点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

1 课题背景
关于对疲劳驾驶的研究不在少数, 不少学者从人物面部入手展开。人类的面部包含着许多不同的特征信息, 例如其中一些比较明显的特征如打哈欠、 闭眼、 揉眼等表情特征可用来作为判断驾驶员是否处于疲劳状态的依据。随着计算机技术的不断发展, 尤其是在人工智能相关技术勃发的今天, 借助计算机可以快速有效的识别出图片中人脸特征, 对处于当前时刻驾驶员的精神状态做出判断, 并将疲劳预警信息传达给司机, 以保证交通的安全运行, 减少伤亡事故的发生。
2 实现目标
经查阅相关文献,疲劳在人体面部表情中表现出大致三个类型:打哈欠(嘴巴张大且相对较长时间保持这一状态)、眨眼(或眼睛微闭,此时眨眼次数增多,且眨眼速度变慢)、点头(瞌睡点头)。本实验从人脸朝向、位置、瞳孔朝向、眼睛开合度、眨眼频率、瞳孔收缩率等数据入手,并通过这些数据,实时地计算出驾驶员的注意力集中程度,分析驾驶员是否疲劳驾驶和及时作出安全提示。
3 当前市面上疲劳驾驶检测的方法
学长通过对疲劳驾驶在不同方法下研究进展的分析, 可以更清晰的认识的到当下对该问题较为有效的判定方法。根据研究对象的不同对检测方法进行分类, 具体分类方法如图
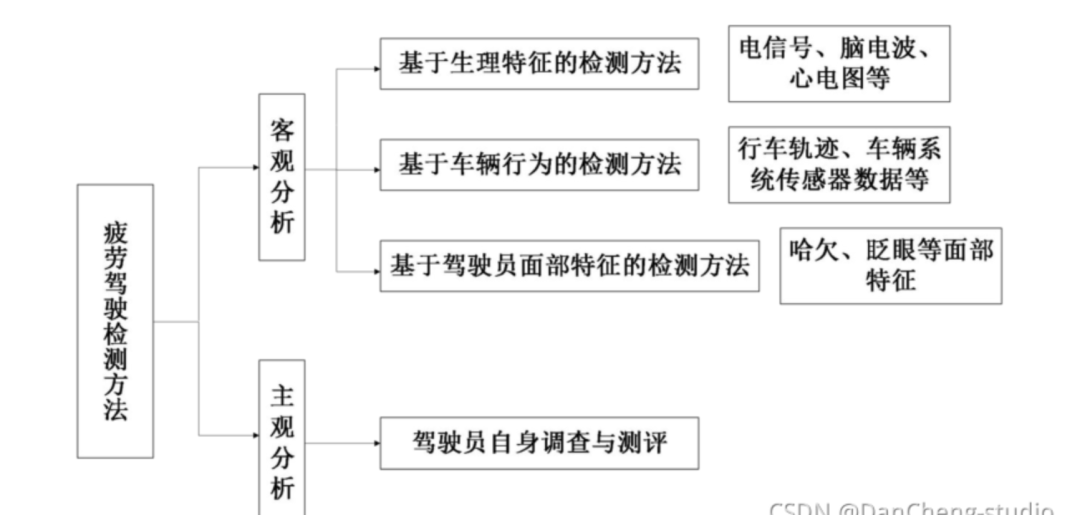
基于驾驶员面部特征的检测方法是根据人在疲劳时面部变化来分析此时的精神状态。人在瞌睡、 疲劳时面部表情与清醒时有着明显的区别。通过装置在车辆中的摄像头对驾驶员人脸图片的采集, 利用计算机图像处理和模式识别, 可以有效检测驾驶员的疲
劳特征信息, 比较直观的特征有:打哈欠, 眨眼, 低头等。
4 相关数据集
学长收集的疲劳检测数据集
驾驶疲劳人脸数据库图片来源分为 3 部分, 每部分均包含疲劳、 轻度疲劳和非疲劳三种精神状态类别。样本数据库共 4800 张图像, 其中疲劳状态有 1622 张数据样本, 轻度疲劳有 1506 张数据样本, 非疲劳状态有 1618 张数据样本。各部分数据结构如下:网络采集部分疲劳包含 435 张样本图片, 轻度疲劳状态包含 430 张样本图片, 非疲劳状态包含 432 张样本图片, 共 1297 张样本数据图像;视频数据库采集部分疲劳状态包含 1037张样本图像, 轻度疲劳状态包含 1030 张样本图片, 非疲劳状态包含 1036 张样本图片,共 3103 张样本数据图像;

5 基于头部姿态的驾驶疲劳检测
5.1 如何确定疲劳状态
5.2 算法步骤
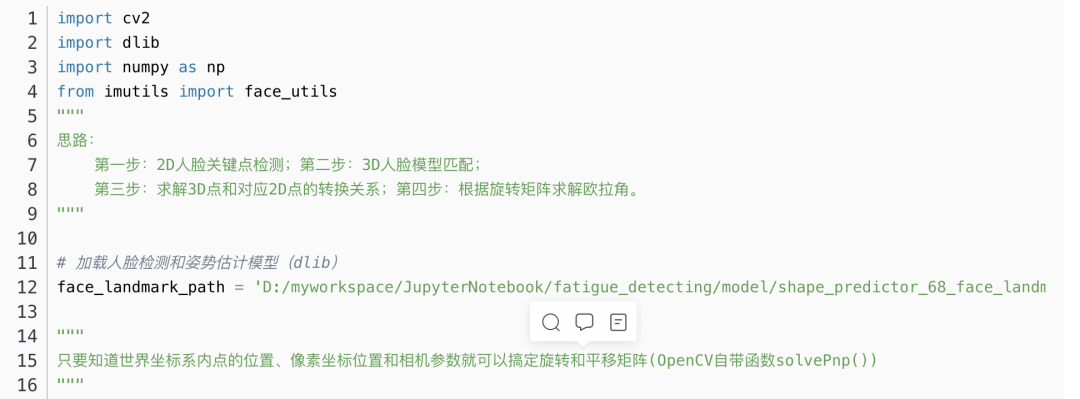
第一步:2D人脸关键点检测;
第二步:3D人脸模型匹配;
第三步:求解3D点和对应2D点的转换关系;
第四步:根据旋转矩阵求解欧拉角。

5.3 打瞌睡判断
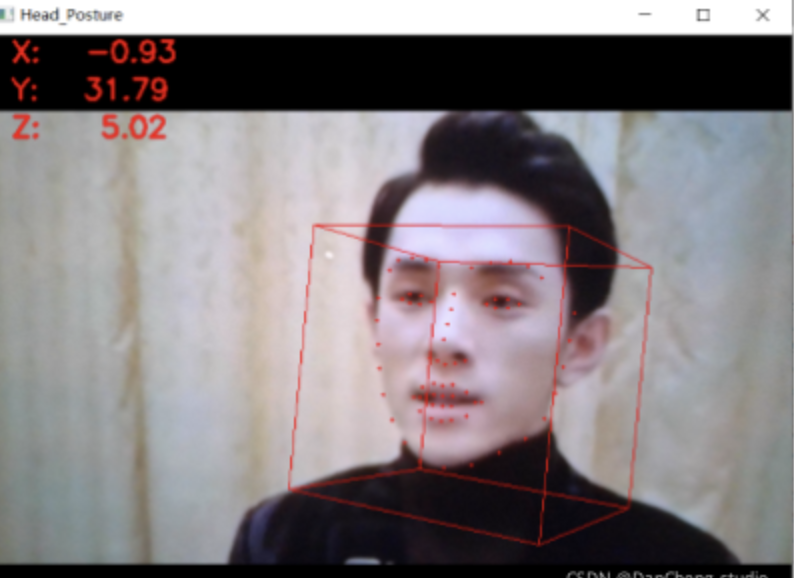
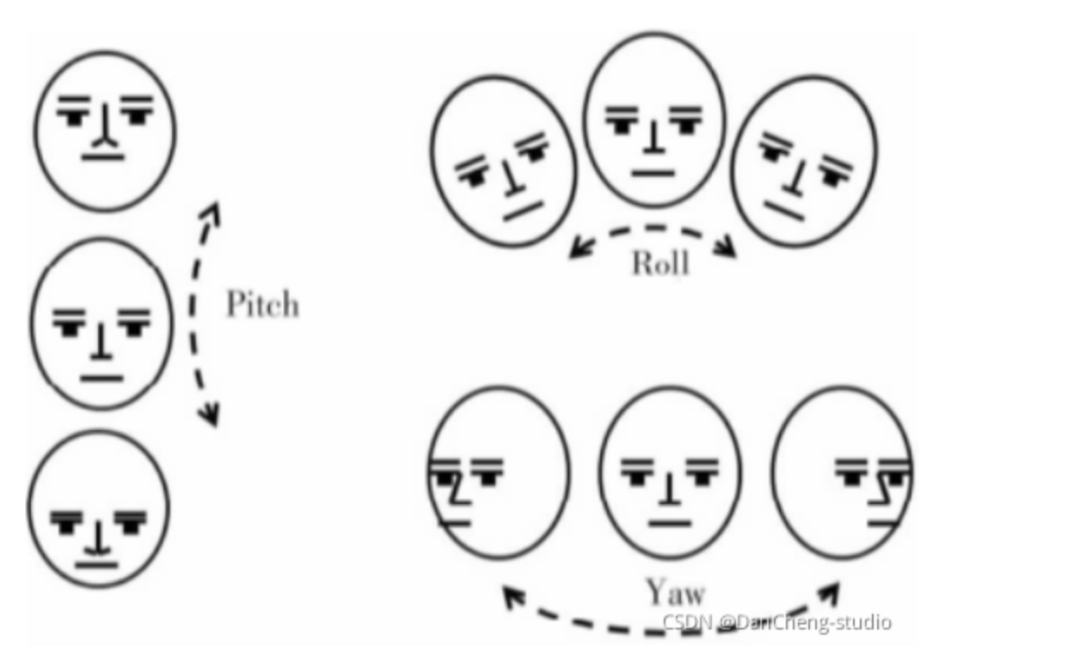
头部姿态判断打瞌睡得到实时头部姿态的旋转角度过后,为头部旋转角度的3个参数Yaw,Pitch和Roll的示意图,驾驶员在打瞌睡时,显然头部会做类似于点头和倾斜的动作.而根据一般人的打瞌睡时表现出来的头部姿态,显然很少会在Yaw上有动作,而主要集中在Pitch和Roll的行为.设定参数阈值为0.3,在一个时间段内10 s内,当I PitchI≥20°或者|Rolll≥20°的时间比例超过0.3时,就认为驾驶员处于打瞌睡的状态,发出预警。

6 基于CNN与SVM的疲劳检测方法
6.1 网络结构
学长将卷积神经网络作为特征提取器, 支持向量机作为分类识别器并通过串联将两者结合 , 构造理想的深度识别模型, 提高对驾驶员疲劳的识别准确率。本次课题主要以实现提高识别精度为目的, 设计使用的特征提取网络结构中卷积层、 池化层以及全连接层个数均为两层;在网络的结尾处添加一层支持向量机作为识别分类器;
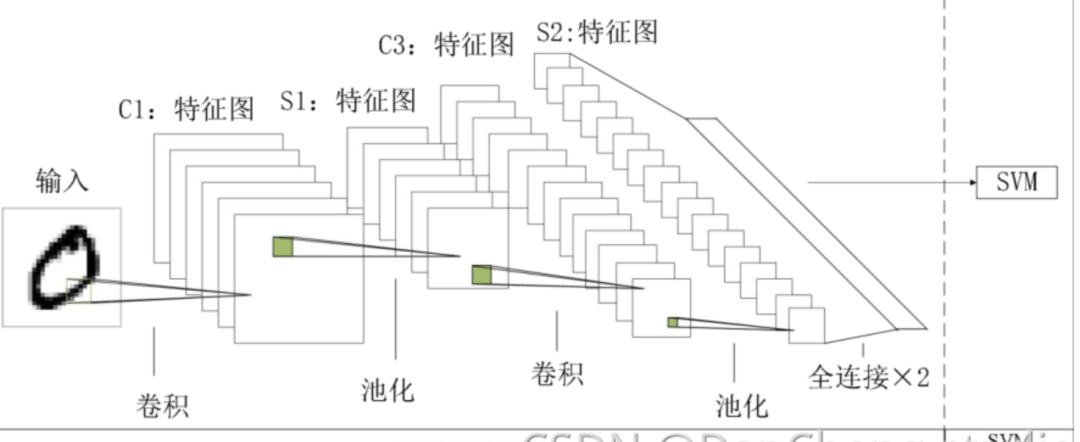
根据对卷积神经网络的描述, 这里设计使用的网络结构为:输入层、 二层卷积层、 二层池化层、 二层全连接层以及 SVM 分类器组成的卷积神经网络对采集数据进行实验。
可将网络视为三个部分, 数据输入部分即网络输入层, 为特征提取部分由卷积层和池化层构成, SVM 为分类识别部分;三部分网络串联出整体识别框架, 且相互间约束不大, 为后续优化工作提供了条件。
6.2 疲劳图像分类训练
网络的训练由于数据量较大进行实验时将数据分为多个批次, 每个批次中含有 20张图像, 经过前向、 反向传播后更新网络参数, 训练出误差合适的网络。测试时, 图像由网络进行识别, 根据得到的识别正确率来验证网络的可行性。
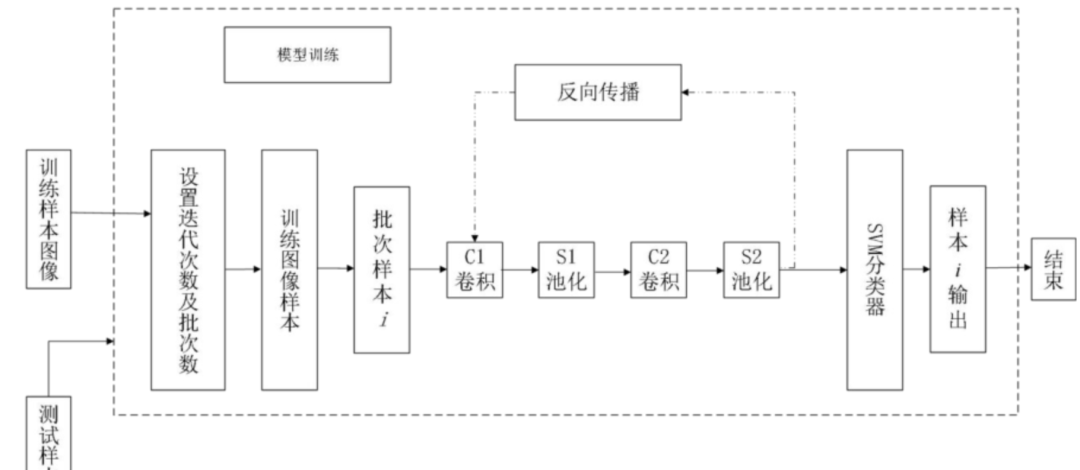
疲劳驾驶检测需对网络进行训练, 在保证网络训练准确率达到一定精度后即可对图像进行判别;疲劳驾驶网络训练算法过程如下:
Step1:网络初始化:初始化网络学习率η, 在数值范围[0, 1]中随机初始化网络参数权值及偏置值;设置网络结构:卷积核大小为 5×5, 每批次样本数量 20;
Step2:随机选择数据库内面部表情图像并依次输入网络, 网络按照送入每一批次的图像进行训练;
Step3:网络将训练得到的输出值同图像期望值进行比较, 计算出输出误差;
Step4:根据反向传播原理将误差反向传播计算, 并调整网络参数权值和偏置值;
Step5:判断迭代次数, 达到期望的迭代步数后转到 Step6, 否则转到 Step3;
Step6:将 CNN 提取到的图像特征传入 SVM 中进行训练;
Step7:结束。
6.3 训练结果
学长将对建立起的数据集进行实验, 实验中分别在每一批次下对识别正确和错误个数进行统计, 然后同批次中图片数量相比, 得出最终的准确率和损失率(错误率) 。
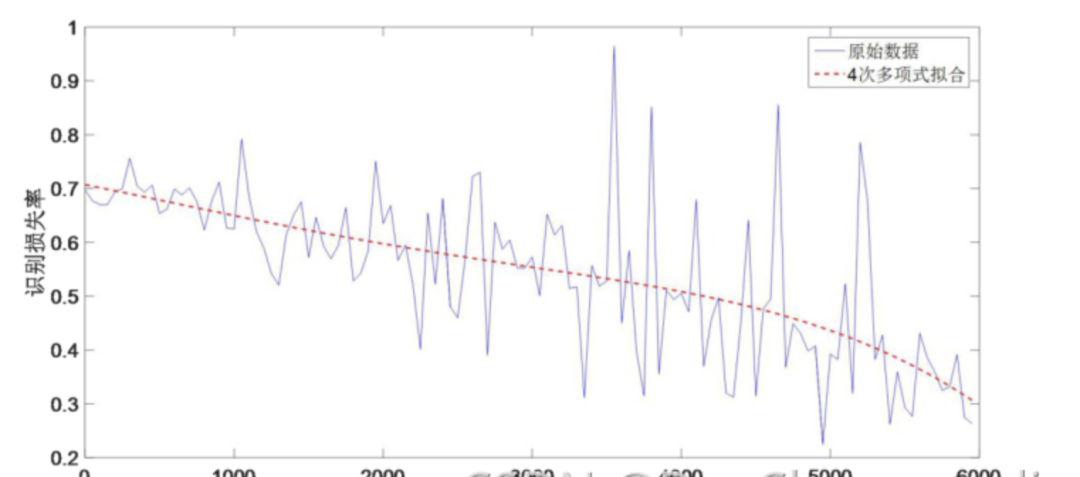
模型测试结果

原文地址 https://blog.csdn.net/HUXINY/article/details/121307646
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~












