现在情况不一样了。比如,我们证明了在一些情况下,BN操作中的一些非常低级且重大的问题,虽然BN被广为诟病,但是谁能想到这个低级问题居然需要这么多年才发现?(具体内容后续知乎文章再去慢慢讲)
目前这个知乎文章主要解释另一篇工作——我们从动力学角度,发现并理论解释了神经网络的一个优化陷阱。在早期的训练过程中,如果没有很快的找到优化方向而训练被卡住的时候,不同类别的不同样本之间的特征多样性会急剧的下降,甚至不同样本的特征会逐渐趋同。这种现象是十分反常的,但又是被长期忽略的。这个现象其实在大量神经网络都有体现,不仅仅局限在MLP。
可解释性研究不能离开理论。去年我提了一个“博弈交互可解释性理论”体系,从2021年到2022上半年,我们在这个框架体系里面,发表论文近十篇了,还有在投的很多篇。今年,我盘算着在可解释性理论方向上,再推出一个新的理论系列,目前有九篇文章属于这个方向。下面这篇论文是我的博士实习生刘东瑞做的,算是这个新系列中的一篇论文吧。刘东瑞博三的时候转过来跟我实习的,研究中遇到不少坎坷,非常努力,是个扎实的好学生。
【对应论文】
Dongrui Liu, Shaobo Wang, Jie Ren, Kangrui Wang, Sheng Yin, Huiqi Deng, and Quanshi Zhang “Trap of Feature Diversity in the Learning of MLPs” in https://arxiv.org/abs/2112.00980.
大家好,我是刘东瑞(https://shenqildr.github.io/),今年博士四年级,本研究是在张拳石老师@Qs.Zhang张拳石 的指导下,和课题组的王少博同学(https://gszfwsb.github.io)共同牵头完成的。
神经网络在各种任务中取得了成功,但是神经网络性能优越的根本原因尚未得到充分研究。很多研究旨在解释神经网络中的一些典型现象,比如彩票理论、双下降现象、信息瓶颈假说等等。在本文中,
我们发现了一个长期被忽略的基础但反直觉的现象,即在多层感知机训练的前期(在很早期Loss不下降的那一段),特征多样性会快速下降,甚至不同类别的不同样本学习到几乎一样的特征。这时神经网络有些像一个自激系统。这种现象是十分反常的,而且它会破坏多层感知机的训练。
当训练任务比较难的时候,很多神经网络往往“训练不动”,理论上恰恰属于卡在了这个神经网络的系统自激阶段。
我们从学习动力学 (learning dynamics) 的角度理论上解释了这一现象,并且基于理论分析,我们解释了四种可以缓解这个现象操作的原因。
【研究的意义】
尽管在很多任务中(如在图像、文本数据集中的任务)神经网络也会呈现这种反直觉现象,但是往往会被研究人员忽略,因为它与性能没有直接关系。本文发现并解释了这个现象产生的原因。本文的发现将帮助人们理解神经网络的优化过程,并且理论上为解决类似问题提供指导。
【问题的发现】
在本文中,我们发现一个长期被忽略的基础但反直觉的现象。在多层感知机(MLPs)层数较多并且优化困难的时候,MLPs的训练过程可能会展现出两阶段。如图1(b)绿色线所示,在第一阶段(通常不长),training loss基本不下降。在第二阶段,training loss突然开始下降。如图1(b)蓝色线所示,当任务很简单时,第一阶段可能非常短,因此无法被观察到。
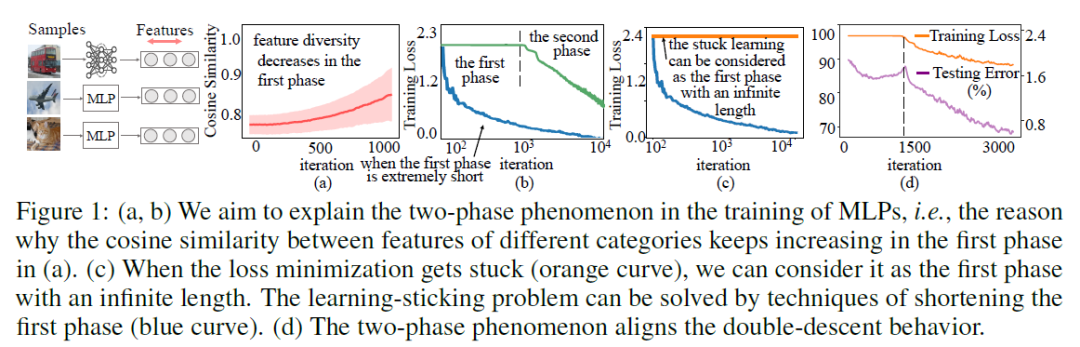
我们发现在第一阶段中,不同种类样本上MLPs的中层特征变得越来越相似(甚至相同)。同一类别中,不同样本的特征梯度多样性一直下降。如图2(a) 所示,在第一阶段中,特征的多样性一直下降,不同类别样本特征的余弦相似度一直上升。并且,如图2(a,b)所示,我们发现第一阶段中特征多样性一直降低的现象在卷积网络(CNNs)和循环神经网络(RNNs)中也存在。更重要的是,网络无法训练的情况(training loss一直不下降)可以被看做是一种无限长的第一阶段。
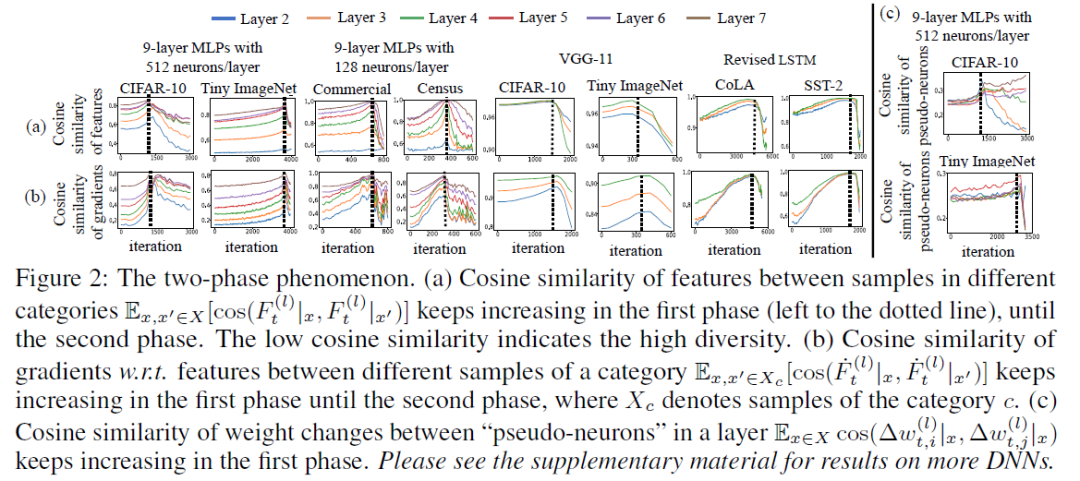
【理论解释特征多样性下降的原因】
我们从MLPs的学习动力学 (learning dynamics) 角度解释了第一阶段中特征多样性下降的现象。我们发现在第一阶段中,网络的中层特征和权重都朝着一个共同的主方向优化。我们从理论上可以对网络权重改变量进行两种方式的分解。


实验验证:下图和表1的实验结果表明,第一主方向的强度很大,主导着网络优化方向。
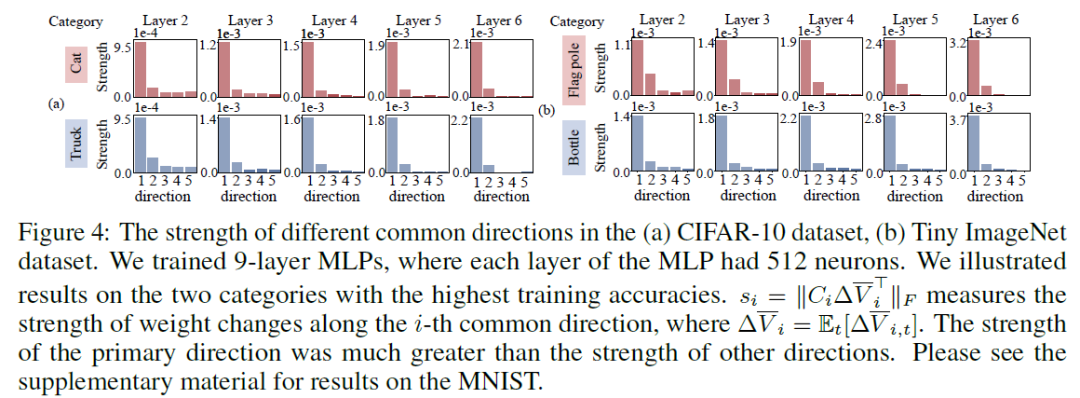
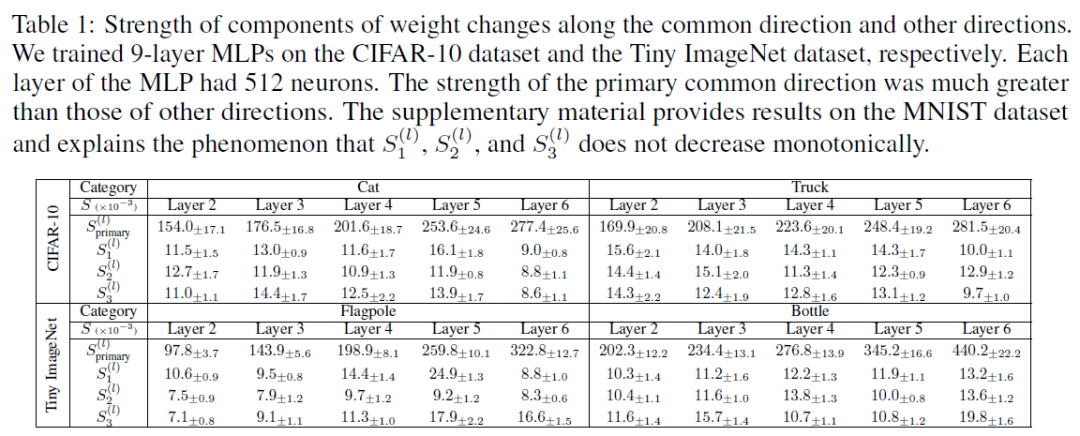
基于这两种分解方式,我们理论上近似证明朝着主方向的优化趋势会进一步增强。

实验验证:图5和图6的实验结果验证了Lemma 3 和Theorem 2的正确性。
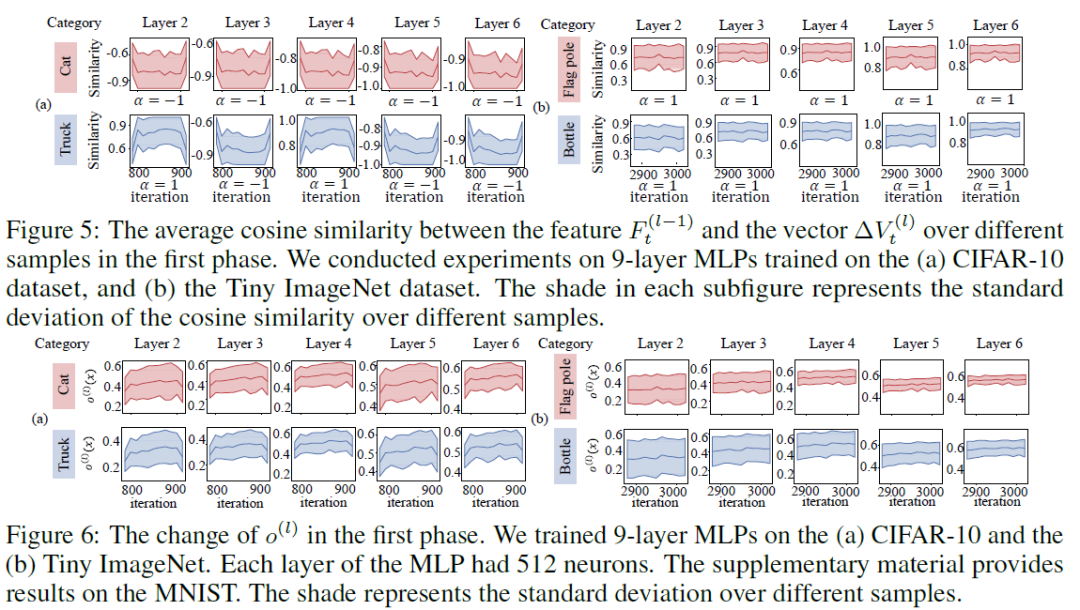
基于进一步增强的主方向,如果我们只考虑同一个类别中的训练样本,那么这些样本的特征将变得越来越相似。另一方面,这些训练样本具有相似的训练效果,即使得不同神经元的权重朝向一个方向移动。
此外,我们在实验中发现,在训练的初期,如下图所示,MLPs只学习到少数类别的信息(一到两个类别)。在这种情况下,所有类别训练样本的总效应是由那些少数类别所决定的。因此,不同类别样本的特征被推向一个公共的方向,那么这些不同类别样本的特征将变得越来越相似。

【理论解释缓解特征多样性下降的现象】
我们发现四种操作(批量归一化, 动量,初始化,以及 L2L_2L_2 正则化)可以缓解特征多样性下降现象,并理论解释了这四种操作有效的原因。尽管在我们理论解释特征多样性下降现象之前,前人的一些操作已经可以消除这个现象,比如批量归一化。但是我们首次从理论上解释特征多样下降这个现象存在的原因,并提供了一些理论指导。这些理论指导可以避免大家在未来应用过程中盲目的去尝试各种操作。
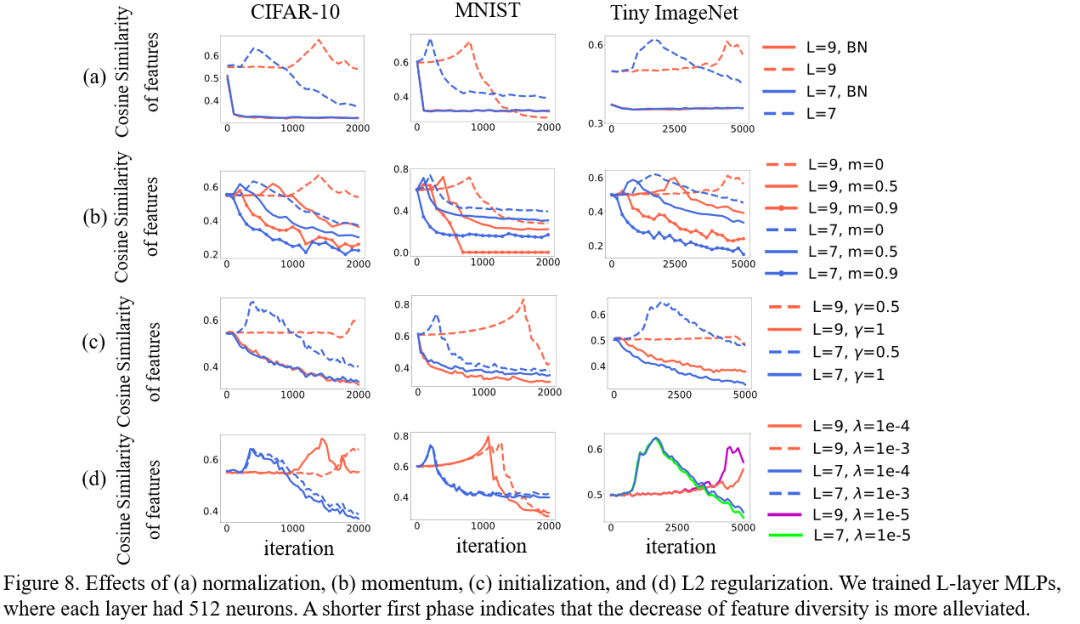
上图的实验结果表明,批量归一化, 动量,初始化,以及L_2正则化,这些操作可以缓解特征多样性下降现象。
作者:李rumor
https://www.zhihu.com/question/320688440/answer/2212714284
《Interpreting Deep Learning Models in Natural Language Processing: A Review》这篇文章描述的「可解释性」,旨在理解模型为什么给出当前的预测结果。从预测结果根据的出处来看,作者把可解释性方法分为三类:
Training-based:从训练数据找根据,比如某条训练样本使得模型将当前测试样本预测为A类
Test-based:从测试数据本身找根据,比如某个词、某个片段
Hybrid-based:同时从训练数据和测试数据找根据
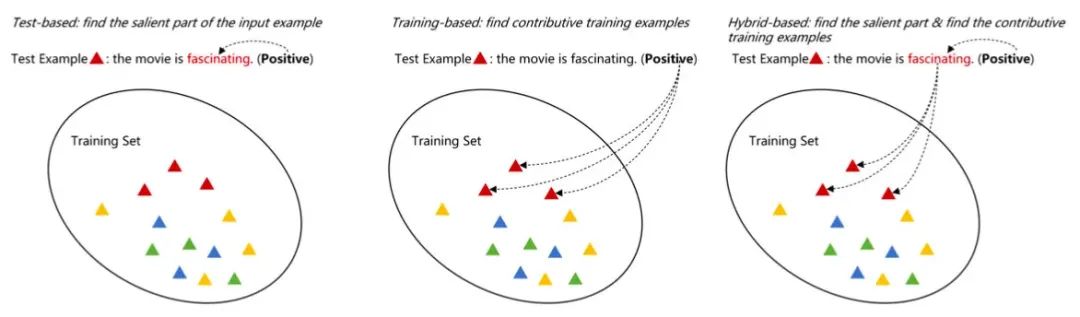
从可解释性方法的使用来看,又可以分为两种:
Joint methods:把负责可解释性的模块加入到模型中一起训练
Pos-hoc methods:在训练后加入可解释性模块
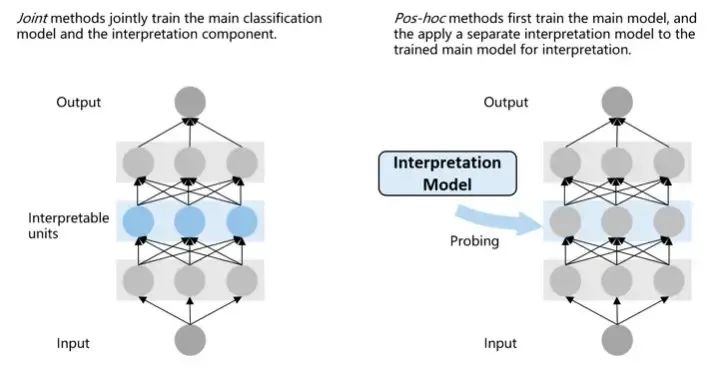
接下来的梳理主要以第一种分类体系为主线,不过作者也同时给出了每个方法的使用方式:
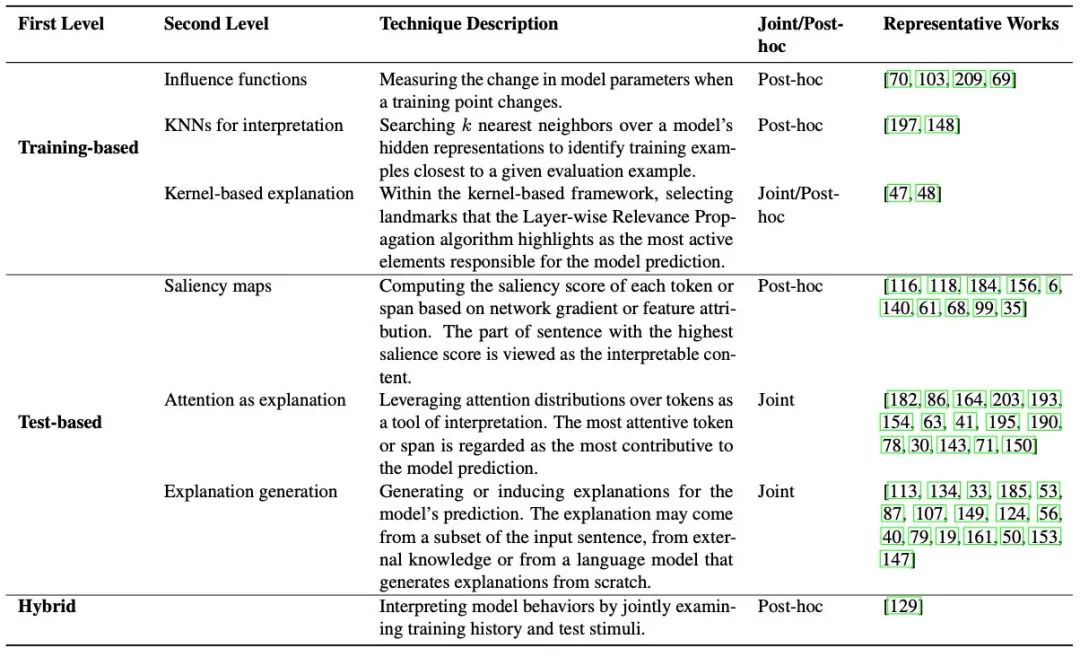
Training-based
Influence Functions
这类方法主要通过一个函数,来衡量训练样本z对于测试样本x的影响。最naive的方法就是去掉z再训练一个模型,但这样测完的时候就可以领盒饭走人了。不过我们有数学呀!于是在计算训练loss的时候,我们可以给样本z的loss加一个扰动,然后就能计算出z对于模型权重的影响,再把x输入进去,就能计算出每个z对每个x的影响情况。
由于公式太复杂,我就不列出来杀大家的脑细胞了。其中有个问题是Hessian矩阵比较难算,对于深度模型简直是灾难。于是又有学者提出了更简单的方法:Turn over dropout。
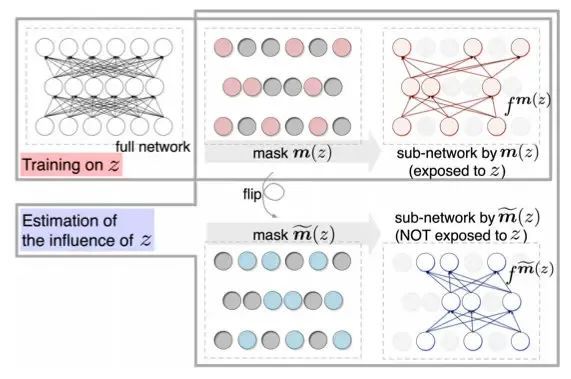
该方法的核心思想是,在训练完模型后,得到每个样本的一个mask矩阵
m(z),应用mask之后可以分离出那些不受样本z影响的神经元。于是我们可以应用矩阵得到两个子网络,再输入x后预测,就能计算出预测的diff。
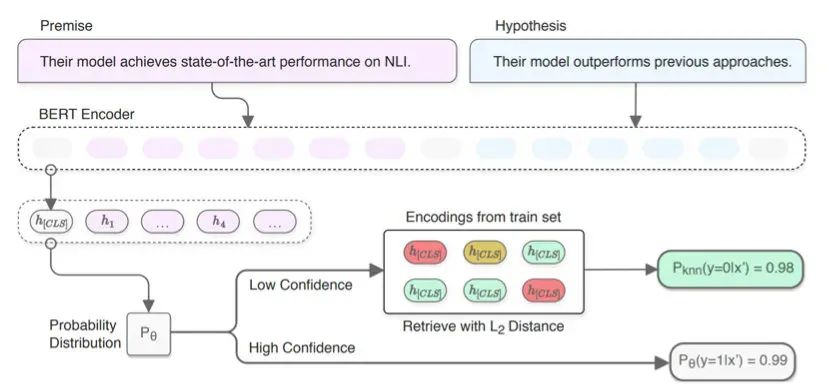
KNNs Based Interpretation
基于KNN的方法旨在通过测试样本的隐层表示找到相近的训练样本。
这个方法理解起来就容易多了,而且很实用。比如我们在做分类任务时,有的测试样本置信度没那么高,这时就可以通过KNN的方法去找相近的TopK个训练样本,根据它们的label分布来帮助预测:
Kernel based Interpretation
这类方法比较老了,参考文献都是18、19年的。具体做法是,先用核函数对预测样本x和多个训练样本l计算相似度K(x,l),之后把相似度矩阵投影成更高维的表示,再输入神经网络进行预测。之后再利用LRP(Layerwise Relevance Propagation)反向计算每层、每个神经元的相关性分数,传导回训练样本那一层就能知道每个样本对测试数据的影响了。
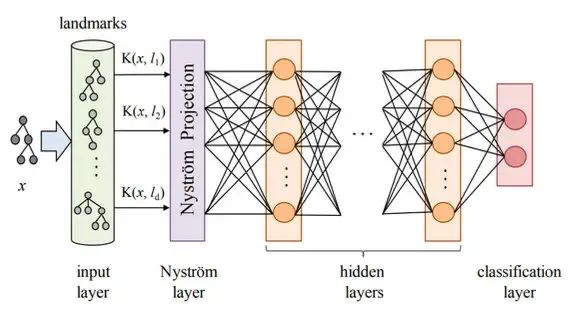
在训练时,Kernel和投影层都是一起训练的,所以这种方法既需要在训练时加入,又需要训练后的计算。
Test-based
Saliency-based Interpretation
这种方法的核心思想是利用一些metric计算测试样本中token、spen的重要程度。作者列出了很多种可以用的metirc:

Attention-based Interpretation
这个相信大家都熟悉了,就是通过观察attention矩阵来分析token的重要程度。
但有意思的事,作者也在参考文献中发现了一些质疑的声音:Attention确实能给可解释性提供帮助吗?
在一篇19年的工作《Attention is not explanation》中,该作者提到,如果注意力权重真的能提供可解释性,那它应该具备两个性质:
注意力权重应该和基于特征的Saliency-based方法有很高的相关性
改变注意力权重会影响预测结果
但是之后,该作者通过一系列的实验,证实attention不具备上述两个性质。所以直到现在(2021年11月),注意力机制是否能提供可解释性这个问题还处于争论之中。
不过该工作的实验是基于BiLSTM+Attention的,仍然有很多基于BERT的实验表明,注意力机制确实学到了不少的语言知识。
Explanation Generation
这个方法就有意思了,上述我们介绍的可解释性方法,对于人类来说可读性都比较弱。而这类方法就要求输出对人类更友好的「解释」。比如:
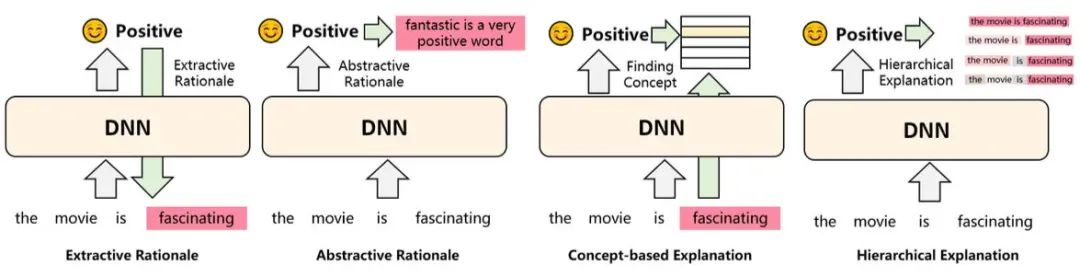
Extractive/Abstractive Rationale:通过抽取或者生成的方式,把样本中对结果影响大的部分输出出来
Concept-based:将预测样本联系到一些抽象概念上,比如在对餐厅的评价中,哪些词语是形容口味的、环境的等等,相当于给出了推理过程
Hierarchical:自底向上分别给句子的每个token、span打分,哪个片段是正向、哪个是负向,也相当于给出了推理过程
总结
可解释性算是一个没那么热的方向,首先是深度模型确实太复杂了、太随机了,有时候自己想的一堆idea都没用,一个bug反而有提升。到了解释的时候全靠猜,可能是哪里分布不一致?或者是模型已经足够强了,我加的输入知识它不需要?其次是大部分人都是结果导向,有时间研究不确定的可解释性,不如花心思在指标提升上。
要说可解释性重不重要,那肯定是重要的。如果对模型的了解更深入,就可以避免一些高风险的badcase。比如风控领域,一个反动内容可能会灭了一家公司,再比如医疗领域,一个错误的预测可能影响患者的生命。
论文的结尾,作者列出了很多的开放问题等待大家探索:
到底怎样才算可解释?
如何评估这些探究可解释性的方法?
是为算法工程师提供解释,还是为看到结果的用户提供解释?
目前的可解释性方法大多研究分类任务,而其他任务呢?
很多可解释性方法提供的结果不一致
是否要牺牲性能获取更高的可解释性?
可解释性方法如何应用?它的价值有多少?
那么最后,深度模型是否真的可解释?这个问题我也没有想清楚,世上无法解释的东西太多了。
作者:晴耕雨读
https://www.zhihu.com/question/320688440/answer/2876991254
本文摘自李宏毅老师的国立台湾大学教学视频。
目前NeuralAI已经发展出许多与大脑十分相似的模型,例如视觉方面的CNN,语言方面的BERT,GPT,学习方面的DeepRL,相关工作证实其不仅在效能上类似甚至超越了大脑,其中间层的某些表征也与大脑的表征有高度的相关性。如果说利用Deep Neural Network代替大脑,是用一个灰箱代替一个黑箱,那么我们就可以对这个灰箱下手来研究其工作原理,这会进一步启发我们了解大脑如何处理信息。因此,深度学习可解释性是一个重要的研究方向。
问题背景
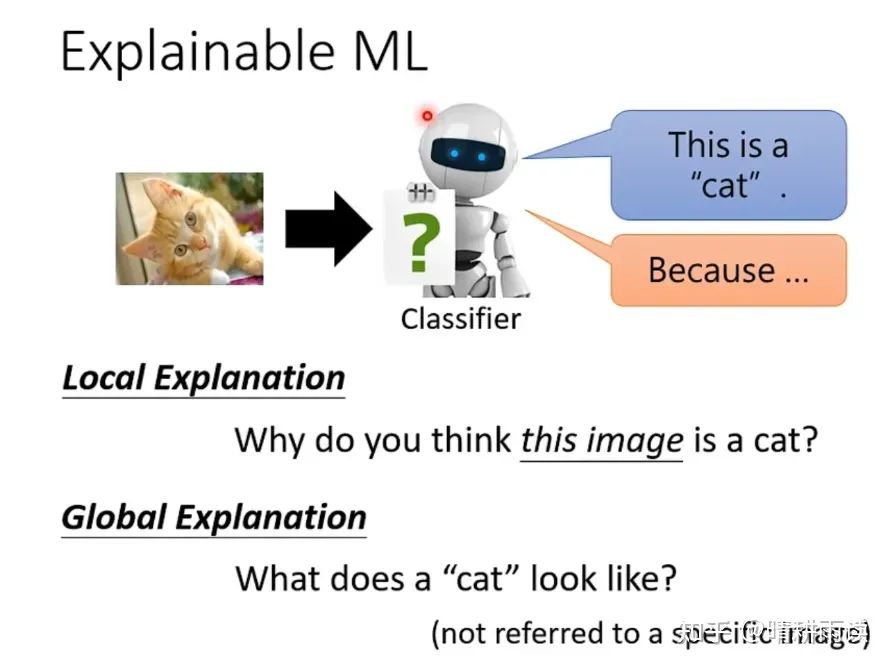
对于一个识别猫的DNN,对它的解释可以分为两种问题:
1)为什么机器认为这是一只猫?或者,这张图片的哪些特征对于分类任务的完成至关重要?(这被称为local Explanation)
2)在机器的眼里,一只猫是长什么样子?或者,在它眼里猫的这个类别对应着怎样的特征?(Global Explanation)
以上两个问题显然是有某些关系的,但我们先不深究,先看看它们的方法。
Local Explanation
第一个最简单的思路是遮挡法,也就是我们挡住图片当中的某些地方,看看机器的正确率是否会下降,例如
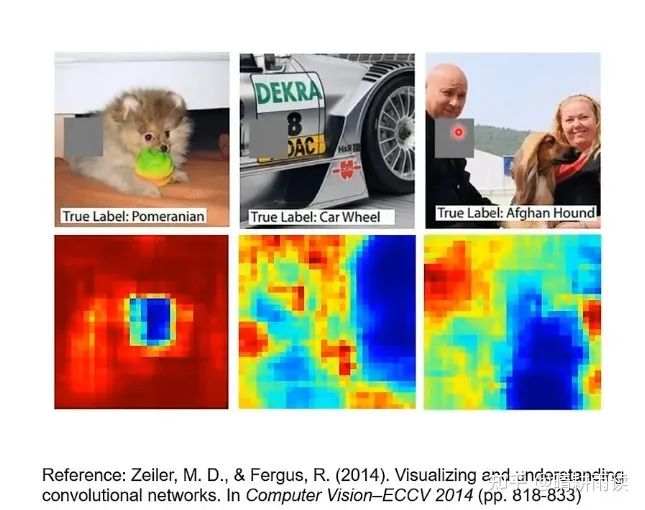
上图中靠上的一行是原始图片,灰色方块表示遮挡的位置,靠下的一行代表灰色方块的位置对识别准确率的影响,蓝色意味着准确率大幅下降,红色意味着准确率几乎不受影响,中间色同理,可以看出,第一张图中狗的面部起到了重要作用,第二张图中的轮子和第三张图中的狗亦然。
第二个思路是求梯度,如下图表示了一个求梯度的过程,左边是某个特征向量,右边是给特征xn加上了Δx,导致loss增加了Δe,两者之比代表了xn对于e的贡献程度,也即e对x的梯度。

对图片中每个点求梯度就可以得到Saliency Map,如下图所示(实际上在pytorch中只要loss.backward()一下就可以得到这个图)。可见机器在某种程度上注意了画面中的重要区域。

Saliency Map也可以帮助我们发现一些分类问题的缺漏,比如机器在下面这个任务中达到了非常高的准确率(分类数码宝贝和宝可梦中的动物),甚至比人高得多(98.4%)
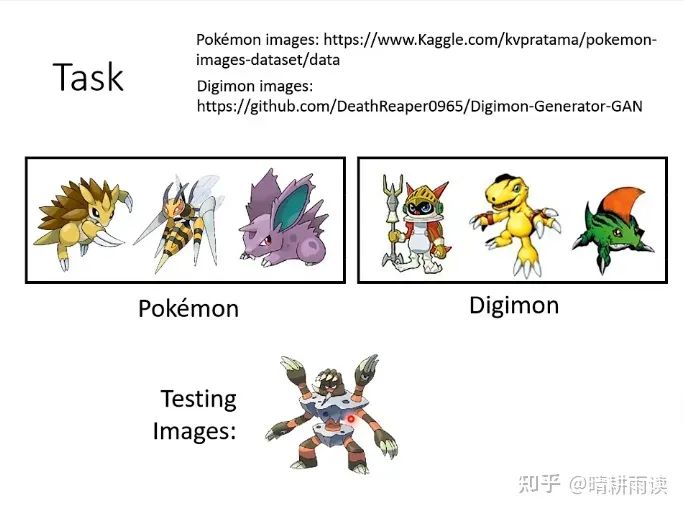
但是画出来它的saliency map却是这个样子(蓝点和绿点是梯度最大的地方)


发现所有的感兴趣区域都在动物之外,这是怎么回事呢?
原来,宝可梦的图片都是PNG格式,数码宝贝的图片都是JPEG格式,当机器读入宝可梦图片的时候,PNG图片的透明背景变成了黑色,具有0的灰度值,而数码宝贝的背景具有255的灰度值,因此机器只要看一下背景就知道是什么动物。机器并没有真正学到如何区分这两种动物。

有时,这种求梯度得到的图片不是很尽如人意,可以采用一种Smooth Grad的方法来平滑化(介绍见英文)

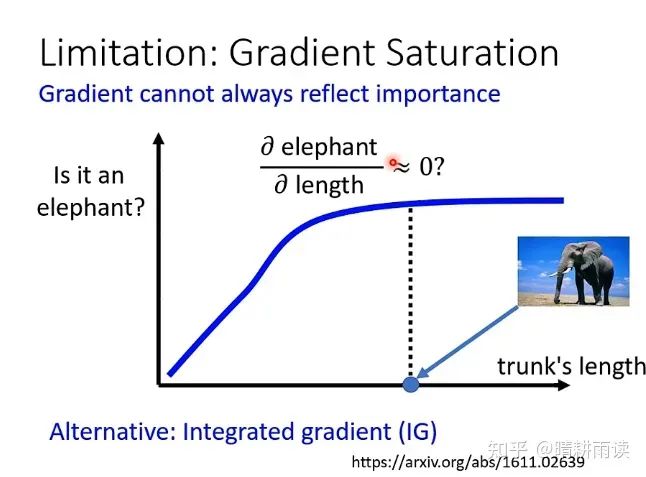
此外,求梯度的方法在理论上也不是完美的,例如对于下边一个根据鼻子长度的动物分类问题。在鼻子长度比较短的时候,鼻子越长它就越像大象,然而在鼻子长度比较长的时候,鼻子再长它也不会更像大象,此时大象概率p对鼻子长度l的梯度很小,证明在鼻子很长的时候,机器不再敏感地关注鼻子的精细长度,而是直接判为大象,然而,这并不能证明鼻子的长度对大象分类任务没用。【老师提到可以采用一种叫做Integrated Gradient的技术】
以上是观察整个输入对结果的影响,其实我们可以直接看每一层的向量是怎样的,来理解机器的行为。
第一种思路,我们可以可视化每一层的输出(利用简单的降维可视化方法PCA,tSNE等,当然也可以用更复杂的例如LLE,autoencoder)
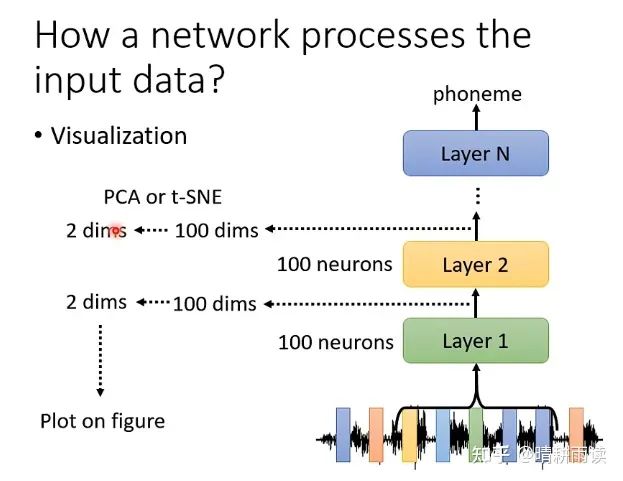
例如对于一个语音识别任务,输入的PCA图和第八层的vector图有很大不同,其中暗示着机器在这八层中处理了某些信息。

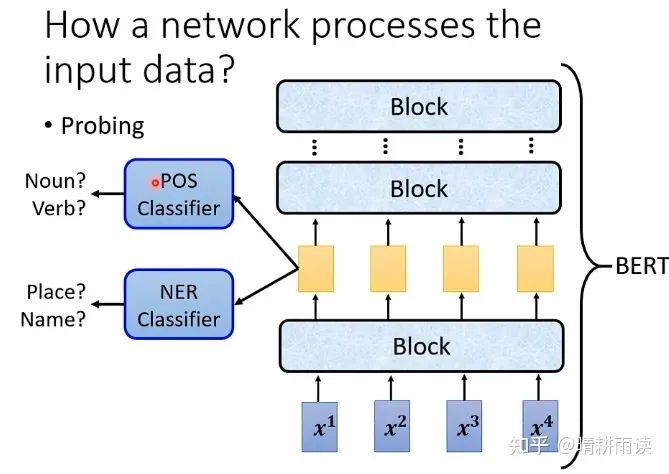
第二种思路,可以采用一种叫做探针(Probing)的技术。下图是BERT语言模型,假设任务是填空(也就是BERT的预训练任务),为了研究一个缺词句子中信息的处理过程,将中间层提取出来,过一个DNN-Classifier。
例如我们可以过一个POS Classifier,并给出标签让它作词性分类任务,假如它的正确率非常高,说明它的输入中已经包含了词性的信息,正确率低说明没有词性信息。也可以过一个NER Classifier,作专有名词的分类任务,同样可以观察这些信息是否包含。需要注意的是,神经网络训练不是很可靠,因此我们不可轻易下否定结论。
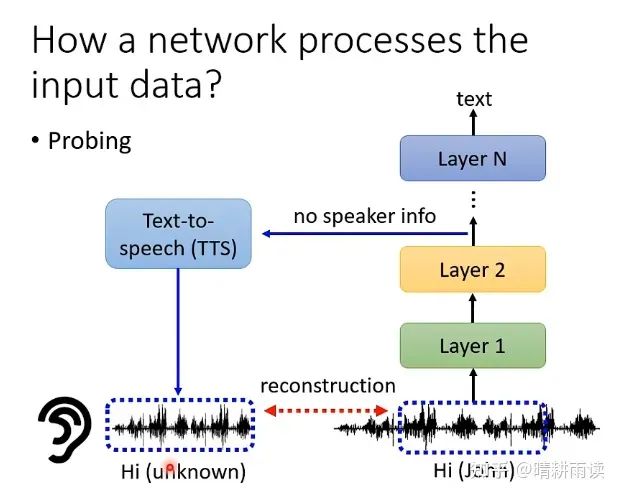
再比如我们可以抽取其中一层作为encoded向量,过一个decoder返回input,看看input和这个decoded向量有什么区别。下图是一个语音转文字的系统,抽取其中的一个向量出来训练decoder重构语音信号,假如这一层的向量已经被去除了说话人的信息,那么无论decoder如何努力也无法恢复说话人的音色。
Global Explanation(对于机器而言一只猫是什么样子的?)
第一个思路是固定神经网络参数,找出使得输出猫的概率最大的输入,也即对噪声图片本身求梯度。这个思路类似神经控制中的寻找最优刺激,通过这种方法可以得知每个神经元(例如L1中的神经元)所喜好的具体输入模式。

上图是对MNIST分类任务第二层的filter求梯度作Gradient Ascent得到的图片,可见这一层是在提取一些边缘信息(类似L2中的神经元)
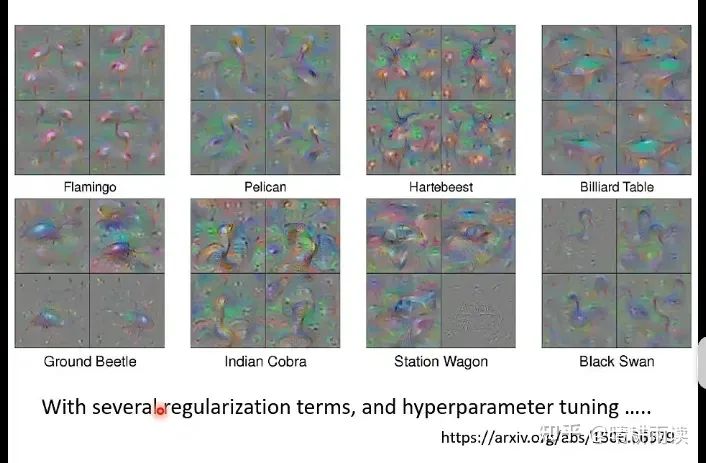
然而直接对结果求梯度不能得到我们想要的图片(规范的数字),而是得到了一堆噪声,这说明机器所理解的图片和我们还不一样,通过对抗攻击可以使得生成的图片越来越接近人眼中的数字。

除了对抗攻击之外,我们也可以选择一个比较简单的方法,例如加上某些正则化项。下图中的R(X)意思是要让图片中的白色区域(灰度值255)尽可能少,以便产生“细条”一样的图片,结果比之前要好。

虽然通过设计正则化项可以得到最优刺激,但是这样的工作往往是繁琐的,因此并不是一种好方法。
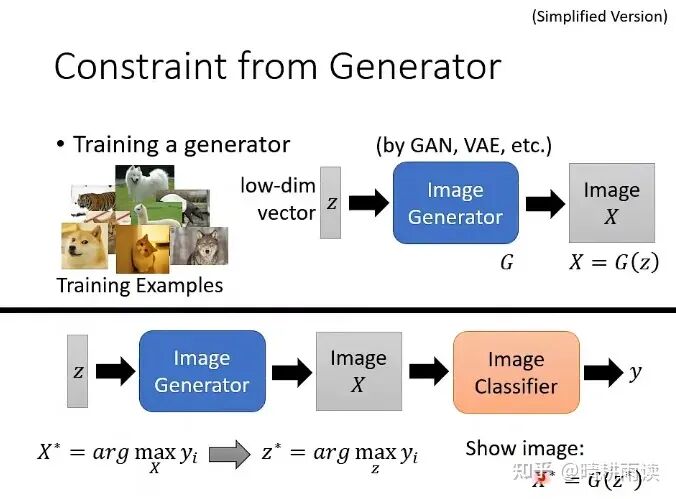
我们可以让这样的约束以神经网络的形式呈现,上图是利用生成器作为约束(令最优刺激X必须是G生成的图片的子集)。我们将Generator和Classifier连在一起,并用设定好的y对z求梯度,得到最优的z,再输出最优刺激G(z*),效果较好。

然而这些图片更接近人的理解,但可能偏离了机器的理解,Explanation究竟是在机器层面还是在人层面可解释呢?这是一个问题。
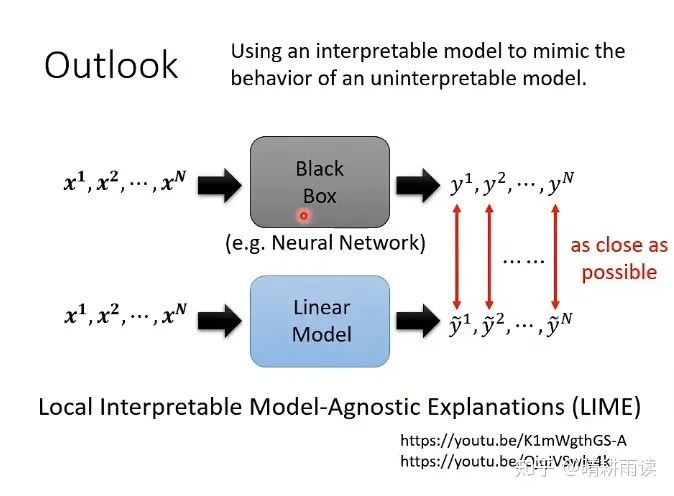
最后还有一种方法,就是利用线性模型在局域拟合非线性模型,线性模型我们可以利用矩阵等工具进行分析,这有点类似泰勒展开。相应的方法叫做LIME。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,
即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~












