在生物催化领域,蛋白质工程已成为调控酶的稳定性、催化活性和选择性的重要工具。然而由于实验筛选过程耗时耗力,想要完全探索巨大的蛋白质突变空间是不现实的。因此人们开发了定向进化以及理性设计等方法,用以通过有限的筛选有效地找到更好的突变体,但这两种方法通常只能搜索部分突变空间,导致错过大量性能优异的突变体。随着人工智能革命影响到人类生产和生活的各个方面,传统的研究模式也在发生着根本性的变化。具体到生物催化领域,机器学习(ML)已被用于蛋白质的理性改造,从而调节诸如环氧化物水解酶、还原胺化酶等生物催化剂的催化活性或立体选择性。这种数据驱动的策略可以通过从收集的数据中识别催化模式,来设计新的突变组合,因此该策略有望大大减少传统策略所需的计算和实验工作。
在前期的研究中,中国科学院化学研究所敖宇飞副研究员,德国Greifswald大学U. T. Bornscheuer教授,以及北京师范大学理论及计算光化学教育部重点实验室申林教授合作建立了转氨酶3FCR的催化活性和选择性机器学习模型(Angew. Chem. Int. Ed. 2023, 62, e202301660)。他们利用基于结构的理性改造策略快速获得多样性高的催化性能数据,并设计出一套改进型独热(one-hot)描述符,用以描述底物和氨基酸的电子效应和位阻效应;在此基础上建立梯度提升回归树(GBRT)模型,成功地预测了转氨酶3FCR催化不同底物反应的活性和立体选择性,进而不断加入新的数据,提升机器学习模型性能;此外还将其应用于设计具有更高催化性能的突变体,展示了数据驱动的蛋白质工程的应用潜力。
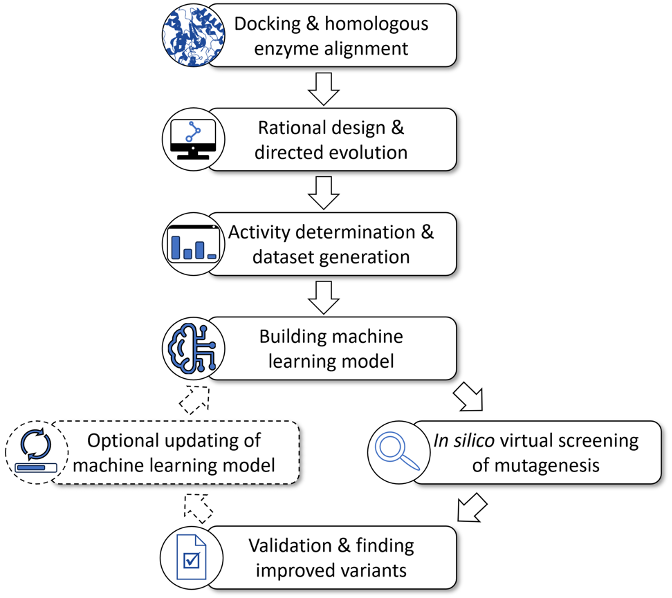
尽管这些例子证明了 ML 方法与传统蛋白质工程方法相比在理论和策略上的优势,但该方法的实用性仍然不足。一个主要问题是,机器学习模型只能通过在大型数据集上进行训练来建立,而大型数据集通常需通过深度突变扫描(DMS)等费时费力的试验来收集。因此,我们设想了一个实用的蛋白质工程研究范式,在这个过程中,ML 方法不是定向进化和理性设计的竞争方法,而是它们的重要补充(图 1)。具体来讲,首先依靠传统的定向进化和理性设计方法获得具有良好催化性能的变体,利用在此过程中获得的实验数据建立目标底物的 ML 模型,将其应用于设计更好的变体,并通过不断迭代提升模型预测精度。