
嘿,你知道吗?在这个世界上,有一种东西叫做LLMs,大型语言模型。它们是相当厉害的家伙,可以理解和生成各种各样的文本,甚至可以和人类一样聊上一会儿。但是,机器学习仍然是相当重要的,为什么呢?让我来告诉你。
想象一下,你有一堆数据,里面包含了世界上发生的各种各样的事情。现在,你想要从这堆数据中找到一些有用的模式或者做一些预测。这时候,机器学习就像是你的超级朋友,可以帮你轻松地做到这些事情。
而Sklearn,嘿,它简直就是机器学习世界的大杠把子。想象一下你在野外,突然受伤了,但是你有一根结实的棍子可以依靠。Sklearn就像是那根棍子,它支撑着你,让你能够在机器学习的旅程中穿越荆棘丛生的数据丛林。
所以,尽管LLMs可能会让你觉得人类的工作好像变得不那么重要了,但是机器学习和Sklearn仍然是你不可或缺的朋友。在这个世界上,我们需要的不仅仅是高级的技术,还需要那些能够帮助我们处理数据、做出预测并解决问题的工具。
想象一下,你正在走钢丝,下面是一片湍急的河流。你需要保持平衡,同时快速地朝前走。这就像是数据建模的过程,需要在不稳定的数据海洋中取得平衡,并快速做出决策。
但是,如果你掌握了一些Sklearn技巧,就像是你脚下多了一双坚固的钢丝鞋,可以让你更加稳健地前行。Sklearn的技巧就像是你的秘密武器,可以让你在建模的过程中更快地达到目标,更准确地预测结果。
在Sklearn的使用过程中,许多人往往过分专注于API文档,而忽略了许多常被忽视的技巧。或许大多数人停留在基础操作层面,然而实际上,Sklearn中隐藏着许多优雅的解决方案。让我们一起揭示这些宝贵的Sklearn技巧,让你在短时间内提升机器学习的能力。
1.检测离群值: covariance.EllipticEnvelope
分布中存在离群值是很常见的。许多算法都处理离群值,而EllipticalEnvelope是一个直接内置到Sklearn中的示例。该算法的优势在于,在正态分布(高斯分布)特征中,它在检测离群值方面表现异常出色。import numpy as npfrom sklearn.covariance import EllipticEnvelope
X = np.random.normal(loc=5, scale=2, size=50).reshape(-1, 1)
ee = EllipticEnvelope(random_state=0)_ = ee.fit(X)
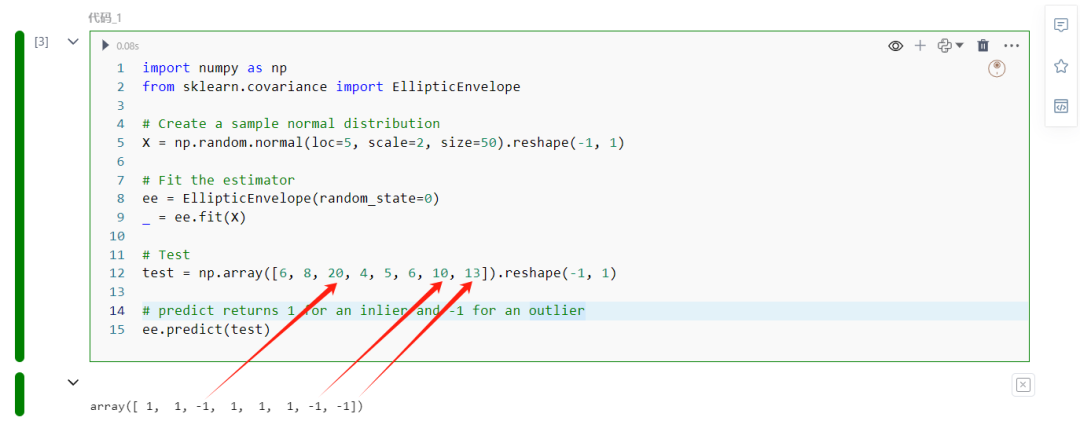
test = np.array([6, 8, 20, 4, 5, 6, 10, 13]).reshape(-1, 1)
ee.predict(test)
为了测试这个评估器(estimator),我们创建了一个均值为5,标准差为2的正态分布。在训练完成后,我们向其predict方法传递一些随机数。该方法对于测试中的离群值返回-1,这些离群值是20、10、13。
2.特征选择:feature_selection.RFECV
选择对预测最有帮助的特征是应对过拟合和降低模型复杂性的必要步骤。Sklearn 提供的最强大的算法之一是递归特征消除(Recursive Feature Elimination,RFE)。它通过交叉验证自动找到最重要的特征,并丢弃其余的特征。这个评估器(estimator)的一个优势是它是一个包装器(wrapper) —— 它可以用于任何返回特征重要性或系数分数的 Sklearn 算法。以下是一个在模拟生成的数据集示例:
from sklearn.datasets import make_regressionfrom sklearn.feature_selection import RFECVfrom sklearn.linear_model import Ridge
X, y = make_regression(n_samples=10000, n_features=15, n_informative=10)
rfecv = RFECV(estimator=Ridge(), cv=5)_ = rfecv.fit(X, y)
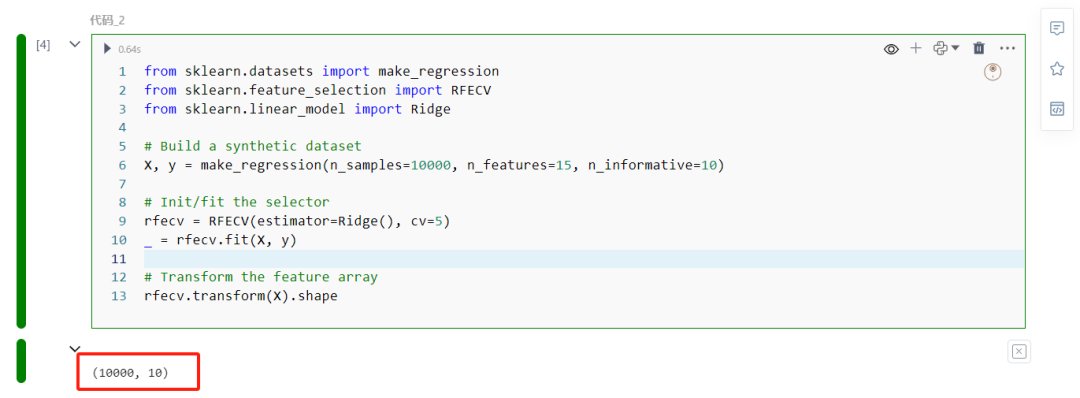
rfecv.transform(X).shape
这个模拟生成的数据集有15个特征,其中有10个是信息丰富的,其余的是冗余的。我们使用岭回归作为估计器进行5折RFECV拟合。训练完成后,您可以使用transform方法来丢弃冗余特征。调用.shape方法可以显示估计器成功丢弃了所有5个不必要的特征。
3.决策树的扩展集成学习方法: ensemble.ExtraTrees
尽管随机森林非常强大,但过拟合的风险也很高。因此,Sklearn提供了一个名为ExtraTrees(分类器和回归器均支持,classifier and regressor)的替代方案,可以直接替代随机森林。“extra”一词并不意味着更多的树,而是更多的随机性。该算法使用另一种类型的树,它与决策树非常相似。唯一的区别在于,在构建每棵树时,该算法不是计算分裂阈值,而是为每个特征随机绘制这些阈值,并选择最佳阈值作为分裂规则。这降低了方差,但代价是略微增加了偏差。
from sklearn.ensemble import ExtraTreesRegressor, RandomForestRegressorfrom sklearn.model_selection import cross_val_scorefrom sklearn.tree import DecisionTreeRegressor
X, y = make_regression(n_samples=10000, n_features=20)
clf = DecisionTreeRegressor(max_depth=None, min_samples_split=2, random_state=0)
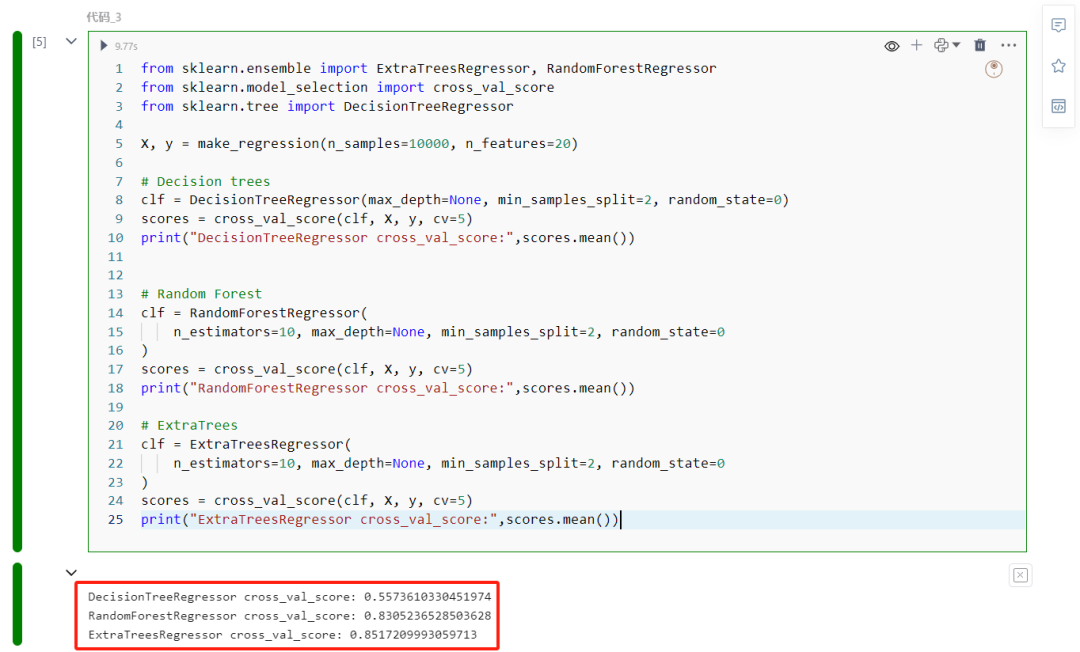
scores = cross_val_score(clf, X, y, cv=5)print("DecisionTreeRegressor cross_val_score:",scores.mean())
clf = RandomForestRegressor( n_estimators=10, max_depth=None, min_samples_split=2, random_state=0)scores = cross_val_score(clf, X, y, cv=5)print("RandomForestRegressor cross_val_score:",scores.mean())
clf = ExtraTreesRegressor( n_estimators=10, max_depth=None, min_samples_split=2, random_state=0)scores = cross_val_score(clf, X, y, cv=5)print("ExtraTreesRegressor cross_val_score:",scores.mean())
在一个合成数据集上,ExtraTreesRegressor的表现优于随机森林。
4.缺失值填充: impute.IterativeImputer和KNNImputer
比SimpleImputer更健壮、更高级的填补缺失值的技术,Sklearn提供了解决方案。klearn.impute子包包含两种基于模型的填补缺失值算法——KNNImputer和IterativeImputer。KNNImputer使用k-最近邻算法来找到缺失值的最佳替代值:
from sklearn.impute import KNNImputer
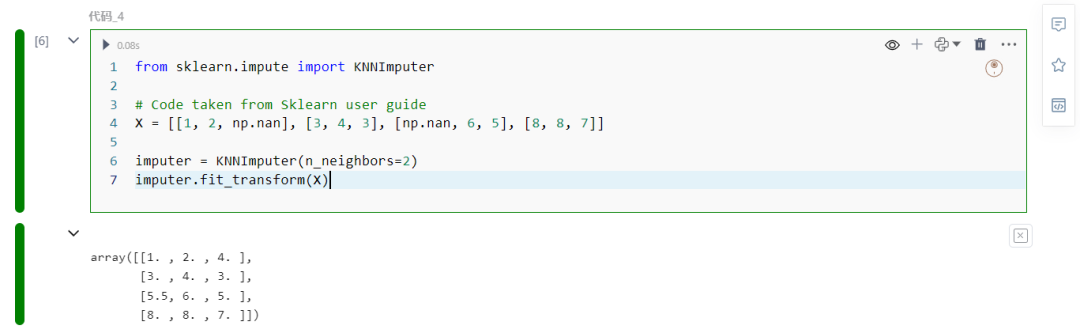
X = [[1, 2, np.nan], [3, 4, 3], [np.nan, 6, 5], [8, 8, 7]]
imputer = KNNImputer(n_neighbors=2)imputer.fit_transform(X)
IterativeImputer是更健壮的算法:它通过将具有缺失值的每个特征建模为其他特征的函数来找到缺失值。这个过程是以循环的方式逐步进行的。在每一步中,选择一个具有缺失值的特征作为目标(y),而其余的特征被选择为特征数组(X)。然后,使用回归器来预测y中的缺失值,并且这个过程对每个特征都会继续进行,直到达到max_iter次数(IterativeImputer的一个参数)。
因此,对于单个缺失值,会生成多个预测。这样做的好处是将每个缺失值视为随机变量,并与其相关的不确定性一并考虑在内:
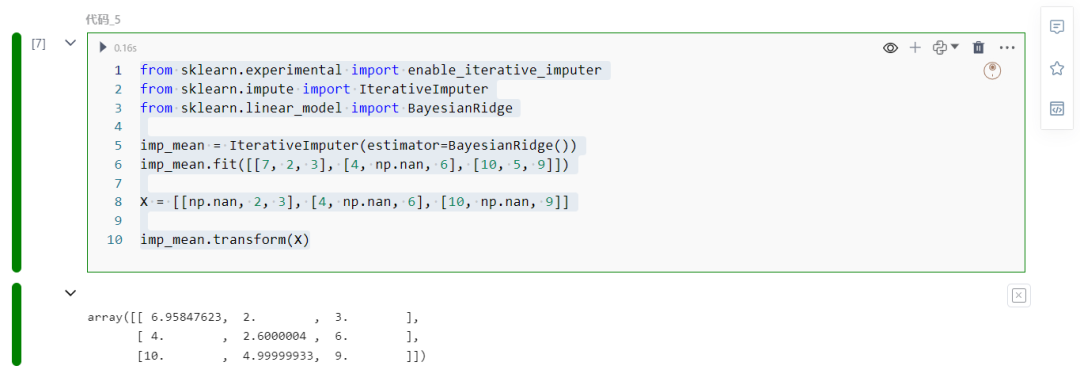
from sklearn.experimental import enable_iterative_imputerfrom sklearn.impute import IterativeImputerfrom sklearn.linear_model import BayesianRidge
imp_mean = IterativeImputer(estimator=BayesianRidge())imp_mean.fit([[7, 2, 3], [4, np.nan, 6], [10, 5, 9]])
X = [[np.nan, 2, 3], [4, np.nan, 6], [10, np.nan, 9]]
imp_mean.transform(X)
5.离群值处理: linear_model.HuberRegressor
存在离群值会严重影响任何模型的预测结果。许多离群值检测算法会将离群值丢弃并标记为缺失值。虽然这有助于模型的学习功能,但却完全消除了离群值对分布的影响。另一种替代算法是HuberRegressor。它不会完全移除离群值,而是在拟合期间给予离群值较小的权重。它具有一个epsilon超参数,用于控制应将多少样本分类为离群值。参数越小,模型对离群值的鲁棒性越强。它的API与任何其他线性回归器相同。
下面是sklearn 官方示例:HuberRegressor与Bayesian Ridge regressor在具有大量离群值的数据集上的比较:
import matplotlib.pyplot as pltimport numpy as np
from sklearn.datasets import make_regressionfrom sklearn.linear_model import HuberRegressor, Ridge
rng = np.random.RandomState(0)X, y = make_regression( n_samples=20, n_features=1, random_state=0, noise=4.0, bias=100.0)
X_outliers = rng.normal(0, 0.5, size=(4, 1))
y_outliers = rng.normal(0, 2.0, size=4)X_outliers[:2, :] += X.max() + X.mean() / 4.0X_outliers[2:, :] += X.min() - X.mean() / 4.0y_outliers[:2] += y.min() - y.mean() / 4.0y_outliers[2:] += y.max() + y.mean() / 4.0X = np.vstack((X, X_outliers))y = np.concatenate((y, y_outliers))plt.plot(X, y, "b.")
colors = ["r-", "b-", "y-", "m-"]
x = np.linspace(X.min(), X.max(), 7)epsilon_values = [1, 1.5, 1.75, 1.9]for k, epsilon in enumerate(epsilon_values): huber = HuberRegressor(alpha=0.0, epsilon=epsilon) huber.fit(X, y) coef_ = huber.coef_ * x + huber.intercept_ plt.plot(x, coef_, colors[k], label="huber loss, %s" % epsilon)
ridge = Ridge(alpha=0.0, random_state=0)ridge.fit(X, y)coef_ridge = ridge.coef_coef_ = ridge.coef_ * x + ridge.intercept_plt.plot(x, coef_, "g-", label="ridge regression")
plt.title("Comparison of HuberRegressor vs Ridge")plt.xlabel("X")plt.ylabel("y")plt.legend(loc=0)plt.show()
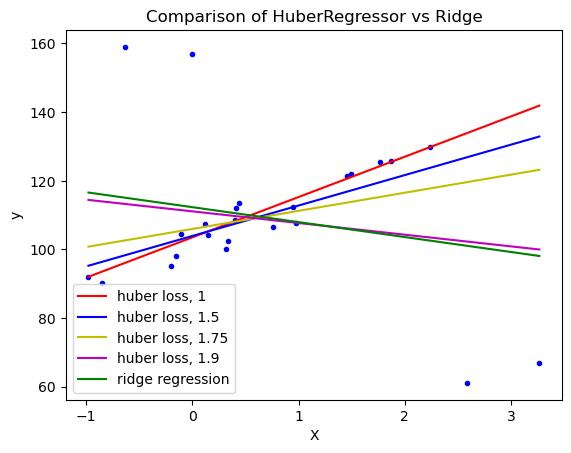
HuberRegressor在epsilon值为1.35、1.5和1.75时,能够捕捉到最佳拟合直线,而且不受离群值的影响。
6.树结构的展现:tree.plot_tree
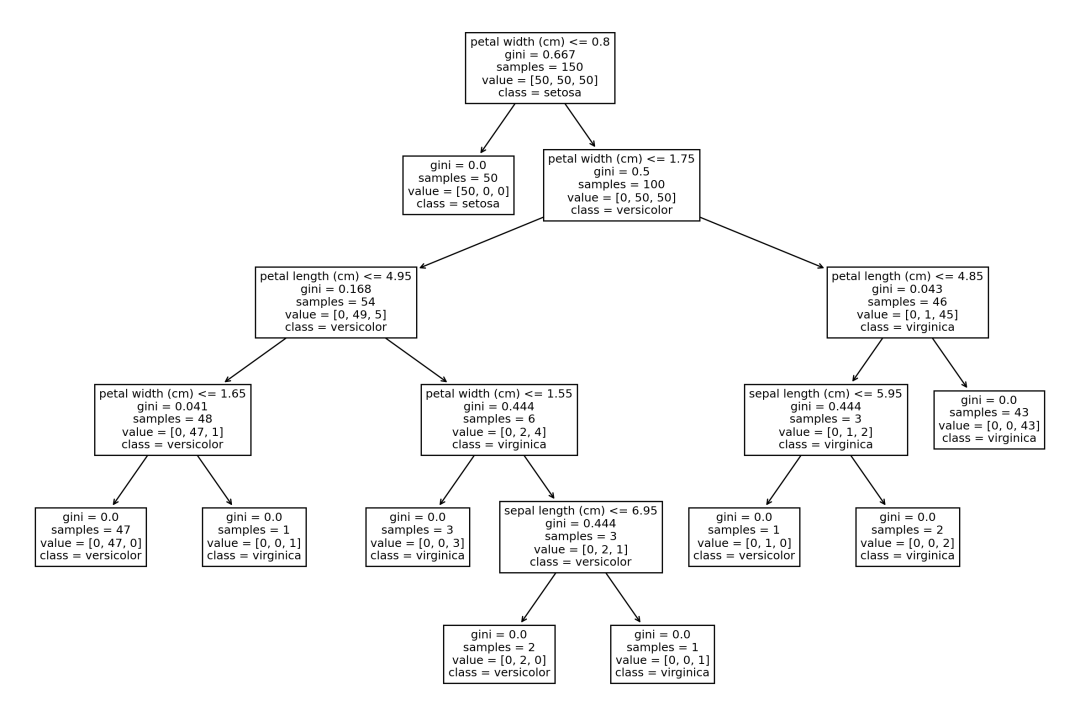
Sklearn使用plot_tree函数绘制单个决策树的结构。对于刚开始学习基于树和集成模型的初学者来说,这个功能可能会很方便。from sklearn.datasets import load_irisfrom sklearn.tree import DecisionTreeClassifier, plot_tree
iris = load_iris()X, y = iris.data, iris.targetclf = DecisionTreeClassifier()clf = clf.fit(X, y)
plt.figure(figsize=(15, 10), dpi=200)plot_tree(clf, feature_names=iris.feature_names, class_names=iris.target_names);
7.感知器:linear_model.Perceptron
感知器(Perceptron):尽管它有一个花哨的名字,但它实际上是一个简单的线性二元分类器。该算法的特点是适用于大规模学习,并且默认情况下:不需要学习率。
不实现正则化。
只在出现错误时更新模型。
它等同于SGDClassifier,其中loss='perceptron',eta=1,learning_rate="constant",penalty=None,但略快一些。
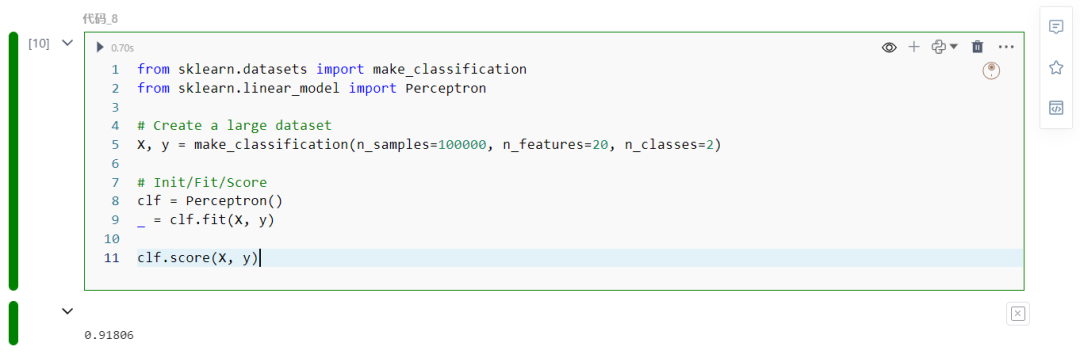
from sklearn.datasets import make_classificationfrom sklearn.linear_model import Perceptron
X, y = make_classification(n_samples=100000, n_features=20, n_classes=2)
clf = Perceptron()_ = clf.fit(X, y)
clf.score(X, y)
8.基于模型的特征选择: feature_selection.SelectFromModel
Sklearn中的另一个基于模型的特征选择估计器是SelectFromModel。它虽然没有RFECV那么健壮,但对于大规模数据集来说可能是一个不错的选择,因为它的计算成本较低。它也是一个包装器估计器,适用于任何具有.feature_importances_或.coef_属性的模型。
from sklearn.feature_selection import SelectFromModel
X, y = make_regression(n_samples=int(1e4), n_features=50, n_informative=10)
selector = SelectFromModel(estimator=ExtraTreesRegressor()).fit(X, y)
selector.transform(X).shape

如上图:该算法成功地丢弃了所有40个多余的特征。
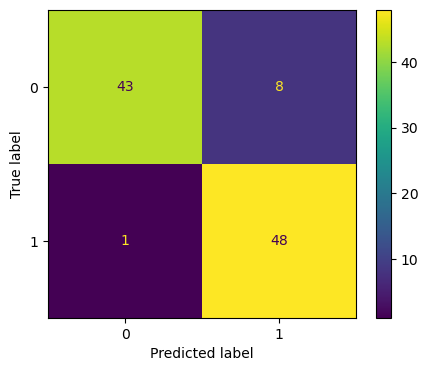
9.混淆矩阵的显示: metrics.ConfusionMatrixDisplay
混淆矩阵是分类问题中的圣杯。大多数指标都是从中导出的,如精确度、召回率、F1值、ROC AUC等。Sklearn允许您计算和绘制默认的混淆矩阵。
from sklearn.metrics import plot_confusion_matrixfrom sklearn.model_selection import train_test_splitfrom sklearn.tree import ExtraTreeClassifier
X, y = make_classification(n_samples=200, n_features=5, n_classes=2)X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.5, random_state=1121218)
clf = ExtraTreeClassifier().fit(X_train, y_train)
fig, ax = plt.subplots(figsize=(5, 4), dpi=100)plot_confusion_matrix(clf, X_test, y_test, ax=ax)
10.广义线性模型: Generalized Linear Models
如果有其他可以处理不同类型分布的替代方法,那么将目标(y)转换为正态分布就没有意义。例如,Sklearn提供了三种适用于目标变量为Poisson(泊松)、Tweedie或Gamma(伽玛)分布的广义线性模型。与期望正态分布不同,PoissonRegressor、TweedieRegressor和GammaRegressor可以为具有相应分布的目标生成稳健的结果。
除此之外,它们的API与任何其他Sklearn模型相同。要确定目标的分布是否与上述三种匹配,您可以将它们的概率密度函数(Probability Density Function)绘制在同一坐标轴上与完美分布。
例如,要查看目标是否遵循泊松分布,请使用Seaborn的kdeplot绘制其概率密度函数(Probability Density Function),并在同一坐标轴上使用Numpy的np.random.poisson从中抽样以绘制完美的泊松分布。
以上汇总了Sklearn机器学习中的关键方法和技巧,包括离群值检测、特征选择、集成学习、缺失值填充、离群值处理、决策树展现、感知器应用和模型选择。通过掌握这些技巧,您可以更好地处理数据、提高模型性能,并做出更准确的预测。Sklearn为机器学习提供了强大的工具,使您能够更轻松地应对各种挑战,并取得更好的结果。






