
向AI转型的程序员都关注了这个号👇👇👇
前言
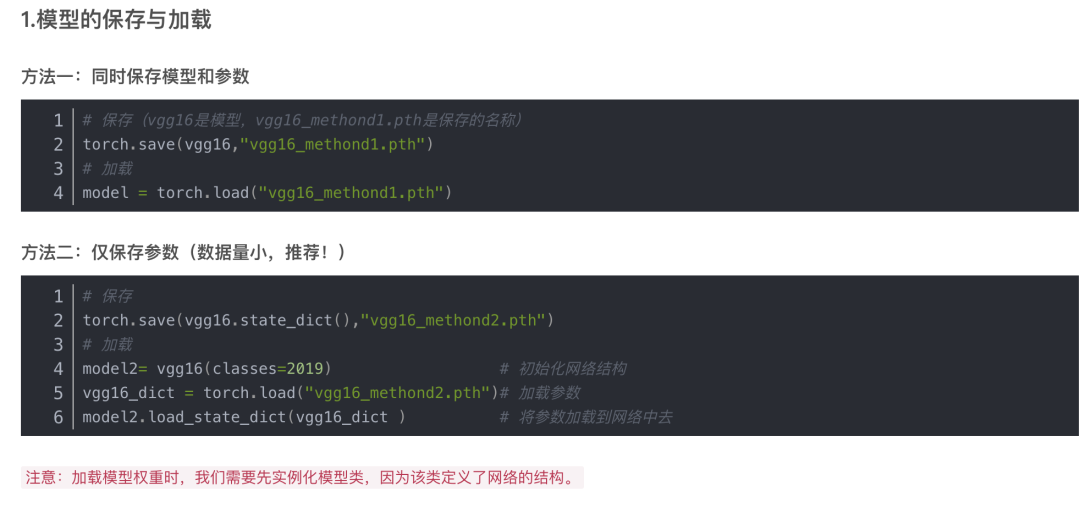
1.模型的保存与加载
方法一:同时保存模型和参数
方法二:仅保存参数(数据量小,推荐!)
2.断点的保存与加载
3.预训练模型的使用
4.模型的冻结
方法一:设置requires_grad为False
方法二:使用 with torch.no_grad()
总结
5.模型的特殊加载方式和加载技巧
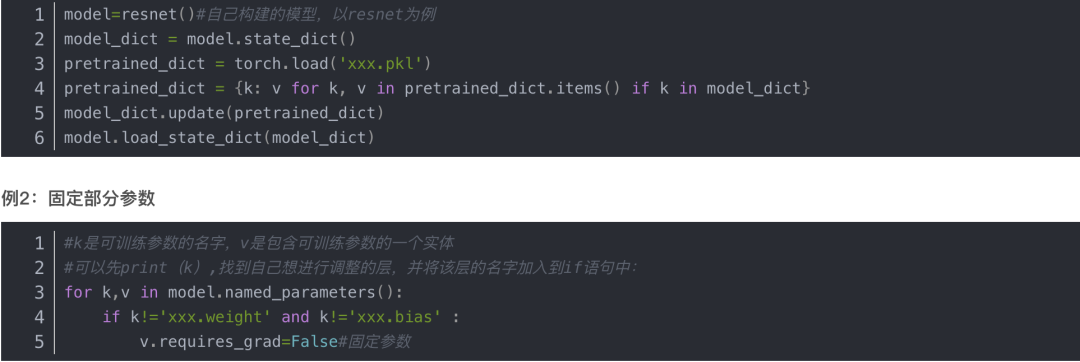
例1:加载预训练模型,并去除需要再次训练的层
例2:固定部分参数
例3:训练部分参数
例4:检查部分参数是否固定
6.单GPU训练与多GPU训练
Pytorch 使用单GPU训练
方法一 .cuda()
方法二 .to(device)
前言
在我们训练模型时,会经常使用一些小技巧,包括:模型的保存与加载、断点的保存与加载、模型的冻结与预热、模型的预训练与加载、单GPU训练与多GPU训练。这些在我们训练网络的过程中会经常遇到。
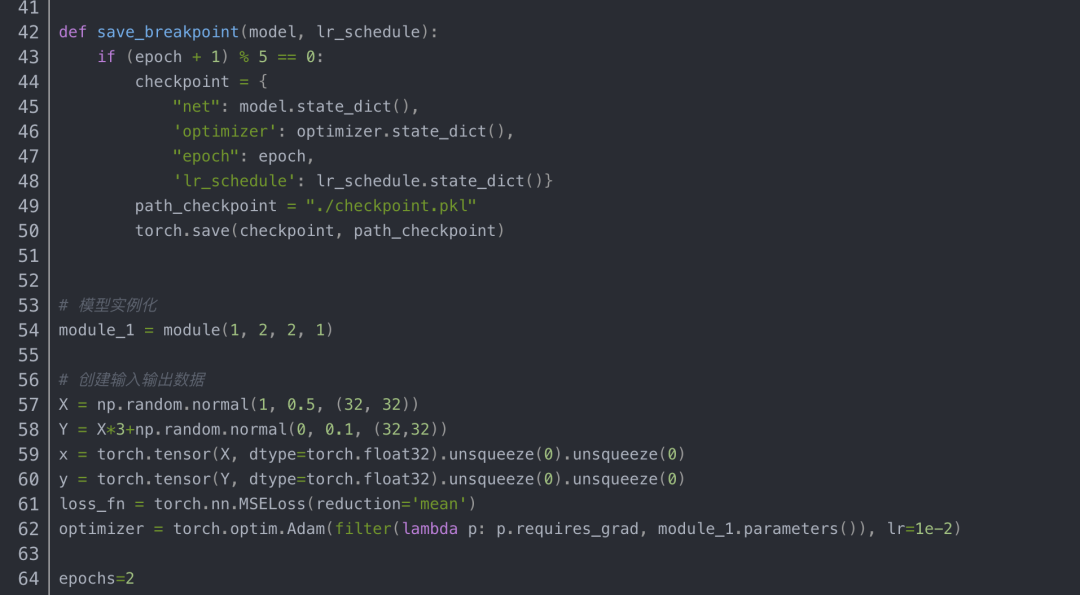
2.断点的保存与加载
如果模型的训练时间非常长,而这中间发生了一点小意外,使得模型终止训练,而下次训练时为了节省时间,让模型从断点处继续训练,这就需要在模型训练的过程中保存一些信息,使得模型发生意外后再次训练能从断点处继续训练。所以在模型训练过程中记录信息(checkpoint)是非常重要的一点。模型训练的五个过程:数据、损失函数、模型、优化器、迭代训练。这五个步骤中数据和损失函数是没法改变的,而在迭代训练的过程中模型的一些可学习参数和优化器中的一些缓存是会变的,所以需要保留这些信息,另外还需要保留迭代的次数和学习率。
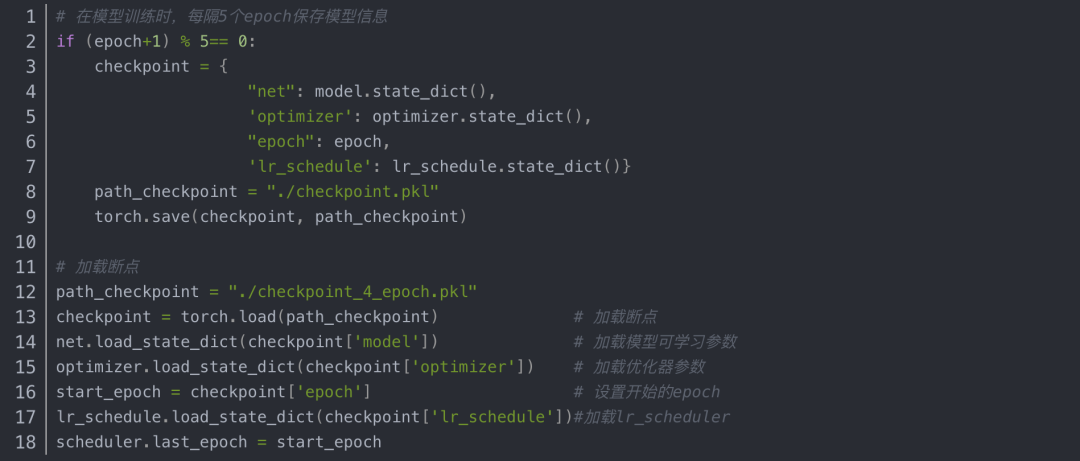
在运行推理之前,必须调用model.eval()以将 dropout 和批量标准化层设置为评估模式。不这样做会产生不一致的推理结果。如果是像希望恢复训练,就调用model.train()以确保这些层处于训练模式。
3.预训练模型的使用
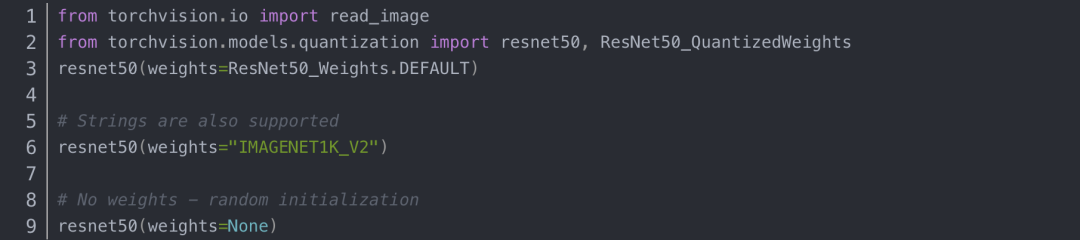
pytorch自带有一些高级的复杂模型,有两种使用的方式;
方法一:用torchvision.models函数调用,例如torchvision.models.densenet169(pretrained=True)就调用了densenet169的预训练模型。先来看看这个模块涵盖了哪些模型:见https://pytorch.org/vision/stable/models.html获取详细信息。像resnet50
方法二:下载训练好了的参数:
在网站中下载好参数,然后直接加载进网络。
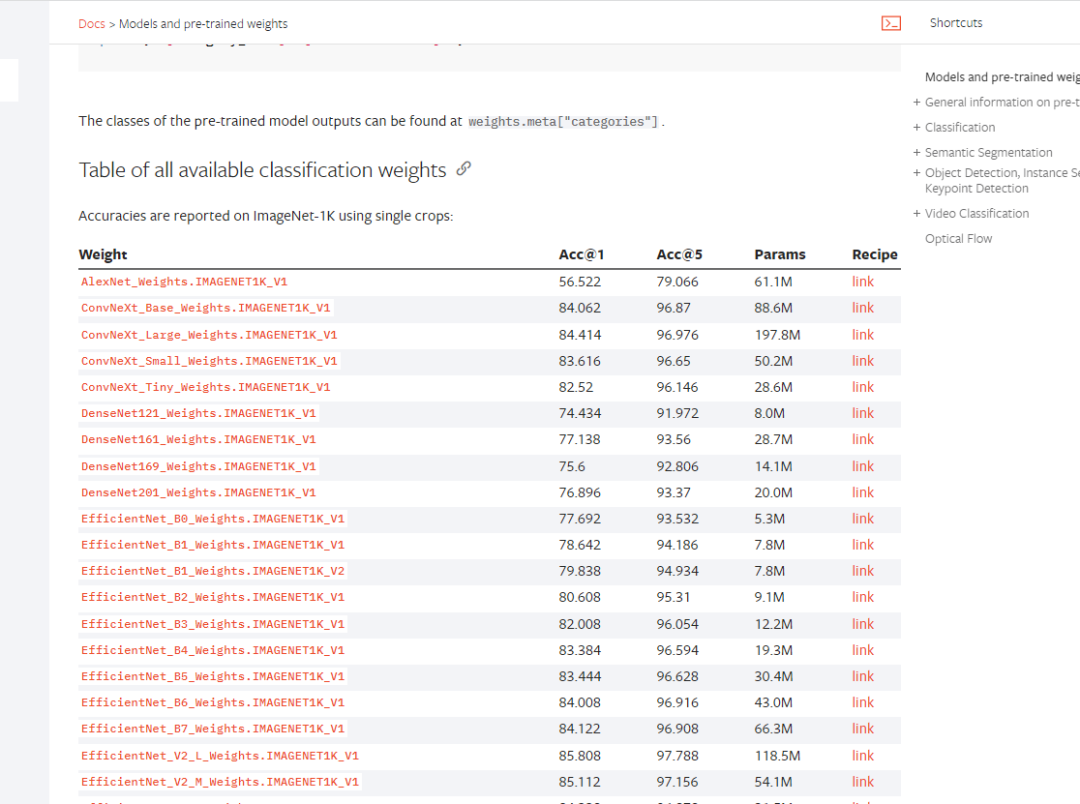
网站还是上面的那个网站,往下翻就能找到。而且不仅仅是分类的模型,语义分割、量化、对象检测、实例分割和人物关键点检测等等。在这里都能找到
4.模型的冻结
在迁移学习或训练新的复杂模型时,加载部分模型是常见的情况。利用训练好的参数,有助于热启动训练过程,并希望帮助你的模型比从头开始训练能够更快地收敛。
方法一:设置requires_grad为False
这种方法的效果是:被冻结的层可以前向传播,也可以反向传播,只是自己这一层的参数不更新,其他未冻结层的参数正常更新。要注意优化器要加上filter:(别的文章都说需要加,但是我用代码测试发现不加好像也可以)
optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, perception.parameters()), lr=learning_rate)

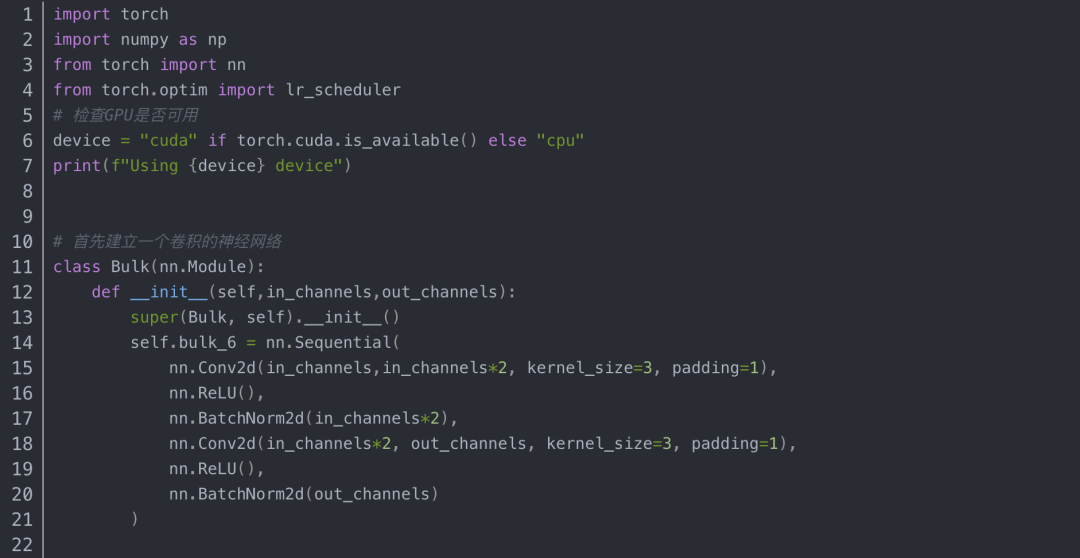
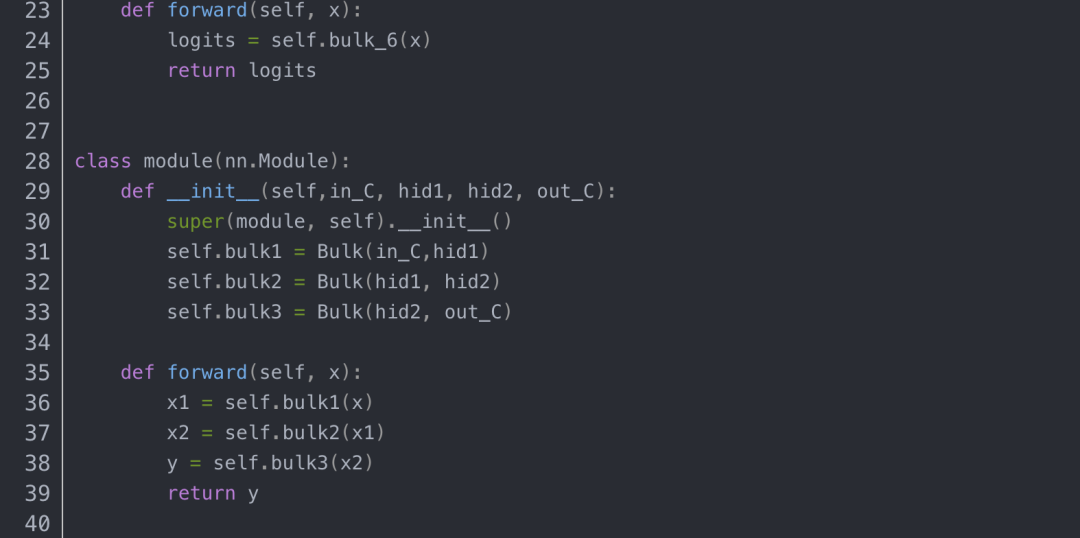
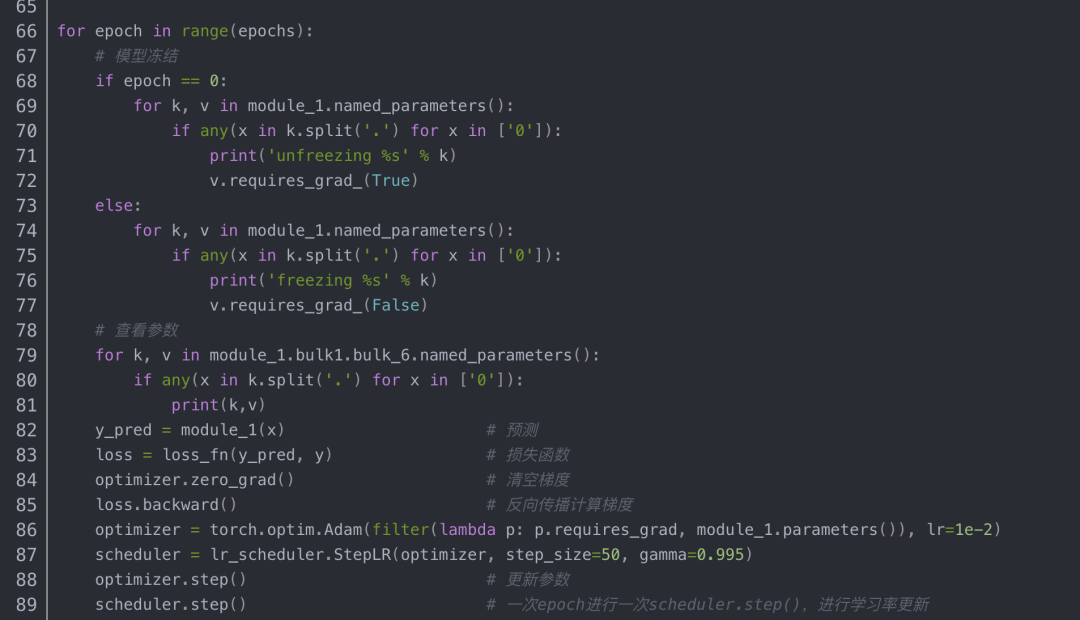

梯度正常更新时, 所有层都参与训练,下面是bulk6.0层训练前后的变化:
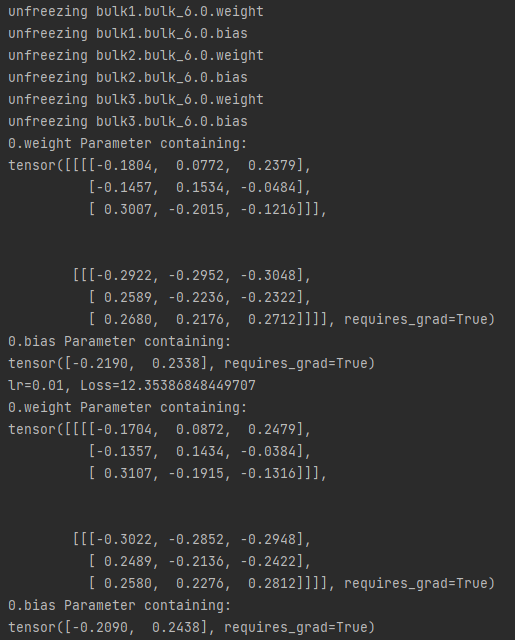
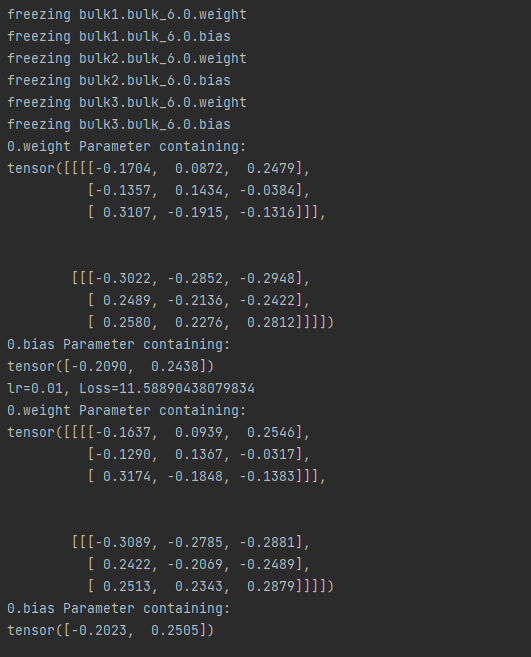
梯度停止更新时, bulk6.0层不参与训练,下面是bulk6.0层训练前后的变化:
方法二:使用 with torch.no_grad()
该方法的性质:
这种方式只需要在网络定义中的forward方法中,将需要冻结的层放在 with torch.no_grad()下。
放入with torch.no_grad()中的网络层,可以前向传播,但反向传播被阻断,自己这层(如self.layer2)和前面的所有与之相关的层(如self.layer1)的参数都会被冻结,不会被更新。但如果前面的层除了和self.layer2相关外,还与其他层有联系,则与其他层联系的部分正常更新。
还是直接看例子:
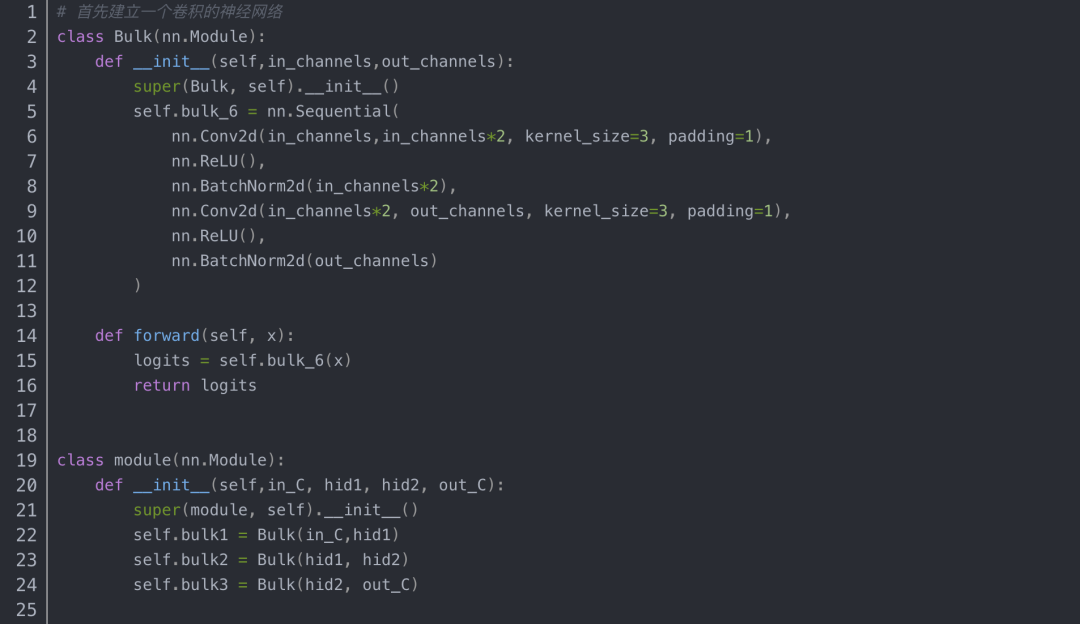
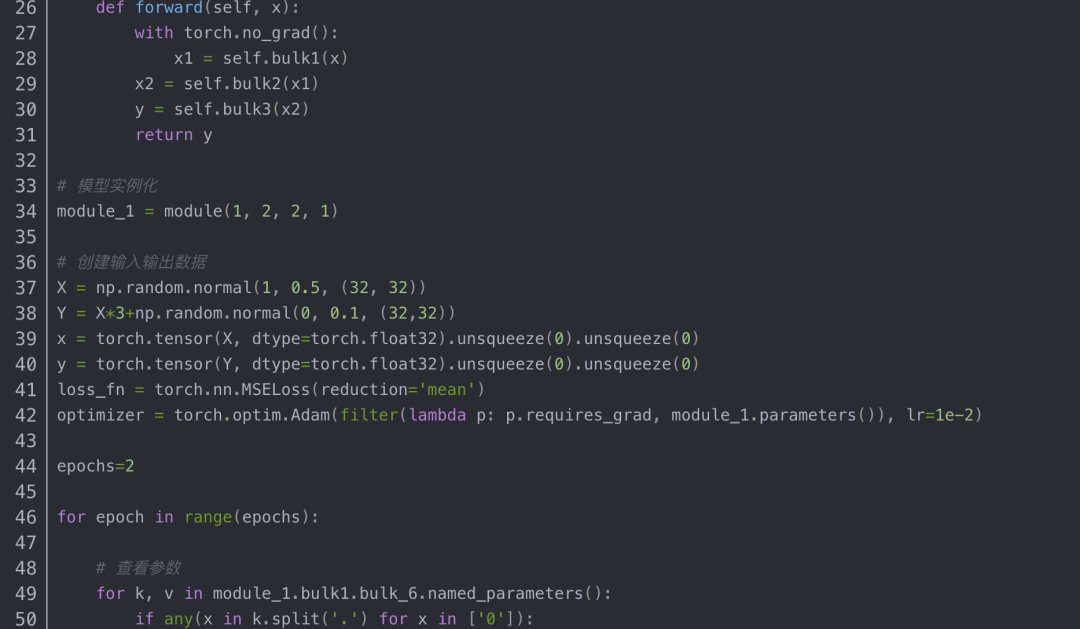
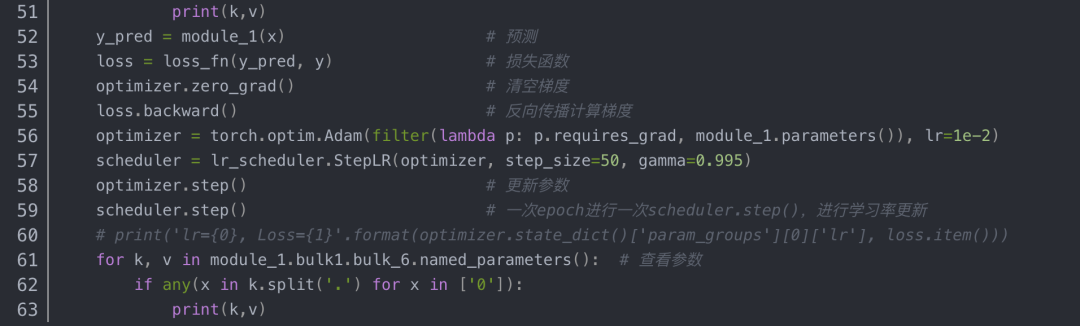
例子中的模型是由三个网络块构成,其中bulk1被with torch.no_grad()屏蔽,不参与参数更新。实验结果如下:bulk1中的网络层在运行了一个epoch后权重没变。
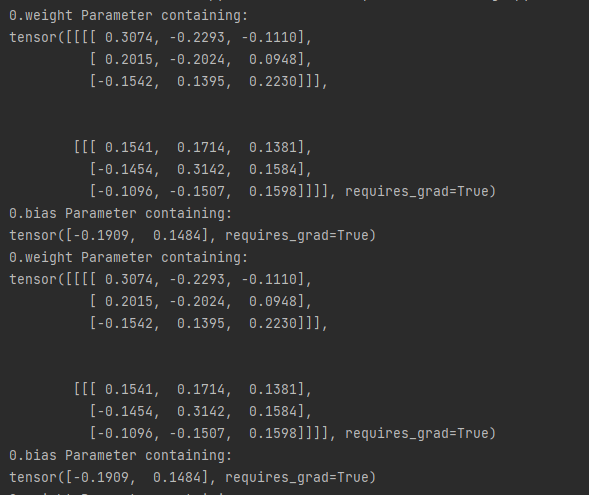
总结
方法一:比较灵活,但是写起来麻烦。
方法二:不能单独屏蔽某一个epoch,但是使用起来简单便捷,大多数的情况下其实都是够用的。
这里我再推荐一篇文章【pytorch】筛选冻结部分网络层参数同时设置有参数组的时候该怎么办?
5.模型的特殊加载方式和加载技巧
例1:加载预训练模型,并去除需要再次训练的层
注意:需要重新训练的层的名字要和之前的不同。
例3:训练部分参数
#将要训练的参数放入优化器
optimizer2=torch.optim.Adam(params=[model.xxx.weight,
model.xxx.bias],lr=learning_rate,betas=(0.9,0.999),weight_decay=1e-5)

需要注意的是,如果操作失误,loss函数几乎不会发生变化,一直处于最开始的状态,这很可能是因为所有参数都被固定了。
6.单GPU训练与多GPU训练
GPU处理大规模的矩阵数据的速度可以比CPU快50-100倍,所以用GPU来跑算法是很有必要的。
Pytorch 使用单GPU训练
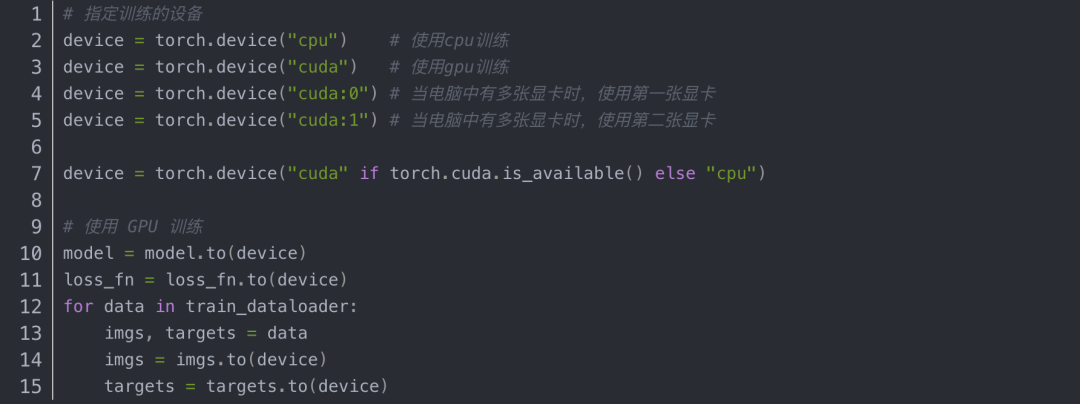
使用 GPU 训练只需要在原来的代码中修改几处就可以了。只需要将需要在GPU上运行的模型和数据都搬过去,剩下的就和在CPU上运行的程序是一样的了,我们有两种方式实现代码在 GPU 上进行训练,
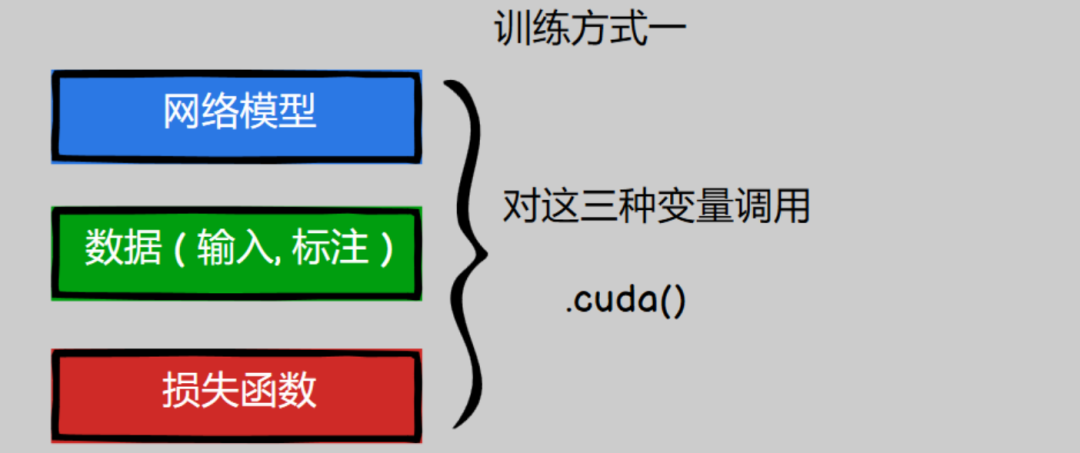
方法一 .cuda()
我们可以通过对网络模型,数据,损失函数这三种变量调用 .cuda() 来在GPU上进行训练

方法二 .to(device)
机器学习算法AI大数据技术
搜索公众号添加: datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
TensorFlow 2.0深度学习案例实战
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《基于深度学习的自然语言处理》中/英PDF
Deep Learning 中文版初版-周志华团队
【全套视频课】最全的目标检测算法系列讲解,通俗易懂!
《美团机器学习实践》_美团算法团队.pdf
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
《深度学习:基于Keras的Python实践》PDF和代码
特征提取与图像处理(第二版).pdf
python就业班学习视频,从入门到实战项目
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
《Python数据分析与挖掘实战》PDF+完整源码
汽车行业完整知识图谱项目实战视频(全23课)
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx










