
瀑布图(Waterfall plots)经常用来展示某个值随时间的累积变化。另外,它们也可以使用固定的类别(例如,特定事件)而不是时间。因此,这种类型的图表在向业务利益相关者展示演示文稿时非常有用,因为我们可以轻松地展示公司营收/客户群随时间的演变。
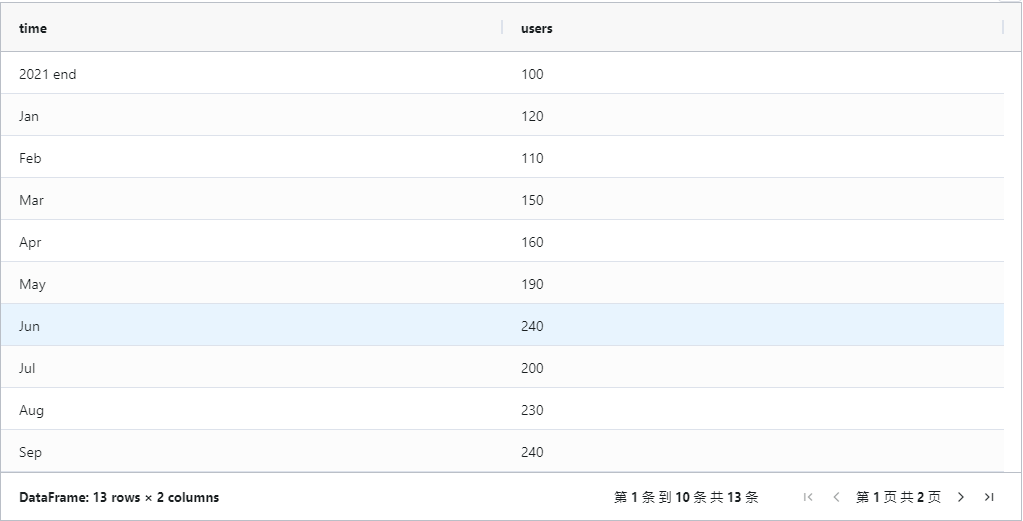
接下来,我们将使用三种不同的Python库创建瀑布图。首先,我们将虚构一些数据,以讲述一个完整的数据故事——描述一家移动互联网应用的用户发展情况,并提供一个展示我们应用在2022年用户基数的图表。我们需要假设2021年年末的数据:
df = pd.DataFrame( data={ "time": ["2021 end", "Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"], "users": [100, 120, 110, 150, 160, 190, 240, 200, 230, 240, 250, 280, 300] })
方法一:waterfall_ax
从最简单的方法(waterfall_ax)(pip install waterfall_ax)开始。我必须说我非常惊讶地发现,微软开发了一个基于matplotlib的小型库,用于创建瀑布图。该库称为waterfall_ax。要使用我们的数据集生成图表,我们需要运行以下代码:import matplotlib.pyplot as pltfrom waterfall_ax import WaterfallChart
fig, ax = plt.subplots(1, 1, figsize=(16, 8))waterfall = WaterfallChart( df["users"].to_list(), step_names=df["time"].to_list(), metric_name="# users", last_step_label="now")wf_ax = waterfall.plot_waterfall(ax=ax, title="# of users in 2022")
方法二:waterfall
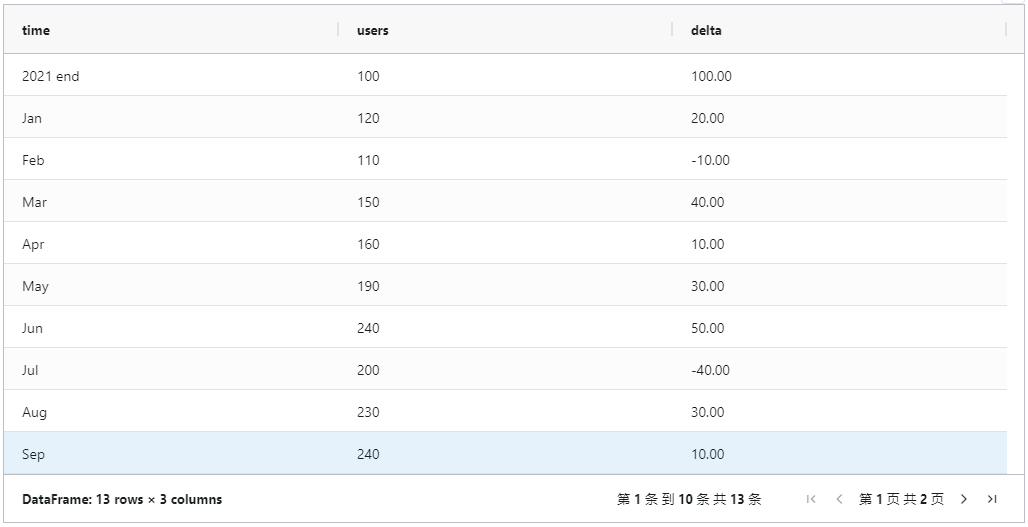
方法二是使用waterfall库(pip install waterfallcharts)。为了使用该库创建图表,我们需要添加一个包含增量的列,也就是各个步骤之间的差异。可以很容易地向数据框添加新列,并使用diff方法计算增量。我们将第一行的NA值填充为2021年底用户数量。df_1 = df.copy()df_1["delta"] = df_1["users"].diff().fillna(100)df_1
使用waterfall 输出瀑布图
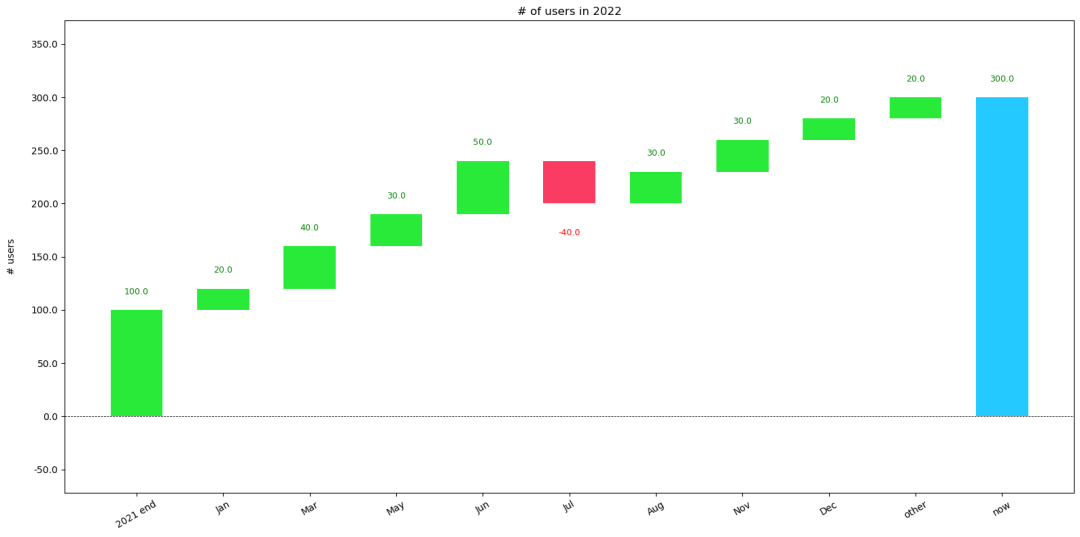
import waterfall_chartplt.rcParams["figure.figsize"] = (16, 8)waterfall_chart.plot( df_1["time"], df_1["delta"], threshold=0.2, net_label="now", y_lab="# users", Title="# of users in 2022")
方法三:plotly
虽然前两种方法使用了相当小众的特殊库,但最后一种方法将利用一个流行的库——plotly。首先需要对输入数据框进行一些处理,以使其与plotly方法兼容。df_2 = df_1.copy()df_2["delta_text"] = df_2["delta"].astype(str)df_2["measure"] = ["absolute"] + (["relative"] * 12)
df_2
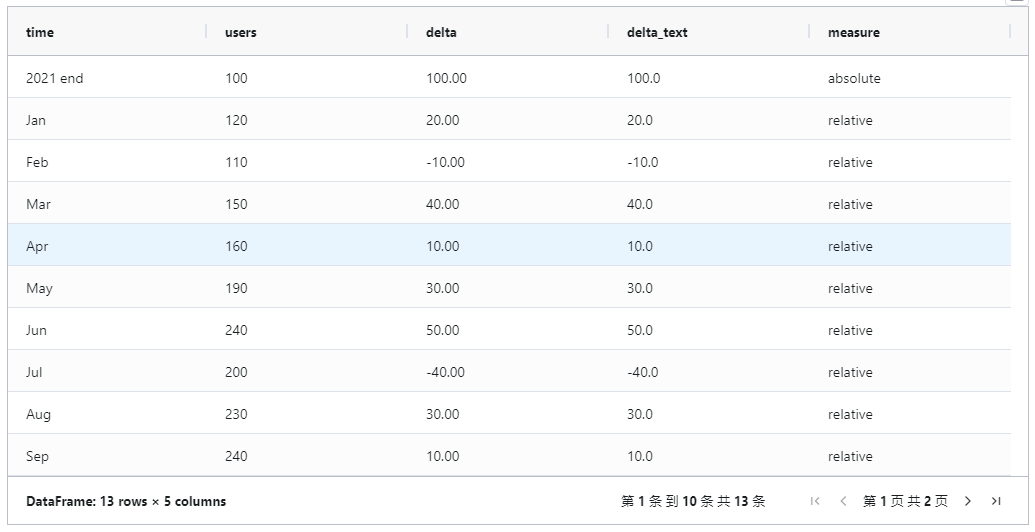
一个名为的新列delta_text,其中包含编码为字符串的更改。我们将使用它们作为绘图上的标签。然后,我们还定义了一个measure列,其中包含 所使用的度量plotly。图书馆接受的措施有以下三类:
import plotly.graph_objects as gofig = go.Figure( go.Waterfall( measure=df_2["measure"], x=df_2["time"], textposition="outside", text=df_2["delta_text"], y=df_2["delta"], ))
fig.update_layout( title="# of users in 2022", showlegend=False)
fig.show()
使用以下代码片段创建瀑布图:
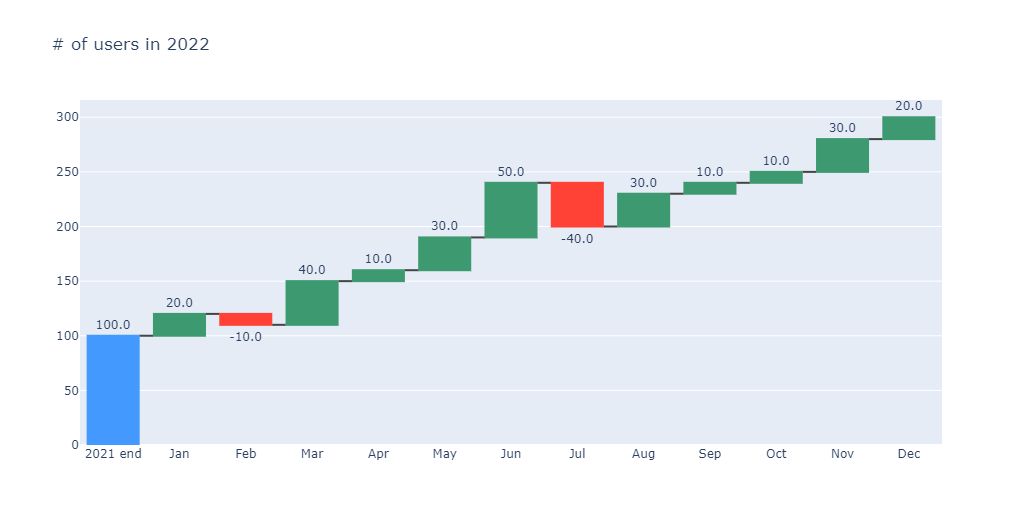
plotly是绘图是完全交互式的——我们可以放大、检查工具提示以获取附加信息(在本例中是查看累积和)等。
与之前的图的一个明显区别是我们没有看到最后一个块显示净值/总计。也可以使用 plotly来添加它。为此,我们必须向数据框添加一个新行。
total_row = pd.DataFrame( data={ "time": "now", "users": 0, "delta":0, "delta_text": "", "measure": "total" }, index=[0])df_3 = pd.concat([df_2, total_row], ignore_index=True)df_3
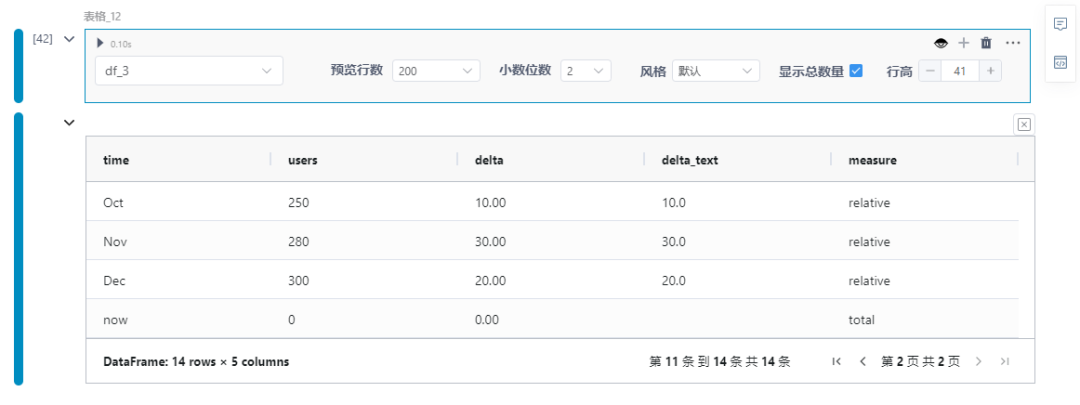
用于生成绘图的代码实际上没有改变,唯一的区别是我们使用带有附加行的数据框。
fig = go.Figure( go.Waterfall( measure=df_3["measure"], x=df_3["time"], textposition="outside", text=df_3["delta_text"], y=df_3["delta"], ))
fig.update_layout( title="# of users in 2022", showlegend=False)
fig.show()
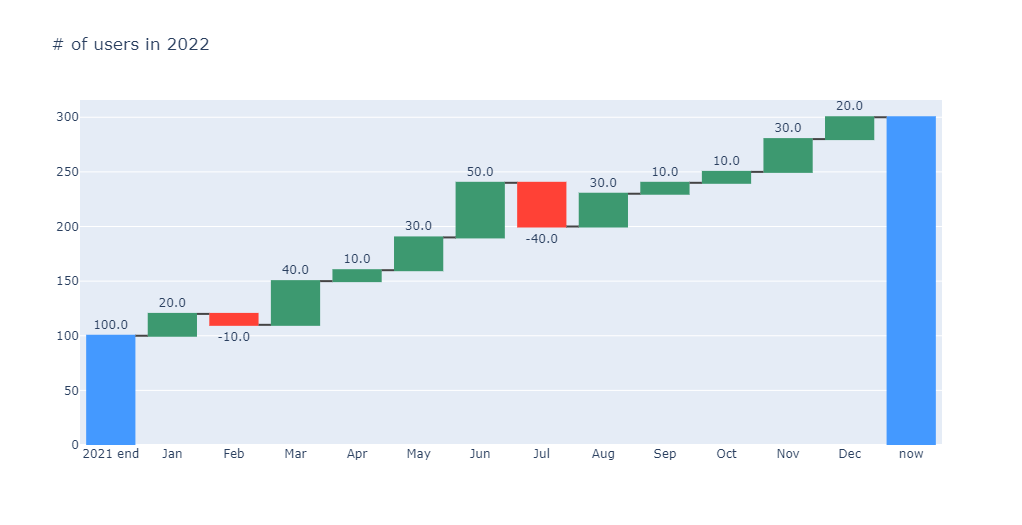
本文介绍了在Python中使用三种不同的库(waterfall_ax、waterfall和plotly)创建瀑布图的方法。这些库各有特点,可以根据需求选择合适的。从数据准备到绘图过程,每种方法都有详细的步骤说明。通过本文,读者可以轻松快速地创建展示数据变化的瀑布图,丰富了数据可视化的工具选择。









