架构师大咖
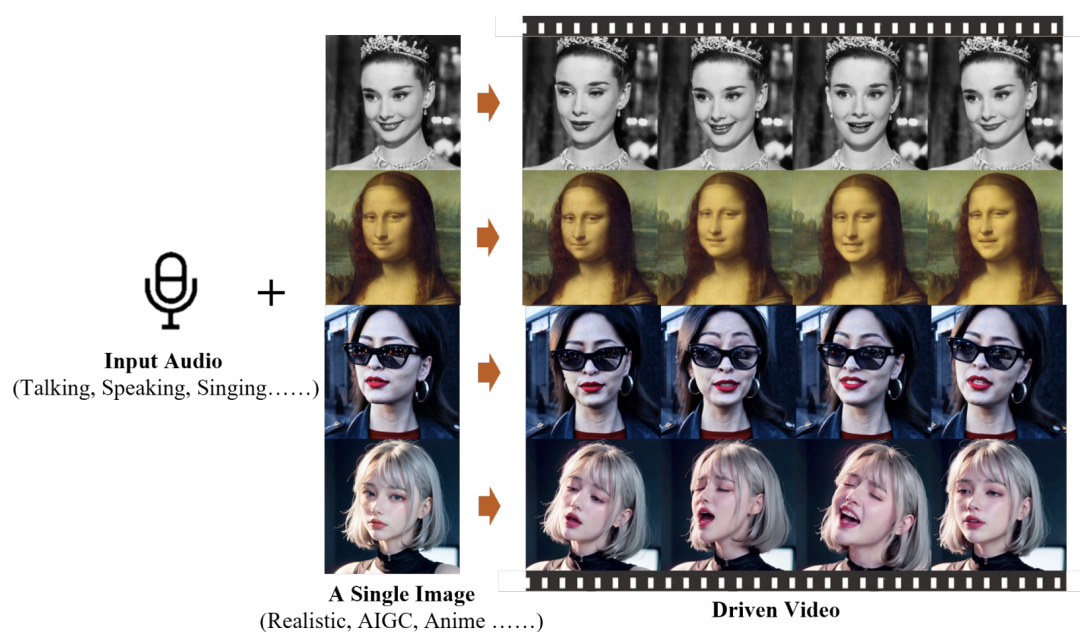
架构师大咖,打造有价值的架构师交流平台。分享架构师干货、教程、课程、资讯。架构师大咖,每日推送。一张人物照片+一段音频,在一款名为 EMO 的图生视频 AI 新系统里走一遭,就能让照片里面人“唱起来歌”来...
就像这样:
或者这样:
还有这样:
不难看出,视频中唱歌、讲话时的人物神态灵活灵现,口型也颇为一致,毫无违和之感,就像是真人拍摄似的。对此,仅是在看到演示之后,不少网友纷纷发表感慨:“这是我见过最令人惊叹的音视视频。”

观其背后,这款新模型 EMO 全称为 Emote Portrait Alive,出自阿里巴巴智能计算研究院(Alibaba's Institute for Intelligent Computing)四位研究员即 Linrui Tian、Qi Wang、Bang Zhang 和 Liefeng Bo 之手。
对此,该团队也在 arXiv 上发表了一篇主题为《EMO: Emote Portrait Alive - 在弱条件下利用音频视频扩散模型生成富有表现力的肖像视频》(https://arxiv.org/pdf/2402.17485.pdf)研究论文中进行了详尽地分享技术细节,EMO 这款 AI 框架能够在单张人像照片的基础上创造出一些极具表现力的面部动作和头部姿势,这些动作和姿势与所提供音轨非常吻合,并以极其逼真的方式生成人物说话或唱歌的视频。

直接将音频+图片转换为视频的 EMO
不同于 OpenAI 的文生视频模型 Sora,EMO 主攻的就是直接以图+音频生成视频的方向。
据论文介绍,EMO 模型采用了 Stable Diffusion 的生成能力,能够直接从给定的图像和音频剪辑合成人物头部视频。这种方法消除了中间表示或者复杂预处理的需要,同时,它利用自动编码器 Variational Autoencoder (VAE)将原始图像特征分布 映射到潜空间
映射到潜空间 ,将图像编码为
,将图像编码为 ,并将潜特征重建为
,并将潜特征重建为 。这种架构的优点是既能降低计算成本,又能保持较高的视觉保真度。
。这种架构的优点是既能降低计算成本,又能保持较高的视觉保真度。
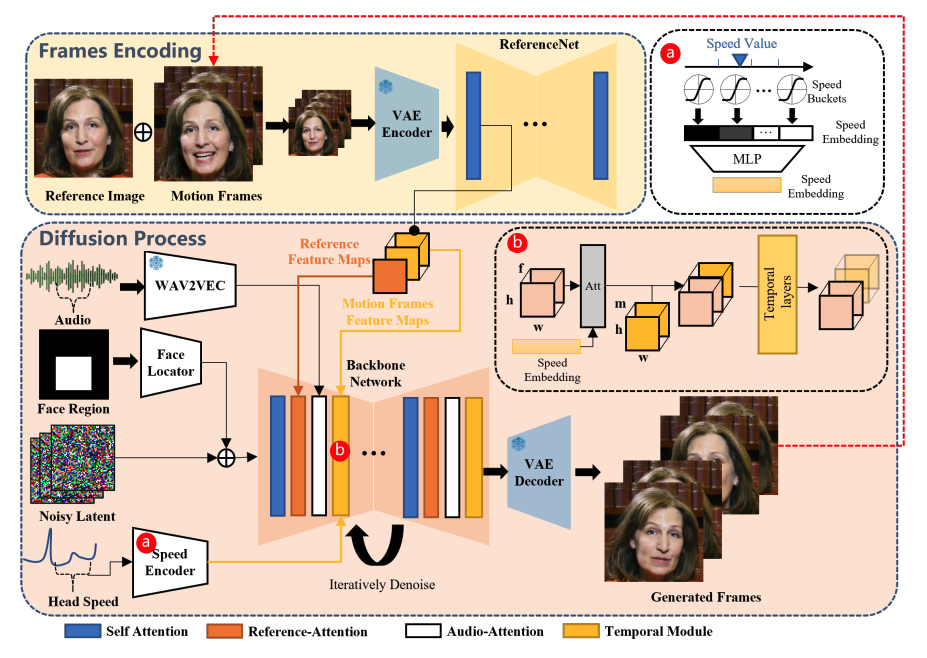
整体来看,EMO 框架设计主要分为两个阶段。
在初始阶段,也可以称之为帧编码(Frames Encoding),部署 ReferenceNet 被用来从参考图像和运动帧中提取特征。
随后,在扩散处理阶段,预训练音频编码器处理音频嵌入。这种方法将面部区域掩码与多帧噪声相结合,用来控制面部图像的生成。进而,使用骨干网络来促进去噪操作。在骨干网络中,应用了两种形式的注意力机制:参考注意力和音频注意力。这两种机制分别对保持人物身份和调节人物动作至关重要。此外,时态模块还可用于操控时间维度和调整运动速度。

训练策略
为了训练模型,研究人员构建了一个庞大而又多样化的音频视频数据集,包含 250 多个小时的演讲、电影、电视节目、歌唱表演,也涵盖多种语言,如中文和英文。
这款模型的训练过程分为三步:
第一阶段是图像预训练,在这一阶段,Backbone Network、ReferenceNet 和Face Locator 都要进行标记训练。在这个阶段,Backbone Network 将单帧图像作为输入,而 ReferenceNet 则处理从同一视频片段中随机选择的不同帧图像。Backbone 和 ReferenceNet 都从原始 SD 初始化权重。
在第二阶段,研究员将引入视频训练,在这一阶段,时序模块和音频层被纳入其中,从视频片段中采样 n+f 个连续帧,其中开始的 n 个帧为运动帧。
时间模块从 AnimateDiff 中初始化权重。在最后一个阶段将整合速度层,在这一阶段只训练时间模块和速度层。这一战略决策有意将音频层排除在训练过程之外。因为说话角色的表情、嘴部动作和头部运动的频率主要受音频的影响。因此,这些元素之间似乎存在关联,可能会促使模型根据速度信号而不是音频来驱动角色的动作。
研究团队表示,其实验结果表明,同时训练速度层和音频层会削弱音频对人物动作的驱动能力。

测试结果
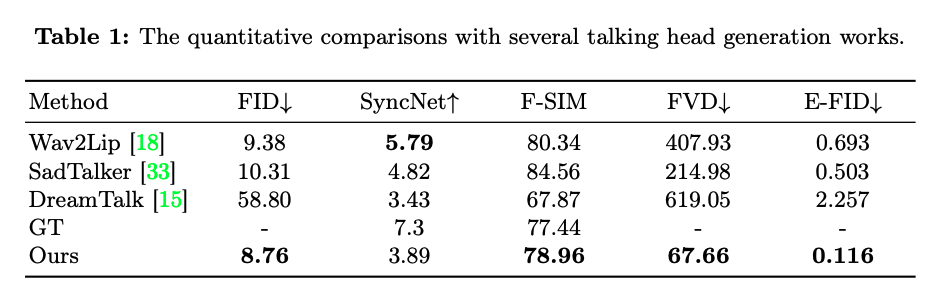
当然,EMO 也并不是第一个基于扩散模型可以让人物照片说话的技术。基于此,该研究团队还将这一模型与业界已有的 DreamTalk、Wav2Lip、SadTalker、GT 框架进行了比较。
其中,Wav2Lip 通常会合成模糊的口腔区域 ,并在提供单个参考图像作为输入时,产生静态的头部姿态等特征。另外以 DreamTalk 为例,作者提供的风格剪辑可能会扭曲原始面孔,也会限制面部表情和头部运动的动态。
研究人员表示,EMO 能够产生更大范围的头部运动和更动态的面部表情。

参数结果比较如下:
除此之外,研究人员基于不同肖像风格演示了 14 个生成的视频剪辑,其中的字符是由相同的声音音频剪辑驱动。

根据论文中描述的实验,在衡量视频质量、身份保持和表现力的指标上,EMO 明显优于现有的最先进方法。研究人员还发现 EMO 生成的视频比其他系统生成的视频更自然、更富有情感。

零代码上线 GitHub,EMO 在开源上引发巨大争议
不过,EMO 备受关注的同时,也被推向了舆论的风口。
事情源于研究团队在发布 EMO 论文、官网的同时也给出了一个 GitHub 地址:https://github.com/HumanAIGC/EMO。然而,当网友欣喜若狂地打开此地址时,却遗憾地发现代码托管平台上关于 EMO 项目的代码却为零。
因此,在 EMO 上线的短短几天间狂揽超 4k 的 Star 数时,不少人开始质疑它究竟是真开源还是闭源的,如果是开源的,为何没有代码;如果是闭源的,又为何要在 GitHub 上建立一个空仓。
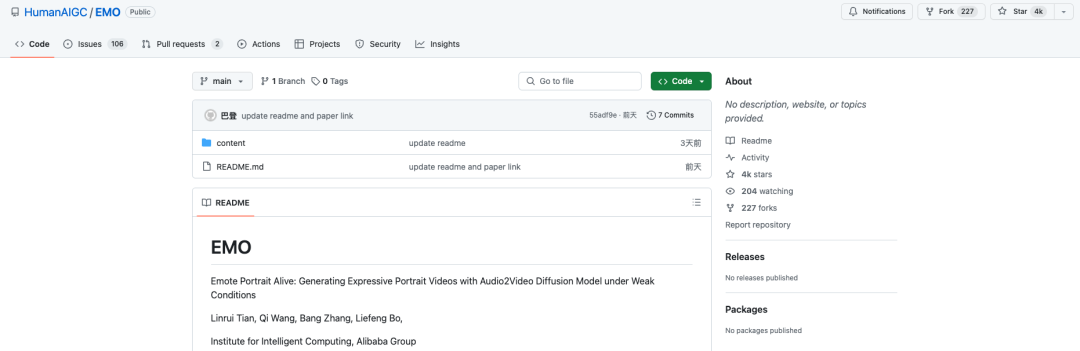
对此,国外用户直接在 X 社交平台批评道,“代码尚未公开,从最近一些回购协议的趋势来看,它永远不会公开。似乎有些开发人员正在使用 Github 作为平台来获得一些广告/关注/Star,却从不澄清为什么他们不发布源代码。”
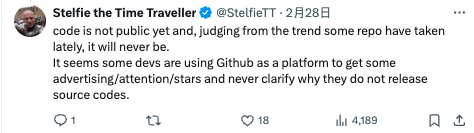
更有大批网友涌入 GitHub Issues 上,希望有一个合理的解释:
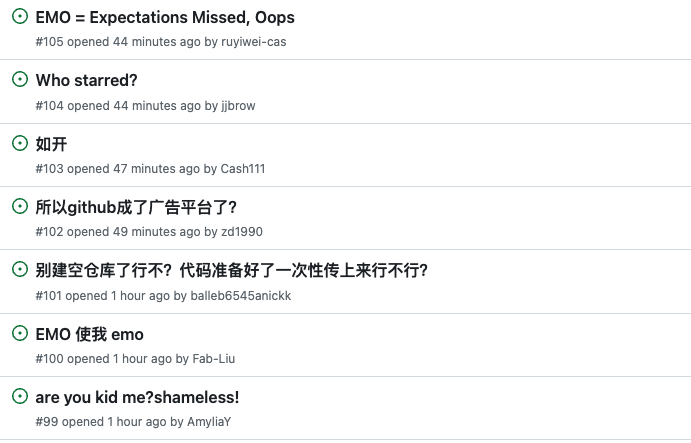
截至目前,该团队尚未有明确的回应。但不可否定的是,EMO 的研究预示着,未来只需一张照片和一段音频片段就能合成个性化的视频内容。
然而,人们仍然担心这种技术可能会被滥用,在未经同意的情况下冒充他人或传播错误信息。研究人员表示,他们计划探索检测合成视频的方法。
更多细节可查阅完整论文:https://arxiv.org/abs/2402.17485
Python入门到精通
Python入门到精通:人生苦短,我用Python!Python每日推送、Python教程、Python资料、Python视频、Python项目、Python学习等。









