将 ScienceAI 设为星标
第一时间掌握
新鲜的 AI for Science 资讯


编辑 | 萝卜皮
未经分类的「退役电池」具有不同的正极材料,由于其正极特定的性质,阻碍了直接回收的采用。报废电池的激增需要精确分类以实现有效的直接回收,但不同的运营历史、不同的制造商以及回收合作者(数据所有者)的数据隐私问题带来了挑战。
清华大学团队展示了,从涵盖 5 种阴极材料和 7 家制造商的 130 块锂离子电池的独特数据集中,联邦机器学习方法可以对这些退役电池进行分类,而无需依赖过去的运营数据,从而保护回收合作者的数据隐私。
通过利用从报废充放电循环中提取的特征,该团队的模型在同质和异质电池回收设置下分别表现出 1% 和 3% 的阴极排序误差,这归因于他们创新的 Wasserstein 距离投票策略。
从经济角度来看,所提出的方法强调了精确电池分类对于繁荣和可持续回收行业的价值。这项研究预示着一种使用来自不同来源的隐私敏感数据的新范例,促进分布式系统的协作和尊重隐私的决策。
该研究以「Collaborative and privacy-preserving retired battery sorting for profitable direct recycling via federated machine learning」为题,于 2023 年 12 月 5 日发布在《Nature Communications》。

锂电池直接回收存在挑战性
锂离子电池(LIB)作为储能器件,已成为从工业生产到日常生活的各个领域的广泛应用,成为公认的技术路线。预测表明,到 2030 年,全球锂离子电池生产规模将超过 1.3 TWh,届时对电池不断增长的需求将远远超过锂和钴等重要金属资源的供应量。
然而,目前锂离子电池产品的平均寿命为 5-8 年,导致许多国家的退役电池即将激增。如果管理不当,退役电池将导致不可持续的资源浪费和不可逆的环境危害。鉴于这种情况,在我们面临即将到来的锂离子电池退役浪潮时,电池回收技术的发展显得至关重要。
电池回收研究的最新进展集中在火法冶金、湿法冶金和直接回收方法上。与火法冶金和湿法冶金方法相比,直接回收是一种独特的方法。该过程不会对材料结构造成二次损伤,能够更高效地进行结构修复和性能恢复。此外,直接回收具有更高的盈利能力,因为它可以降低能源消耗、减少温室气体排放和减轻环境足迹。
然而,在实际生产中,电池回收商经常遇到包含未知组件的锂离子电池或由不同正极材料类型的混合物组成的电池模块。考虑到直接回收可能在很大程度上是针对阴极的,这种复杂性使得直接回收的应用无法实现退役电池的价值转换。
需要强调的是,即使可以使用传统的回收策略从混合正极材料类型中提取重要金属,回收过程中不同正极材料之间的相互作用也会对产品质量产生不利影响。因此,了解回收方面的正极材料类型信息显著影响直接回收路线的选择,并最终提高产品质量、盈利能力和可持续性。
联邦机器学习是不错的解决方法
联邦机器学习作为一种分布式和隐私保护范式,有潜力通过协作机器学习解决多方协作(相当于电池数据量和多样性)和隐私问题。在每次训练迭代中,分布式数据所有者利用其本地计算能力执行本地训练,对训练后的模型参数/结果进行加密,并将其上传到中央协调器进行聚合。
事实上,原始数据集永远不会离开其各自的数据所有者,并且传输的参数/结果经过适当加密以保护数据隐私。联邦机器学习已在许多应用领域得到广泛研究,包括公共卫生、临床诊断、电子商务、物联网、移动计算和智能电网。
这种方法可以通过实现隐私保护协作,特别是对于那些数据访问受限的人来说,彻底改变广泛能源领域的数据驱动研究范式。关于电池回收领域,联邦机器学习假设有可能利用已经存在但由于隐私问题而无法共享的大量电池数据。通过这种协作且保护隐私的范例,可以实现高精度、高效率、可扩展性和通用性的退役电池分类,从而优化回收电池的质量和盈利能力。目前为止,还从未有过针对电池回收的联邦机器学习研究的报道。
用于电池直接回收的新模型
在最新的研究中,清华大学的研究人员利用多个合作者的现有电池数据(电池制造商、实际应用运营商、学术研究机构和第三方平台)用机器学习方法对退役电池进行正极材料分类。
该团队的联邦机器学习模型仅使用一个周期的现场测试数据通过标准化特征提取过程进行训练,而无需事先了解历史操作条件。研究人员将联邦机器学习模型的预测能力与基于本地数据的独立学习本地模型在同质和异构电池回收情况下的预测能力进行了比较。
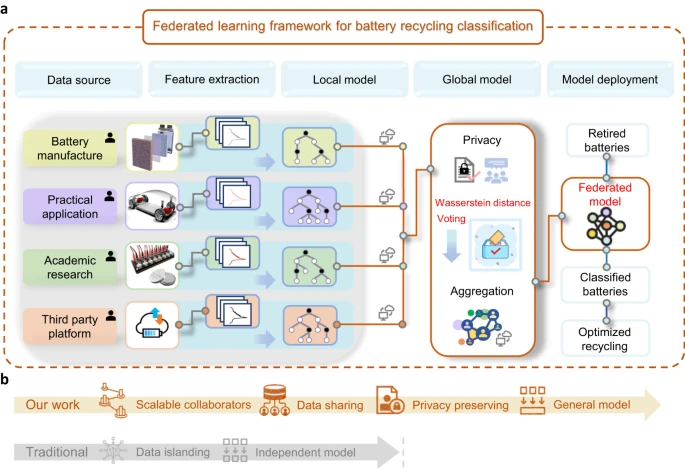
图:退役电池分类回收的联邦机器学习框架。(来源:论文)在均匀设置下,该团队获得了 1% 的正极材料分选误差;在异质环境中,由于 Wasserstein 距离投票策略,研究人员获得了 3% 的正极材料排序误差。
这样的准确度是通过以下方式实现的:(1)自动探索显著特征中的独特模式,而不假设对历史操作条件有任何先验知识;(2)使用他们提出的 Wasserstein 距离投票策略来纠正回收合作者之间的异构数据分布。经济评估展示了准确的退役电池分类对于使用直接回收的有利可图的电池回收行业的相关性和必要性。
总的来说,该方法可以补充现有的基于第一原理的回收路线研究范式在实际电池回收实践中的应用,其中退役电池是必要的,同时又难以分类。该工作启发了利用来自多个数据所有者的现有数据,而不是额外耗时和昂贵的数据生成,以协作的方式开发和优化复杂的决策程序,如电池回收路线设计,同时保护隐私。
论文链接:https://www.nature.com/articles/s41467-023-43883-y
人工智能 × [ 生物 神经科学 数学 物理 化学 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。









