一、前言
NLP领域出现了ChatGPT,而CV领域也出现了SAM(Segment Anythimg Model)。那么作为地理人(其实不单单是地理人)的我们也不可只停留于原地,只会传统的方法,我们也要Fashion一波。本文以开源数据集、开源模型为例,构建一个用于遥感影像建筑物提取的语义分割模型。


二、构建思路
已有许多博文对深度学习进行过详尽的介绍,本文就不巴拉巴拉了。简单的讲,我们需要一个地球知识库(Earth knowledge base)即训练数据集和一个深度学习模型(Deep learning model)。一般的流程如下图所示:
构建地球知识库(Earth knowledge base)
构建深度学习模型(Deep learning model)
模型训练(Model training)
模型预测(Model prediction)
模型部署(Model deployment)
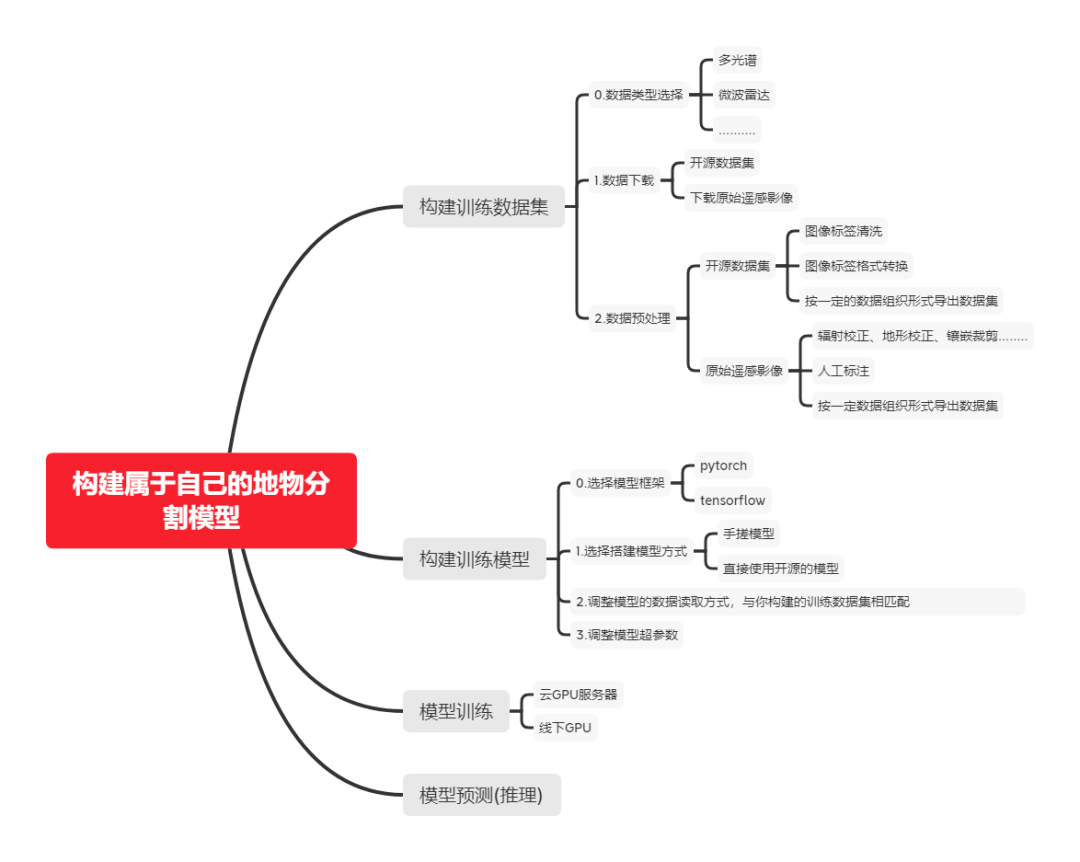
在上两节内容我们已经完成构建地球知识库(Earth knowledge base)即数据集的构建和深度学习模型(Deep learning model)选择。
三、模型训练(Model training)
目前训练深度学习模型主要分为线下训练和云上训练两大方式。
1.线下训练
线下训练是最为便捷,但需要条件较多。
1.一台高性能的主机(GPU+SSD固态)
2.电源稳定,不断电
3.计算机基本功扎实(解决配置环境和其他疑难杂症)
........
1.1 环境配置
win10+NVIDIA MX250显卡深度学习环境配置
注意:30系显卡与CUDA11.0以上版本才能兼容!!!

1.2 调试构建好的模型及数据加载
对你在第二步所构建好的模型进行调试。
调试的内容
1.数据加载进模型是否正确(dataset)
2.深度学习具体框架(pytorch 或者tensorflow)及模型所需的第三方包是否能满足
3.测试出合适的模型超参数(学习率、批大小等)
......
1.3 正式开始模型训练
模型训练是一个重复实验、不断调整模型超参数的过程,俗称为"炼丹"。
线下的话,建议把丹炉放在实验室,不要放宿舍,费电!!!

2.云上训练
对于线下机器不能满足训练的模型需求,则考虑上云,一些常见的云GPU平台如下:
无广告!!!,各平台大同小异,喜欢哪个都可以!!!
| featurize | 恒源云 |

| 
|
云端训练的优点
1.环境随意安装,上手简单
2.可根据自己的需求选择不同算力的GPU
3.可以实现多线程训练,压缩模型训练时间
4.不用担心人为因素干扰(误触误碰和不断电),可以安心睡觉
......
云端训练的缺点
1.数据集如果过大,上传将成为问题
2.要有充足的经费(💴)
......
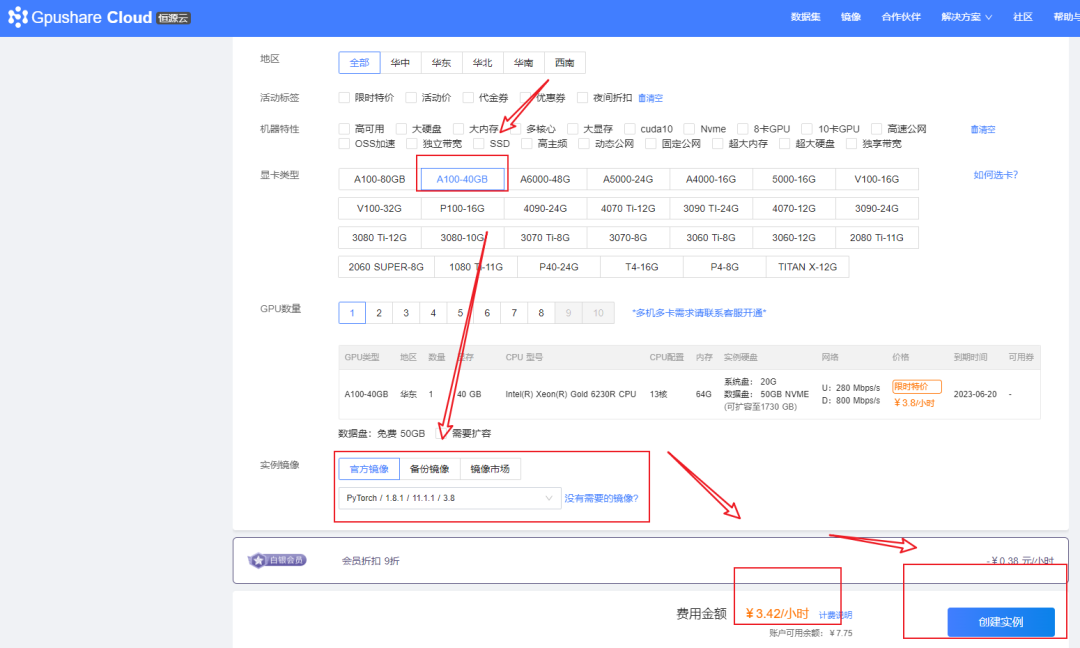
2.1 付费开机
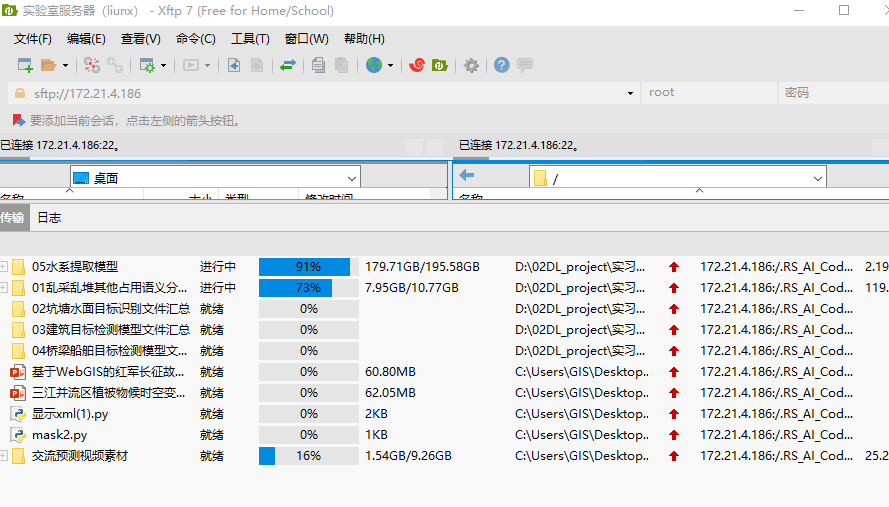
2.2 通过软件进行数据集传输
将数据集压缩打包,通过如Xshell或Xftp软件进行数据上传及操作。
2.3 对平台进行操作
这里可以通过在线的JupterLab或者通过VScode进行远程连接,进行模型及数据集解压,环境适配等工作,就可以开始训练。
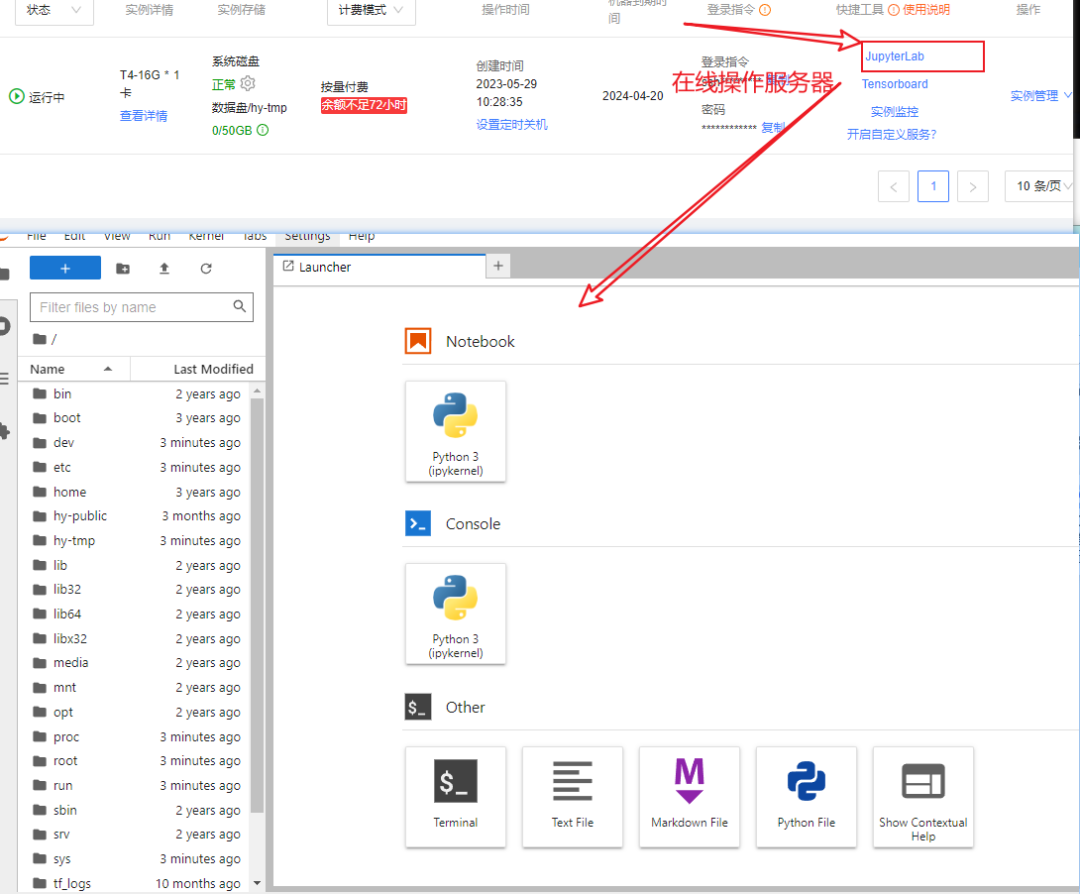
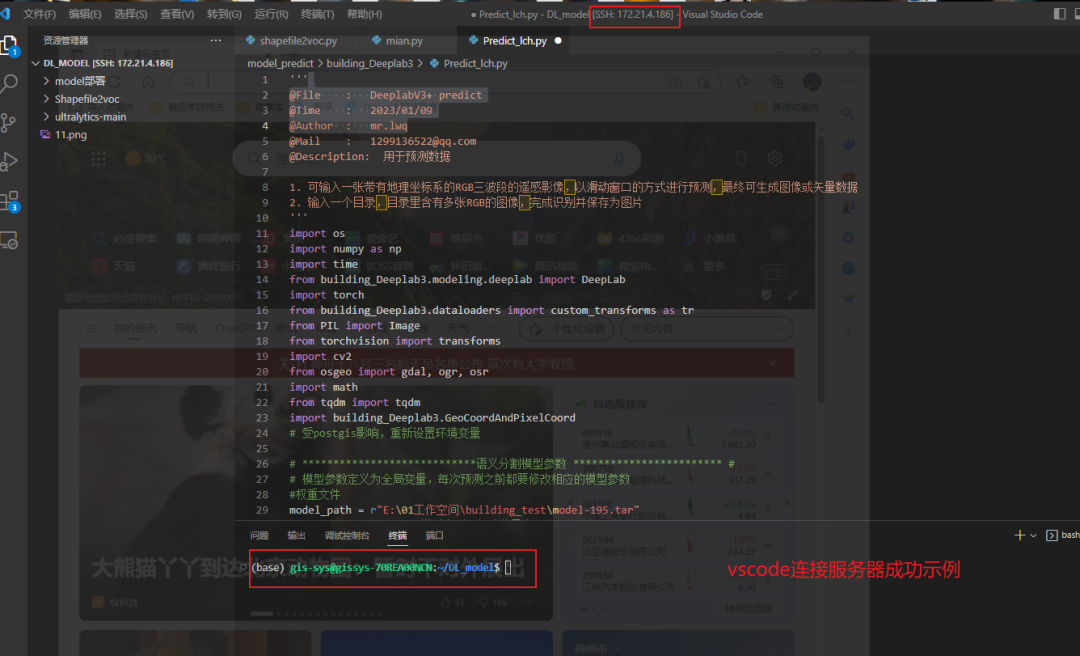
2.4 正式开始训练
填写相关超参数,输入命令开始训练,然后安安稳稳睡大觉,钱会自动扣的。
当然,模型往往不是一次就能训练好的,寻找合适的超参数使得模型精度达到最高,那是一个漫长的过程!
3.评估训练结果
1.评估模型训练过程
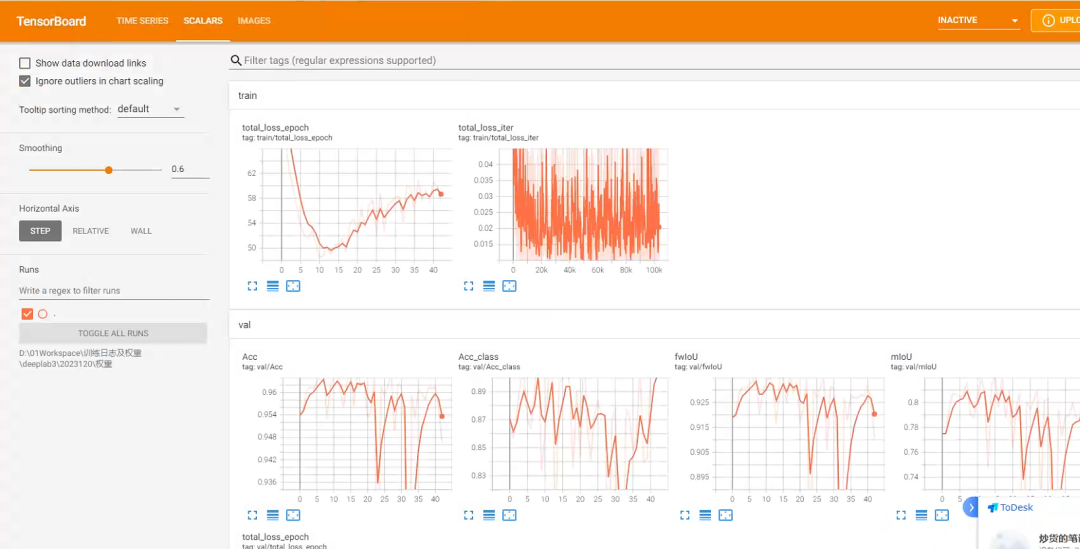
通过tensorboardX可视化;
其实可视化模型训练过程的库有很多,也可以直接输出TXT文档。tensorboardX是目前可视化的主流,并且示例代码使用的也是该包,更多信息自行查阅
在虚拟的python环境可通过conda/pip命令安装;
pip install tensorboard
pip install tensorflow
pip install tensorboardX
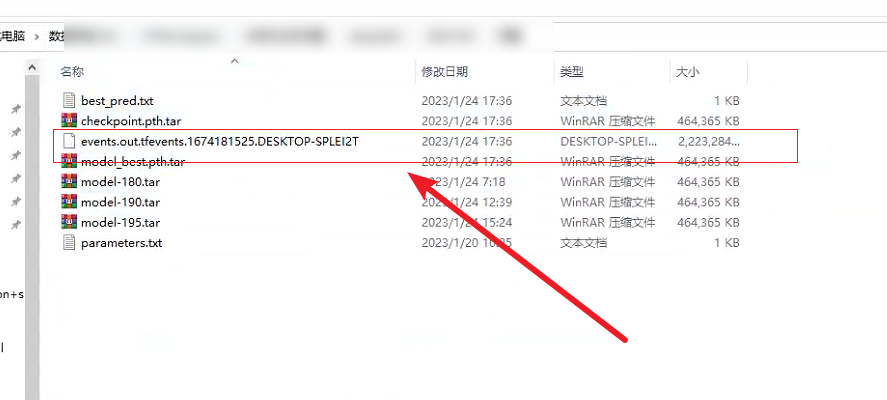
在浏览器中查看可视化结果(cmd启动tensorboardX)。一般该文件存储在run文件夹下。启动命令如下:
tensorboard --logdir=‘文件绝对路径’ tensorboard
–logdir=“D:\Pytorch深度学习入门\biLSTM_attn-master\logs”
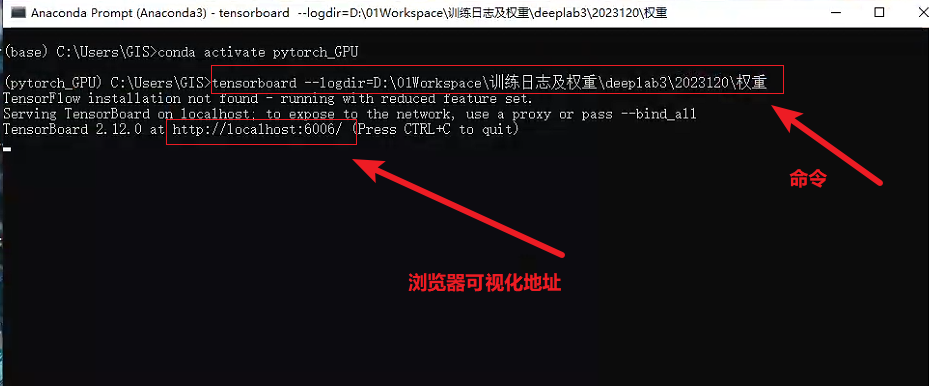
打开就知道训练及验证过程的各种参数的变化,如何看,也是自行查阅,篇幅有限,无法一一介绍。
 i
i2.采用测试集对其精度评估
验证集只能代表模型在数据集上的评估精度,与真实测试结果有较大差异。
该部分内容留到下一节模型预测再讲述









