本文为知乎网友的咨询,经同意后发布。
在本文中,我们将探讨如何使用Python和Pandas库来提取出租车行程数据。这个过程涉及到数据清洗、行程识别、以及行程信息提取等多个步骤。我们的目标是从原始的出租车定位数据中提取出每个行程的起始和结束时间、地点以及行程距离等信息。
1、数据源
本次示例数据来源:由Desheng Zhang, Rutgers University[1]发布,名为Urban Data Release V2,本文选取544998条Taxi GPS数据。
使用以下代码读取:
path = "./data/TaxiData-Sample.csv"
data = pd.read_csv(path)
# 定义列名
data.columns = ['VehicleNum', 'Time', 'Lng', 'Lat', 'OccupancyStatus', 'Speed']
data.head()
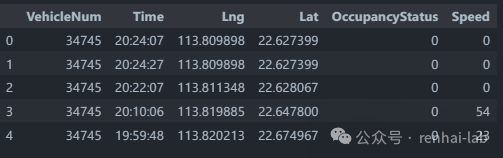
2、数据预处理
在开始提取行程之前,首先需要对数据进行预处理,确保数据的质量和准确性。这包括处理缺失值、检查数据类型、去除重复记录、处理异常值以及数据格式化等步骤。例如,时间戳需要转换为标准的日期时间格式,以便于后续的处理。
# 检查缺失值
missing_values = data.isnull().sum()
# 检查数据类型
data_types = data.dtypes
# 检查重复行
duplicate_rows = data.duplicated().sum()
# 输出结果
missing_values, data_types, duplicate_rows
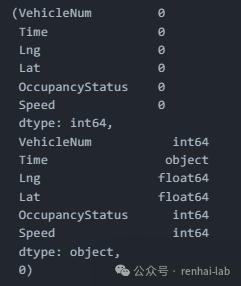
3、行程提取
行程提取的核心在于识别每辆车的行程开始和结束的时刻。在出租车数据中,通常使用“载客状态”(OccupancyStatus)字段来表示车辆是否载客。因此,一个行程可以定义为从“空载”(OccupancyStatus=0)转变为“载客”(OccupancyStatus=1)的过程,而行程结束则定义为从“载客”状态回到“空载”状态。
为了提取行程信息,我们首先对数据按照车辆编号和时间进行排序,以确保行程按照时间顺序被识别。然后,通过迭代每个记录,根据“载客状态”的变化来识别行程的开始和结束。每当检测到行程开始时,记录下起始时间和位置;当行程结束时,记录下结束时间和位置,并将这段行程的信息存储起来。
具体操作如下:
(1)将时间戳转换为时间格式
# 定义一个年月日字符串 由数据源官网可知数据所在日期是2013-10-22
default_date_str = '2013-10-22 '
# 将时间转换为字符串,并在前面加上默认日期
data['Time'] = pd.to_datetime(default_date_str + data['Time'])
data['Time'] = pd.to_datetime(data['Time'], format='%Y-%M-%d %H:%M:%S')
(2)数据排序
对数据进行排序,确保按照每辆车的编号和时间顺序排列。
data_sorted = data_shenzhen.sort_values(by=['VehicleNum', 'Time'])
data_sorted.head()
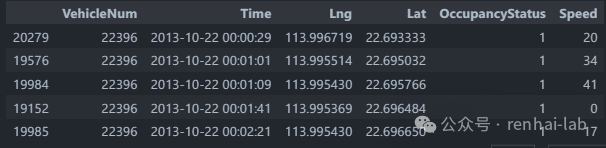
(3)准备存储行程信息的新数据框
# 创建一个新的 DataFrame,用于存储提取出的行程信息。列包括车辆编号、行程开始和结束时间、起点和终点的经纬度。
trips = pd.DataFrame(columns=['VehicleNum', 'StartTime', 'EndTime', 'StartLng', 'StartLat', 'EndLng', 'EndLat', 'Speed'])
(4)识别每辆车的行程开始和结束点。
提取每辆车的每个行程信息,包括每个行程的起点和终点的经纬度以及开始和结束时间。由于 'OccupancyStatus' 用于表示车辆是否载客(1 表示载客,0 表示空载),我们可以利用这个字段来识别行程的开始和结束。
一般来说,一个行程的开始可以定义为车辆从空载状态变为载客状态的时刻,而行程的结束则是车辆从载客状态变回空载状态的时刻。因此,我们需要找到每次 'OccupancyStatus' 从 0 变为 1 的点作为行程的开始,以及从 1 变为 0 的点作为行程的结束。
我们将按照以下步骤进行操作:
对数据进行排序,确保按照每辆车的编号和时间顺序排列。
识别每辆车的行程开始和结束点。
提取每个行程的相关信息,包括起点和终点的经纬度以及开始和结束时间。
现在我将开始进行这些步骤的实现。
已经成功提取了每辆车的每个行程信息,包括每个行程的起点和终点经纬度以及开始和结束时间。这些信息被存储在一个新的数据框中,包含以下列:
'VehicleNum':车辆编号
'StartTime':行程开始时间
'EndTime':行程结束时间
'StartLng':行程起点经度
'StartLat':行程起点纬度
'EndLng':行程终点经度
'EndLat':行程终点纬度
我们利用两个for循环,第一个for循环处理每辆相同编号的车,第二个for循环处理同编号车的每一行数据,这里利用了iterrows:iterrows是Pandas库中DataFrame对象的一个方法。它用于迭代DataFrame的每一行,并返回每一行的索引和数据。这个方法可以帮助我们在处理数据分析任务时逐行处理DataFrame的数据。使用iterrows方法,你可以遍历DataFrame的每一行,并对每一行的数据进行操作或分析。每次迭代时,iterrows方法会返回一个包含两个元素的元组,第一个元素是行的索引,第二个元素是包含该行数据的Series对象。
# 迭代处理每辆车的数据
for vehicle in data_sorted['VehicleNum'].unique():
# 为每辆车创建一个子数据集 vehicle_data
vehicle_data = data_sorted[data_sorted['VehicleNum'] == vehicle]
# 追踪和记录每个行程
trip_start = None
trip_start_lng = None
trip_start_lat = None
previous_status = None
# 4.迭代处理每个行程
for i, row in vehicle_data.iterrows():
if row['OccupancyStatus'] == 1 and previous_status == 0:
# 行程开始
trip_start = row['Time']
trip_start_lng = row['Lng']
trip_start_lat = row['Lat']
elif row['OccupancyStatus'] == 0 and trip_start is not None:
# 行程结束,添加到 trips 数据框中
trip_data = pd.DataFrame({
'VehicleNum': [int(vehicle_data.iloc[0]['VehicleNum'])],
'StartTime': [trip_start],
'EndTime': [row['Time']],
'StartLng': [trip_start_lng],
'StartLat': [trip_start_lat],
'EndLng': [row['Lng']],
'EndLat': [row['Lat']],
'Speed': [row['Speed']]
})
trips = pd.concat([trips, trip_data], ignore_index=True)
# 重置追踪变量
trip_start = None
trip_start_lng = None
trip_start_lat = None
# 更新 previous_status
previous_status = row['OccupancyStatus']
# 看看结果
trips.head()
执行时间1m4s。
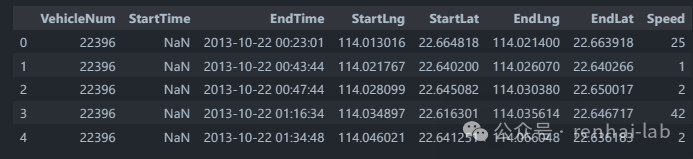
(5)进一步优化
# 进一步优化:使用pandas的apply方法能够更快地处理数据
# 函数,用于处理每辆车的数据并返回行程信息
def extract_trips(vehicle_data):
trips_list = []
trip_start = trip_start_lng = trip_start_lat = None
previous_status = None # 引入了previous_status变量来存储上一条记录的OccupancyStatus。
for _, row in vehicle_data.iterrows():
# 检测行程开始:前一状态为0,当前状态为1
if row['OccupancyStatus'] == 1 and previous_status == 0:
trip_start = row['Time']
trip_start_lng = row['Lng']
trip_start_lat = row['Lat']
# 检测行程结束:当前状态为0,行程已经开始
elif row['OccupancyStatus'] == 0 and trip_start is not None:
trips_list.append({
'VehicleNum': int(vehicle_data.iloc[0]['VehicleNum']),
'StartTime': trip_start,
'EndTime': row['Time'],
'StartLng': trip_start_lng,
'StartLat': trip_start_lat,
'EndLng': row['Lng'],
'EndLat': row['Lat'],
'Speed': row['Speed']
})
trip_start = trip_start_lng = trip_start_lat = None
# 更新前一状态
previous_status = row['OccupancyStatus']
return pd.DataFrame(trips_list)
# 使用 groupby() 和 apply() 处理每辆车的数据
trips = data_sorted.groupby('VehicleNum').apply(extract_trips).reset_index(drop=True)
# 显示前几行数据
trips.head()
执行时间43.1s,速度提升了1/3。
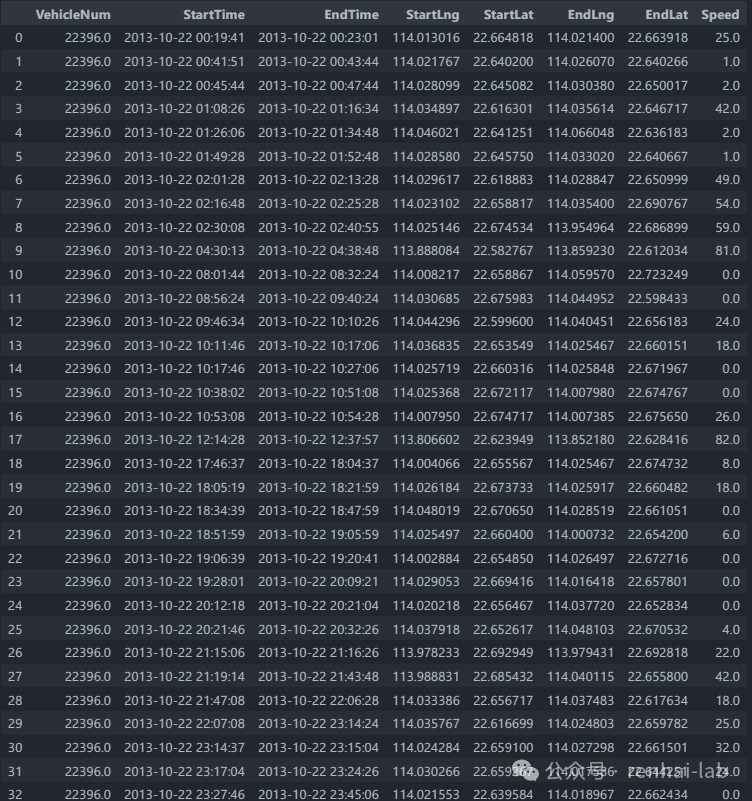
(6)检查OD信息
# 验证数据
# 选择trips的22334号车
trips_22396 = trips[trips['VehicleNum'] == 22396].sort_values("EndTime")
trips_22396
3、进一步筛选数据
(1)筛选行程时间大于1分钟的数据
# 计算行程时间
trips['TripTime'] = (trips['EndTime'] - trips['StartTime']).dt.total_seconds() / 60 # 分钟
# 选择行程时间大于等于1分钟的行程
trips = trips[trips['TripTime'] >= 1]
len(trips)
(2)筛选起终点不同的数据
# 2.起点终点相同
# 选择起点终点不相同的行程
trips = trips[(trips['StartLng'] != trips['EndLng']) | (trips['StartLat'] != trips['EndLat'])]
len(trips)
4、数据存储
提取出的行程信息包括车辆编号、行程的开始和结束时间、起始和结束位置的经纬度等,这些信息被存储在一个新的DataFrame中。这样,我们就可以对每个行程进行进一步的分析,比如计算行程距离、行程持续时间等。
# 保存数据
trips.to_csv("../data/trips.csv",index=False, header=True)
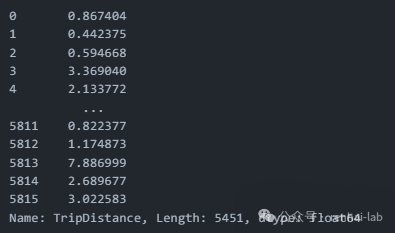
5、计算行程距离
由于计算距离的单位是m,我们要将原始数据中的wgs1984地理坐标系投影之后再计算距离,这也称作欧氏距离。
有很多方法可以计算欧氏距离,这里选择一种最简单的方法,使用geopy库的函数geodesic函数计算距离:
需要安装geopy安装
# 使用 geopy 计算距离
trips['TripDistance'] = trips.apply(lambda row: geodesic((row['StartLat'], row['StartLng']), (row['EndLat'], row['EndLng'])).km, axis=1)
trips['TripDistance']
结论
通过以上步骤,我们可以有效地从原始的出租车定位数据中提取出有价值的行程信息。这些信息不仅可以用于交通流量分析、城市规划等领域,也可以为出租车公司提供运营优化的依据。Python和Pandas库为数据处理和分析提供了强大的工具,使得从大规模数据中提取有用信息成为可能。
如果你对本文章有什么意见、对如何制作文中的图表感兴趣、或者有其它任何问题建议在本文的博客评论区留言,说不定你的问题别人也遇到了。
本文发布在我的博客,可以阅读原文[2]访问。










