
全国首例AI生成声音侵权案件,身为配音师的原告主张60万的损害赔偿,北京互联网法院判了25万。
GPT时代,做AI项目的朋友会认可“AI是一次技术平权”。但技术门槛降低了,却并不意味着创业成本也降低了。最起码,法律合规成本对企业来说就是一项“重要不紧急”且相对“昂贵”的支出。
所以,如何在合规和成本之间,寻找合适的平衡点,就非常考验创业者的智慧与胆识。在这篇文章中,我们将通过对案件进行简要的分析,从别人的血泪教训中,尝试为创业者在监管相对模糊的现阶段,找到适合自己的平衡点。

案情提要
我们先看看这个案件的简图:
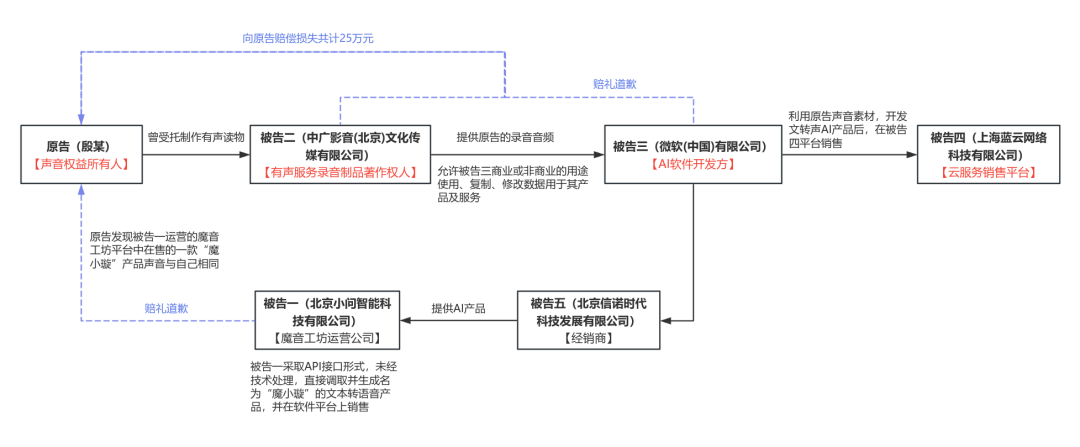
(本案暂未公开判决书,以上简图根据北京互联网法院公开的案件信息绘制[1])
案件太长不看版:
1.原告殷某曾授权被告二中广影音(北京)文化传媒有限公司录制有声读物,中广影音因此享有原告录音制品的著作权。
2.被告二中广影音在未经原告许可的情况下,擅自将原告的声音素材提供给被告三微软(中国)有限公司,并许可被告三微软对原告声音进行商业或非商业的用途使用、复制、修改数据用于其产品及服务。
3.被告三微软在拿到原告的声音素材后,进行人工智能训练,开发了一款文本转语音AI产品,并在被告四上海蓝云网络科技有限公司运营的云服务平台出售。
4.被告一北京小问智能科技有限公司(魔音工坊)从被告五北京信诺时代科技发展有限公司采购了该款文本转语音AI产品,被告一魔音工坊在未采取任何技术处理的情况下,直接以API的形式,调取了该款文本转语音AI产品,并开发了一款名为“魔小璇”的文本转语音产品,在被告一运营的魔音工坊平台出售。
5.最终,法院认定被告二中广影音和被告三微软的行为构成对原告声音权的侵权,应赔偿原告各项损失共计25万元。

(图片由AI生成,你发现了吗?)
你可能会发现以下几个疑问:
1.最终使用了原告声音的魔音工坊,竟然不用赔偿?
2.拥有原告“授权”的中广影音和微软,反而需要赔偿?
3.认定AI生成的声音侵权的标准是什么?
回答了这几个问题,也就吸收了这篇判决书的全部精华,我们一一来解决。

经验教训
1.为什么最终使用了原告声音的“魔音工坊”,不用进行赔偿?
从法院公开的信息上来看,魔音工坊做对了一件事:
“被告一北京某智能科技公司与被告五北京某科技发展公司签订在线服务买卖合同,由被告五向被告三下单采购,其中包括了涉案文本转语音产品。”[2]
魔音工坊的抗辩理由也确实围绕“正规途径合法采购”展开,他们是通过“正规途径”——向被告五北京信诺时代科技发展有限公司采购了该款文本转语音AI产品,也没有对音频进行“技术处理”。因此,在没有其他证据可以证明魔音工坊具有侵权的故意的情况下,应当认定魔音工坊对这些音频具有合法来源,不需要承担损害赔偿责任。
所以,我们得出第一个经验教训:在有条件的情况下,可以向“正规渠道”采购数据(包括文字、音频、图片、视频、肖像等)。
采购价是多少目前也不得而知,但我们大胆猜测一下:单个音频风格的采购价,大概还是不会多于法院判赔的25万的……因此,这道选择题如何做,最终还是得交给项目负责人。
我们无法保证“正规渠道”们的数据一定“正规”,但由于我们采购的行为是合法的,一旦发生争议,你的“合法来源”很可能可以让你免于赔偿。
2.为什么拥有原告“授权”的中广影音和微软,反而需要赔偿?
因为他取得的权限不完整——中广影音得到的授权是作品的著作权授权,但获得了“著作权授权”并不等于得到了“声音的授权”。
在本案中,原告确实曾经受中广影音所托录制了有声读物,但原告并未将自己的声音,一并授权给中广影音。法院对此描述为“不包括授权他人对原告声音进行AI化使用的权利”。简单说就是:中广影音虽然获得了授权,但超过了授权的范围,自然需要对超过范围的使用承担侵权责任。在此情况下,微软仅获得了中广影音的授权,不能认为其具有“合法来源”。
同样的逻辑也适用于作品中附带的“肖像”。所以我们得到第二个经验教训,创业者在起草合同的时候,可以增加一个这样的条款:
“乙方(授权人)保证本次合作过程中产生的图文、音频、视频片段花絮等内容中包含的著作权、肖像权、声音权等内容,均完整地授权给甲方(被授权人),甲方有权在商业宣传、信息网络传播或其他对外活动中利用乙方授权的权利。”
当然这有可能是不够的。如有可能,还应当进一步地将该等作品进行“AI化”的条款,约定到合同中去。内容“AI化”的内涵和外延在现阶段都较为模糊,我们也撰写了一些指引和条款。有需要的朋友,欢迎联系我们交流。
3.认定AI生成的声音侵权的标准是什么?
自“AI孙燕姿”事件以来,关于侵权与否,以前大家只关注“用没用”孙燕姿的声音,现在要考虑“像不像”孙燕姿的声音了。从法院的论述,我们可以确定两个判断的要点:

(图片由AI生成)
(1)以谁的标准来评判“像不像”,即确定进行判断的人群是“相关公众”还是“一般社会公众”。有点遗憾的是,判决书中并未披露过多的判断过程,但这个道理却不难理解:“路人甲的声音”和“86版孙悟空配音的声音”,受众范围明显不同。判断一个声音是否可以被识别为“86版孙悟空配音的声音”的声音,随便找个人就可以进行判断,这是“一般社会公众”的标准;而判断一个声音是否可以被识别为“路人甲的声音”,那么大概只能让他的亲友来判断,才可以得出恰当的结论。
(2)能否通过声音认出声音主人,即声音是否具有“可识别性”。法院认为,自然人声音的可识别性是指在他人反复多次或长期聆听的基础上,通过该声音特征能识别出特定自然人。路人甲的亲友反复地听着路人甲的声音,很容易就可以听出来这个声音是否属于路人甲,这就是可识别性。
所以我们得到第三个经验教训:
不管音频是怎么得到的,如果你不想给自己添麻烦,那么就不要让这个声音听起来太像某个具体的人;这个人越有名,听起来就要越不像。
像Minimax这样的产品,是允许你对音色进行混合的……
我只能说到这个程度了……

多聊几句
从目前已经公开的“文生图”的两个案件、AI生成声音第一案可以看出,各法院对人工智能生成物的保护或生成物侵权的处罚,都主要聚焦在人工智能“生成”内容上。对于人工智能训练数据是否侵权的问题,暂时还没有司法实践的结论可供参考,这就给创业项目提供了一定程度的灰度。
正如开篇所说,如何在合规和成本之间,寻找合适的平衡点,非常考验创业者的智慧与胆识。我们也会长期输出,帮助创业项目寻找“答案”,欢迎交流。
最后,还有一个问题:为什么都是买来的数据,微软要赔偿25万,魔音工坊却有可以因为有“合法来源”而不用赔偿呢?
评论区留下你的“声音”。
[1]《北京互联网法院审理全国首例“AI声音侵权案”》,北京互联网法院,https://mp.weixin.qq.com/s/4eg9tb3AAMsEiXph_kihXw
[2]《全国首例AI生成声音人格权侵权案一审宣判》,北京互联网法院,https://mp.weixin.qq.com/s/_GxGaG6Q2NYHJWQuOtMyrQ
作者简介
陈焕律师,《法律人ChatGPT应用指南》作者,北京市隆安(广州)律师事务所律师、隆安湾区人工智能法律研究中心主任、隆安广州数字经济部副部长、国家工业信息安全发展研究中心《生成式人工智能数据应用合规指南》团体标准起草人。
李琪瑶律师,华南理工大学法律硕士研究生,英语专业八级。现为北京市隆安(广州)律师事务所律师,隆安湾区人工智能法律研究中心研究员。李琪瑶律师擅长人工智能、数据合规、知识产权诉讼和非诉业务、民商事争议解决事务。
《法律人ChatGPT应用指南》,可直接点击下图购买:
《法律人ChatGPT应用指南》作者
隆安湾区人工智能法律研究中心主任
隆安广州数字经济部副部长
*链接100位AIGC从业者,共创AIGC合规书籍,让AI+法律赋能百业千行。扫描添加作者微信,请备注姓名+单位。










