传统的 Python Web 应用主要用于数据处理、分析或后端管理系统。它们通常具有低并发、密集计算和高 I/O 操作的特点,对并发性要求并不高。然而,随着人工智能的不断发展和进步,越来越多的智能化应用正在涌现,面向终端用户、消费级用户的基于 Python 的 Web 应用也越来越多,占据了重要地位。在这种趋势下,对 Python Web 服务进行高并发和调优变得尤为关键。随着智能化应用的增加,用户对系统的要求也变得越来越严格,因此优化 Python Web 服务以确保高性能和稳定性变得至关重要。
接下来,我们将重点讨论WSGI(Web Server Gateway Interface)服务网关Gunicorn的介绍和配置,我们不局限于特定的Web框架,如Django、Flask或Tornado等。我们将探讨在生产环境中如何通过Gunicorn来提高性能和稳定性,以及如何最大化资源利用率。
Python的并发性和并行性
在Python中,由于全局解释器锁(GIL:Global Interpreter Lock)会限制同一时刻只有一个线程能够执行Python字节码,这意味着Python的线程(Thread)是伪线程,因为多线程并不能真正实现并行计算,而是在单个CPU核心上交替执行。
假如一个Python进程(Processing)实例中有 100 个线程,GIL 也只会允许一个线程同时运行。这意味着在任何时候,99 个线程都会被暂停,只有 1 个线程在工作。GIL 负责这种协调工作。
Python的线程并不适合用于CPU密集型任务,因为它们无法真正实现并行计算。另外在python 线程下还有协程(Coroutine),协程(Coroutine)允许在单个线程中实现多个执行流,通过yield语句来实现任务的切换和暂停,从而避免了线程切换的开销。
Python中的线程(Thread)/(Coroutine)协程适用于I/O密集型任务,对CPU密集型任务的效果并不理想。
由于Python线程的特点,设计Python Web应用的高并发性合理架构至关重要。一种常见的设计方案是将Nginx作为网关,后面部署多个Python服务实例。如下图:
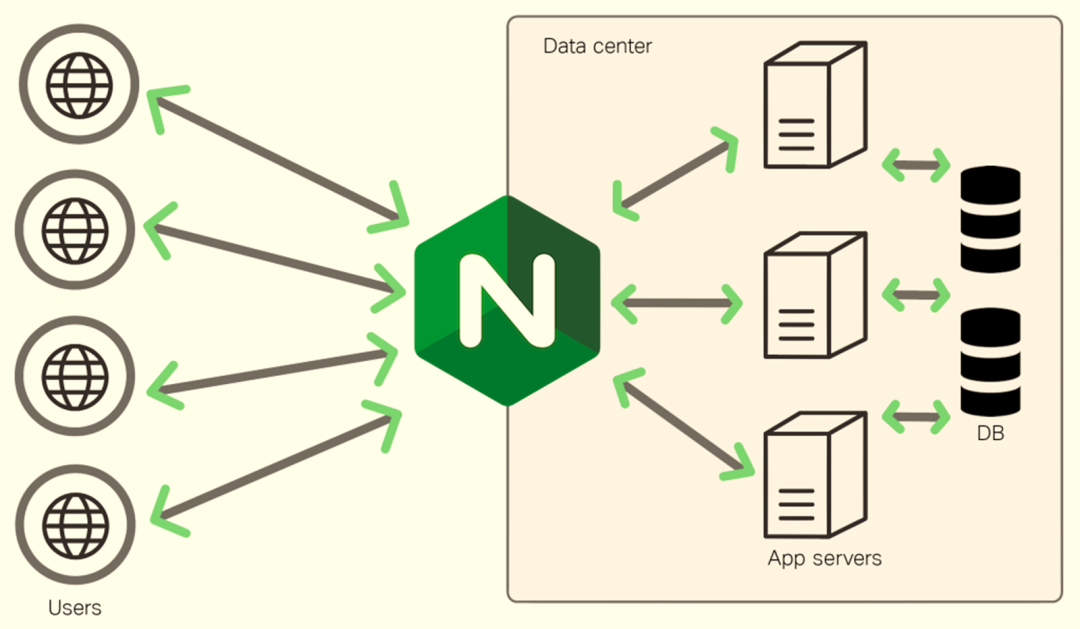
Nginx作为网关的作用是接收并分发客户端请求,然后将请求转发到后端的多个Python服务实例上。这些Python服务实例可以运行在不同的进程中,每个进程都可以独立地处理请求。通过这种方式,我们可以充分利用多核处理器,提高系统的并发处理能力。这种方式部署较为复杂。
受到 Ruby Unicorn HTTP 服务器的启发,由 Benoît Chesneau 创建的 Gunicorn,是处理 Python Web 应用高并发性的更简单、更方便的选择。
关于Gunicorn
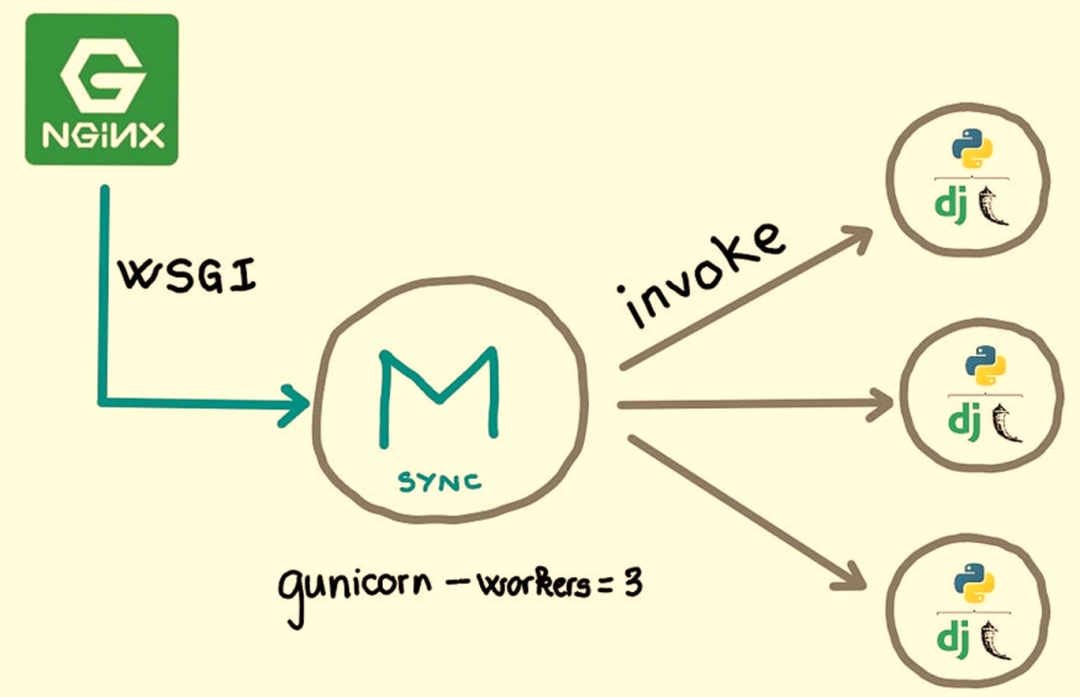
Gunicorn(Green Unicorn)是一个用于UNIX/Linux 系统的Python WSGI(Web Server Gateway Interface) HTTP服务器。它采用了(the pre-fork worker model)预分叉工作模型。Gunicorn服务器与各种Web框架广泛兼容,实现简单,占用服务器资源较少,并且运行速度相当快。
💡💡Gunicorn is based on the pre-fork worker model. This means that there is a central master process that manages a set of worker processes. The master never knows anything about individual clients. All requests and responses are handled completely by worker processes.💡💡
Gunicorn 是典型 WSGI 服务器实现,它基于pre-fork工作模型:
一个单一的主进程(master)被启动,并调用多个子进程(workers)。
pre-forked中的“pre”意味着主进程(master)在处理任何HTTP请求之前创建工作进程(workers)。
主进程(master)的作用是与Web服务器通信,保持多个Web应用程序实例(workers)的运行,确保它们的健康,并在这些实例之间分配传入的请求。如果任何一个工作进程停止运行,主进程将启动另一个以确保工作进程(workers)的数量与设置中定义的数量相同。
工作进程(workers)的作用是处理HTTP请求。
gunicorn 配置详细参考: https://docs.gunicorn.org/en/stable/configure.html
Gunicorn Worker 数量
每个工作进程(worker)都是一个加载 Python 应用程序的 UNIX/Linux 进程。工作进程之间没有共享内存。
一般推荐的工作进程数量(worker)是 (2 * CPU核数) + 1。对于双核 (2 CPU) 的机器,建议的工作进程值为 5。如下图:
gunicorn --workers=5 main:app
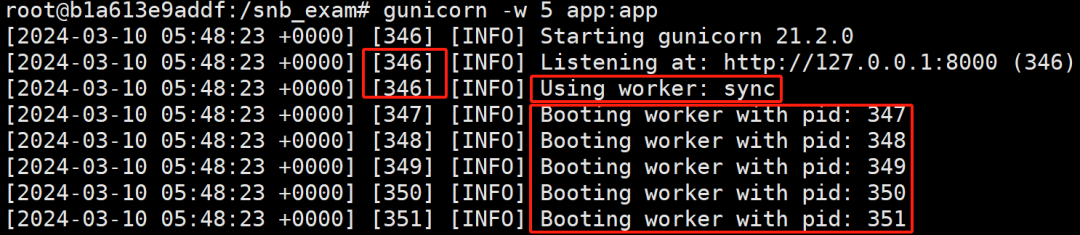
启动1个主进程(Master),5个worker 进程,默认进程类型为:sync
Gunicorn Worker 类型
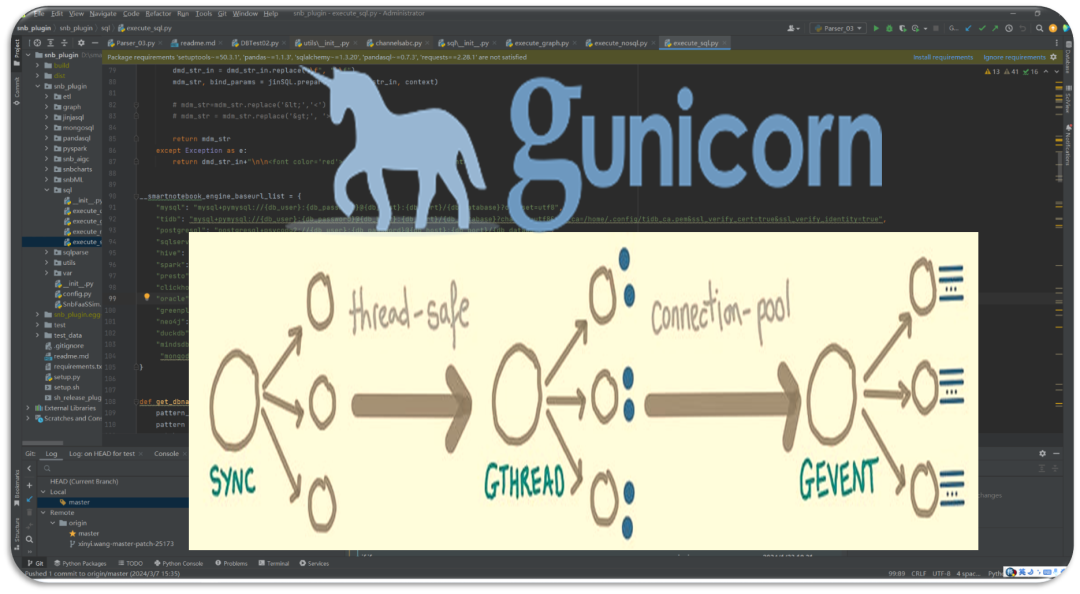
Gunicorn提供了几种类型的工作进程:sync、gthread、gevent、evenlet、tornado 等,可以分为三个不同的类别:
每个进程同一时间只处理一个请求(sync):主进程一次将单个HTTP请求委派给一个工作进程。
每个线程处理一个请求(gthread):每个工作进程生成多个线程,Gunicorn一次将单个HTTP请求委派给工作进程生成的一个线程。
带有异步IO的请求(gevent、evenlet或tornado):工作进程使用异步IO同时处理多个请求。
Worker 类型:sync(request per process)
设置worker 类型(worker 默认类型)为sync,最大并发请求的数量等于工作进程的数量。
sync适合下面场景:
CPU密集型应用。
只关注并行请求的数量。
内存消耗不是一个大问题。
优点:
简单的错误处理:如果一个进程崩溃,它只会影响该进程处理的请求,其他请求不会受到影响。
重用对外部服务的连接的简单实现:通过使与工作进程持久连接的外部资源(如数据库)可以在同一个工作进程中重用,它们可以为所有HTTP请求处理提供服务,只要工作进程存活并处理请求。
工作进程之间没有共享内存,每个工作进程一次处理一个请求,因此您无需处理并发应用程序可能出现的问题(如竞态条件、死锁等)。
缺点:
一个进程比线程或协程需要更多的资源(内存、CPU)。因此,当进程数量增加时,处理请求所需的资源会很高,这将消耗过多的CPU和内存,这是不必要的。
必须实现断路器设计模式来处理外部资源故障。例如,您的应用程序需要连接到外部互联网服务以信息(HTTP请求POST数据中的资源字段指示要查询的服务)。在某个时间点,外部服务崩溃了,之后的几秒内任何对外部的请求都会超时失败。在这种情况下,HTTP请求至少需要几秒钟才能在工作进程中处理完成。然后,这些请求迅速占满了应用程序的所有工作进程。所有的服务都被堵住,整个应用程序也会挂起。
Worker 类型:gthread(request per thread)
gthread类型是每个工作进程可以生成多个线程。Python应用程序在每个工作进程中加载一次,由同一工作进程生成的每个线程共享相同的内存空间。最大并发请求数为工作进程数乘以线程数。
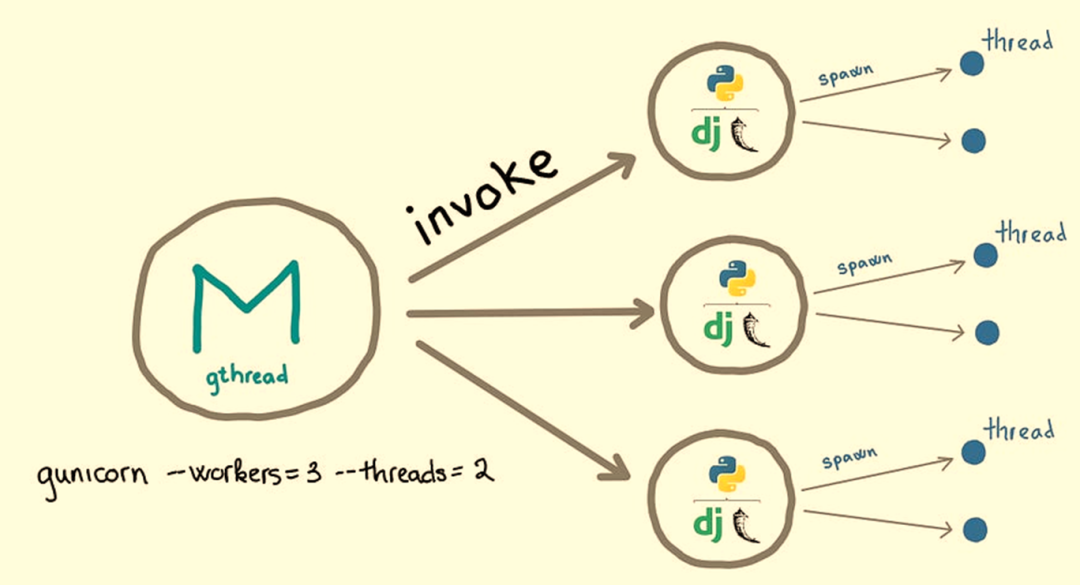
适应的场景包括:
优点:
缺点:
Worker 类型:gevent( request per coroutines)
gevent和eventlet使用Python中轻量级并发协程(coroutines)方法,Gunicorn支持它们作为工作进程类型。使用此工作进程类型,工作进程不会等待IO操作,而是继续接受和处理其他请求,直到该IO操作完成。理论上,最大并发请求数量非常大。
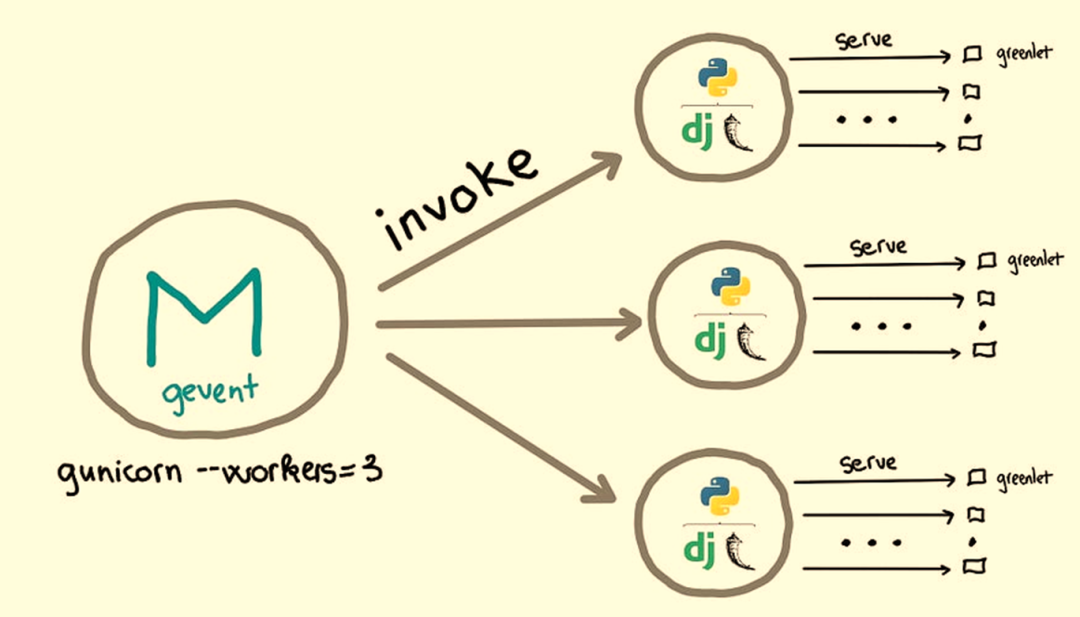
适合以下场景:
优点:
缺点:

对于不同的场景,您可以选择不同类型的工作进程来改善Gunicorn的性能。对于CPU密集型应用程序,您可以选择sync(同步模式)或 ghread(线程模式)。对于I/O密集型应用程序,则建议使用gevent(协程模式)。








