
向AI转型的程序员都关注了这个号👇👇👇
什么是提示工程
提示工程是一个较新的学科,应用于开发和优化提示词(Prompt),帮助用户有效地将语言模型用于各种应用场景和研究领域。掌握了提示工程相关技能将有助于用户更好地了解大型语言模型的能力和局限性。研究人员可利用提示工程来提高大语言模型处理复杂任务场景的能力,如问答和算术推理能力。开发人员可通过提示工程设计和研发出强大的技术,实现和大语言模型或其他生态工具的高效接轨。
本指南介绍了提示词相关的基础知识,帮助用户了解如何通过提示词和大语言模型进行交互并提供指导建议。
除非特别说明,本指南默认所有示例都是基于 OpenAI 的大语言模型 text-davinci-003 进行测试,并且使用该模型的默认配置,如 temperature=0.7 和 top-p=1 等。
大语言模型设置
使用提示词时,您会通过 API 或直接与大语言模型进行交互。你可以通过配置一些参数以获得不同的提示结果。
Temperature:简单来说,temperature 的参数值越小,模型就会返回最确定的一个结果。如果调高该参数值,大语言模型可能会返回更随机的结果,也就是说这可能会带来更多样化或更具创造性的产出。我们目前也在增加其他可能 token 的权重。在实际应用方面,对于质量保障(QA)等任务,我们可以设置更低的 temperature 值,以促使模型基于事实返回更真实和简洁的结果。对于诗歌生成或其他创造性任务,你可以适当调高 temperature 参数值
Top_p:同样,使用 top_p(与 temperature 一起称为核采样的技术),可以用来控制模型返回结果的真实性。如果你需要准确和事实的答案,就把参数值调低。如果你想要更多样化的答案,就把参数值调高一些。
注意:一般建议是改变其中一个参数就行,不用两个都调整。
在我们开始一些基础示例之前,请记住最终生成的结果可能会和使用的大语言模型的版本而异。
当然除以上两个参数外,ChatGPT还有其它不少参数也可以设置,具体可以参考OpenAI官方给到的Completions生成相关参数。博主这边仅再补充两个重要参数:
presence_penalty:介于-2.0和2.0之间的数字。正值会根据新标记到目前为止是否出现在文本中来惩罚它们,从而增加模型谈论新主题的可能性。查看有关presence_penalty的详细信息。
frequency_penalty:介于-2.0和2.0之间的数字。正值会根据新标记在文本中的现有频率惩罚新标记,从而降低模型逐字重复同一行的可能性。查看有关frequency_penalty的详细信息。
基础提示词
您可以通过简单的提示词(Prompts)获得大量结果,但结果的质量与您提供的信息数量和完善度有关。一个提示词可以包含您传递到模型的_指令_或_问题_等信息,也可以包含其他详细信息,如_上下文_、_输入_或_示例_等。您可以通过这些元素来更好地指导模型,并因此获得更好的结果
看下面一个简单的示例:
提示词:
The sky is
输出结果
blue
The sky is blue on a clear day. On a cloudy day, the sky may be gray or white.
如以上示例,语言模型能够基于我们给出的上下文内容 `“The sky is” 完成续写。而输出的结果可能是出人意料的,或远高于我们的任务要求。
基于以上示例,如果想要实现更具体的目标,我们还必须提供更多的背景信息或说明信息。
可以按如下示例试着完善一下:
提示词
完善以下句子:
The sky is
输出结果
so beautiful today.
结果是不是要好一些了?本例中,我们告知模型去完善句子,因此输出的结果和我们最初的输入是完全符合的。**提示工程(Prompt Engineering)**就是探讨如何设计出最佳提示词,用于指导语言模型帮助我们高效完成某项任务。
以上示例基本说明了现阶段的大语言模型能够发挥的功能作用。它们可以用于执行各种高级任务,如文本概括、数学推理、代码生成等。
提示词格式
前文中我们还是采取的比较简单的提示词。标准提示词应该遵循以下格式:
?
或
这种可以被格式化为标准的问答格式,如:
Q: ?
A:
以上的提示方式,也被称为_零样本提示(zero-shot prompting)_,即用户不提供任务结果相关的示范,直接提示语言模型给出任务相关的回答。某些大型语言模式有能力实现零样本提示,但这也取决于任务的复杂度和已有的知识范围。
基于以上标准范式,目前业界普遍使用的还是更高效的_小样本提示(Few-shot Prompting)_范式,即用户提供少量的提示范例,如任务说明等。小样本提示一般遵循以下格式:
?
?
?
?
而问答模式即如下:
Q: ?
A:
Q: ?
A:
Q: ?
A:
Q: ?
A:
注意,使用问答模式并不是必须的。你可以根据任务需求调整提示范式。比如,您可以按以下示例执行一个简单的分类任务,并对任务做简单说明:
This is awesome! // Positive
This is bad! // Negative
Wow that movie was rad! // Positive
What a horrible show! //
Negative
语言模型可以基于一些说明了解和学习某些任务,而小样本提示正好可以赋能上下文学习能力。
人工智能也有很多种,它们各自有各自擅长的任务。我们完全可以让它们互相协作,共享知识,解决问题。而ChatGPT,作为一个擅长理解和生成自然语言的模型,就像一个会说话的通用翻译机,帮助我们与其他AI模型进行对话,打破了语言壁垒。这不仅让AI的使用变得更加简单,也极大地拓宽了我们可以解决的问题的范围。
事实上,学界已经进行了很多探索,例如“HuggingGPT”, 它会先用ChatGPT来分析你的请求,把它分成一系列的子任务,比如说话、看图、听声音等。然后它会从Hugging Face社区中找到合适的AI模型来做这些子任务,比如用A模型来检测图像中的物体,用 B模型来识别语音等。最后它会把这些子任务的结果汇总起来,用ChatGPT来生成一个完整的回答给你。
不过,本章并不会涉及太高深的,关于技术的部分。我们会给出一个简单的,将ChatGPT与AI绘图结合起来的示例,帮助你理解如何将不同的AI结合起来,发挥更多的用处。
除了文生图以外,你还可以将
ChatGPT与更多模型结合起来,例如用ChatGPT+MusicLM生成音乐,用ChatGPT+runaway GEN生成视频等等。
ChatGPT+midjourney生成文学作品配图
不知道你有没有留意过本文的插图,它们中的绝大部分都是使用midjourney生成的。Midjourney是一个由Midjourney, Inc.创建和托管的生成式人工智能程序和服务,以根据自然语言描述,也就是“提示”,生成图像。你可以想象任何东西,比如“一只猫在吃鱼”或者“一个蓝色的星球”,然后输入到Midjourney,它就会为你画出来。

图1 a happy baby cat astronaut, white background --ar 16:9 --v 5.1
截止到23年5月,我们仍然需要花很多心思,精心设计提示(输入的文字),才可以在midjourney上得到特别符合心意的结果。不过,类似于midjourney的绘图工具不断进化,门槛也在持续降低。与此同时,各种绘图工具也在持续整合到大语言模型中。例如,new bing与ChatGPT(到2023年5月止)就整合了OpenAI的dell-e绘图模型。
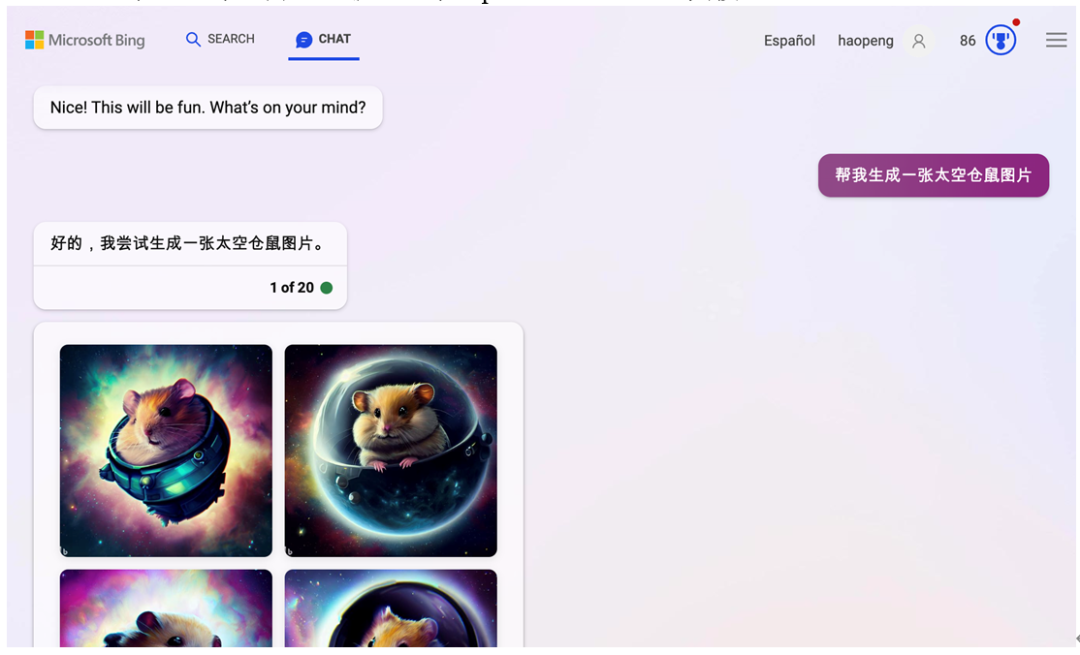
图2 用new bing调用dell-e模型生成太空仓鼠图片
不过,AI工具会进化,解决问题的思路却是有共性的。所以,本章的讲解会更加注重问题的分析与解决,也就是“授人以渔”。不管未来如何变化,这种思维方式都可以帮助你更好地利用它们。下面,我们将以“使用ChatGPT+midjourney给文学作品配图”作为例子,来设计一个可以重复使用的,由ChatGPT生成midjourney prompt的提示。
要使用ChatGPT与midjourney给文学作品配图,我们面临着三个困难:
不过,办法总比困难多,让我们试着解决一下这个问题:
第一步:确定作图流程
要获得可控,高质量的结果,我们需要一套固定流程。笔者并非设计与视觉传达相关的专业出身,不过我们有ChatGPT,就让我们来问问它。
对话7-11 分析插图流程

很棒,我们可以提取出其中的一部分流程,融入我们的提示撰写中。
第二步:解决问题1,确定作图流程
文学作品通常蕴含着丰富的情感和微妙的意象,想要通过图像表达出其中的信息并不是简单的事情。所以,我们需要根据第一步的分析来给ChatGPT作图的过程制定一个流程。
与此同时,Midjourney官方提供了一些质量非常高的教程[注:https://bit.ly/Clarinet-Prompt-Troubleshooting],其中笔者比较喜欢的一篇叫做“Clarinet’s Troubleshooting Midjourney Text Prompts”。这篇教程里,作者给midjourney prompt提供了一个模板,将其划分为1.Subject,2.Other Details & Surroundings,3.Stylizations, Media Type, Artists,4.Parameters四个部分。由于第4部分“Parameters”是可选的,所以我们让ChatGPT代劳工作量最大的前3部分。
那么,根据这个模板与步骤1中的分析,我们可以让将整个作图流程分为几步:
1. 理解文本内容,把握主题、氛围和故事情节。
2. 根据文本内容,选择合适的艺术风格和技术
3.设计构图和视觉元素:规划插图的构图和视觉元素。
4.根据分析,填写模板中的前3个元素
5.写出midjourney prompt
第三步:解决问题2,帮助ChatGPT理解midjourney prompt
我们需要让ChatGPT理解midjourney是什么,所以在开头应该为它介绍这个go
为了让ChatGPT理解midjourney prompt,我们可以有两种方法,第一种是直接把midjourney的教程贴给ChatGPT看,另外一种是用我们第六章第一节提到的“上下文学习方法”,为它提供几个输入-输出对的例子,为它提供范例。
第四步:根据分析,组装各个部分并写出prompt
最后,我们根据这样的设计思路把prompt组装起来,得到了一个ChatGPT+midjourney文学作品插图生成器。本书中的插图绝大多数都是由下面这个prompt,利用ChatGPT+midjourney得到的。让我们把它用在赫胥黎的小说《美丽新世界》中试试看。
需要注意的是,由于篇幅限制,midjourney的“说明书”部分我们并不在本书中展示,你可以将上文中提到的“Clarinet’s Troubleshooting Midjourney Text Prompts”整理后并粘贴进去,应该可以得到一样的效果。
对话7-12 ChatGPT+midjourney生成插图


我们把得到的midjourney prompt发送给midjourney的discord bot,可以得到下面的结果:

图3 midjourney生成的图像,版本5.1
不过,midjourney更新很快,你需要与时俱进地更新你提供给ChatGPT的教程,甚至需要重新设计整个prompt。你也不总是能够一次得到满意的结果,所以你会需要在ChatGPT生成的midjourney prompt的基础上进行调整,试验或者修改。
本文章出自北京大学出版社《ChatGPT进阶:提示工程入门》一书中,经授权此公号,略有修改,经出版纸质书为准。

编辑推荐
系统:全面剖析ChatGPT应用技巧,带你从小白变身ChatGPT应用专家。
实用:内含开箱即用的“提示公式”,聚焦ChatGPT实际应用。
有思路,有办法,能落地:带你将ChatGPT真正转化为生产力,开启AI驱动的工作流程。
简单易读:深入浅出,循序渐进,内含60 个示例,适合初学者和进阶读者。
深度:理论结合实际,涵盖提示工程学科深度讨论,授人以鱼更授人以渔。
扫码关注以下视频号,私信获取。
私信回复:送书,即可参与抽奖
活动截止时间:2024年1月13日0点
先到先得,送完即止
阅读过本文的人还看了以下文章:
TensorFlow 2.0深度学习案例实战
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《基于深度学习的自然语言处理》中/英PDF
Deep Learning 中文版初版-周志华团队
【全套视频课】最全的目标检测算法系列讲解,通俗易懂!
《美团机器学习实践》_美团算法团队.pdf
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
《深度学习:基于Keras的Python实践》PDF和代码
特征提取与图像处理(第二版).pdf
python就业班学习视频,从入门到实战项目
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
《Python数据分析与挖掘实战》PDF+完整源码
汽车行业完整知识图谱项目实战视频(全23课)
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx










