随着现实的人脸操作技术取得了显著的进步,社会对这些技术可能被恶意滥用的担忧引发了人脸伪造检测的新研究课题。然而,这是极具挑战性的,因为最近的技术进步能够打造出超出人眼感知能力的人脸,尤其是在压缩图像和视频中。我们发现,在意识到频率的情况下挖掘伪造模式可能是一种治疗方法,因为频率提供了一种互补的观点,可以很好地描述细微的伪造伪像或压缩错误。为了将频率引入人脸伪造检测,提出了一种新的人脸伪造网络中的频率(F3-Net),利用两种不同但互补的频率感知线索,1)频率感知分解图像分量和2)局部频率统计,通过双流协同学习框架深入挖掘伪造模式。应用DCT作为应用的频域变换。通过全面的研究,在具有挑战性的FaceForensics++数据集中,所提出的F3-Net在所有压缩质量上都显著优于竞争对手的最先进方法,尤其是在低质量媒体上取得了巨大领先。
目前最先进的人脸操作算法,如DeepFake、FaceSwap、Face2Face和NeuralTextures,已经能够隐藏伪造伪像,因此发现这些精制伪像的缺陷变得极其困难,如下图(a)所示。
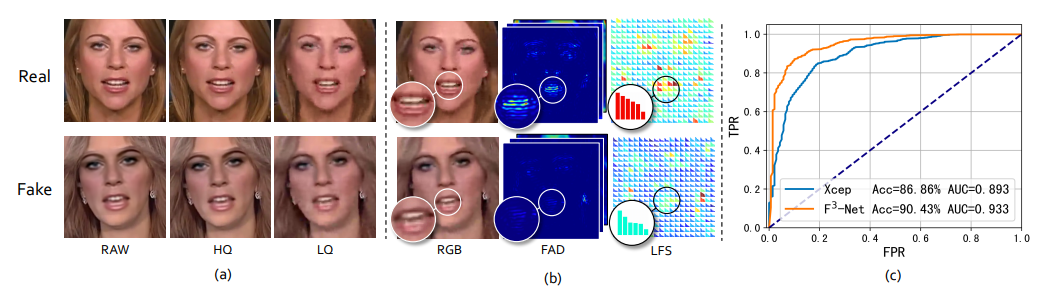
更糟糕的是,如果伪造人脸的视觉质量大幅下降,例如用JPEG或H.264以较大的压缩比进行压缩,伪造伪像将受到压缩误差的污染,有时无法在RGB域中捕获。幸运的是,正如许多先前的研究所表明的那样,与真实人脸相比,这些伪影可以以不寻常的频率分布的形式在频域中捕捉到。然而,如何将频率感知线索纳入深度学习的CNN模型中?这个问题也随之而来。传统的频域,如FFT和DCT,与自然图像所具有的移位不变性和局部一致性不匹配,因此普通的CNN结构可能是不可行的。因此,如果我们想利用可学习CNN的判别表示能力进行频率感知人脸伪造检测,那么CNN兼容的频率表示就变得至关重要。为此,我们想介绍两种频率感知伪造线索,它们与深度卷积网络的知识挖掘相兼容。
从一个方面来看,可以通过分离图像的频率信号来分解图像,而每个分解的图像分量指示特定的频带。因此,第一个频率工件伪造线索是通过直觉发现的,即我们能够识别出在具有较高频率的分解分量中稍微突出的细微伪造工件(即,以不寻常图案的形式),如上图(b)中间一列所示。这条线索与CNN结构兼容,并且对压缩伪影具有惊人的鲁棒性。
从另一个方面来看,分解后的图像分量描述了空间域中的频率感知模式,但没有直接在神经网络中明确地呈现频率信息。建议将第二个频率感知伪造线索作为局部频率统计。在每个密集但有规律采样的局部空间补丁中,通过对每个频带的平均频率响应进行计数来收集统计数据。这些频率统计信息重新组合回多通道空间图,其中通道的数量与频带的数量相同。如上图(b)的最后一列所示,伪造人脸与相应的真实人脸相比具有不同的局部频率统计,尽管它们在RGB图像中看起来几乎相同。此外,局部频率统计也遵循输入RGB图像的空间布局,因此也享受到由CNN提供的有效表示学习。同时,由于分解后的图像分量和局部频率统计信息是互补的,但两者具有本质上相似的频率感知语义,因此它们可以在特征学习过程中逐步融合。
因此,提出了一种新颖的人脸频率伪造网络(F3-Net),该网络利用了上述频率感知伪造线索。该框架由两个频率感知分支组成,一个旨在通过频率感知图像分解(FAD)学习细微的伪造模式,另一个则希望从局部频率统计(LFS)中提取高级语义来描述真实人脸和伪造人脸之间的频率感知统计差异。这两个分支通过交叉注意力模块(即MixBlock)进一步逐渐融合,该模块鼓励上述FAD和LFS分支之间的丰富互动。整个人脸伪造检测模型是通过交叉熵损失以端到端的方式学习的。
大量实验表明,通过彻底的烧蚀研究,所提出的F3-Net显著提高了低质量伪造介质的性能。还表明,在具有挑战性的FaceForensics++中,新提出的框架在所有压缩质量上都大大超过了竞争对手的技术水平。如上图(c)所示,通过将ROC曲线与Xception进行比较,可以明显证明所提出的频率感知F3-Net的有效性和优越性。
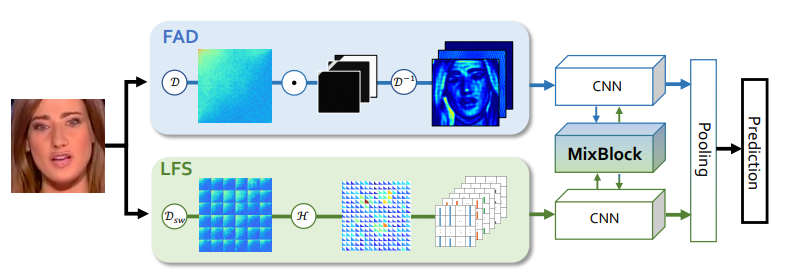
所提出的体系结构由三种新方法组成:通过频率感知图像分解学习细微操纵模式的FAD;用于提取局部频率统计的LFS和用于协作特征交互的MixBlock。
FAD: Frequency-Aware Decomposition
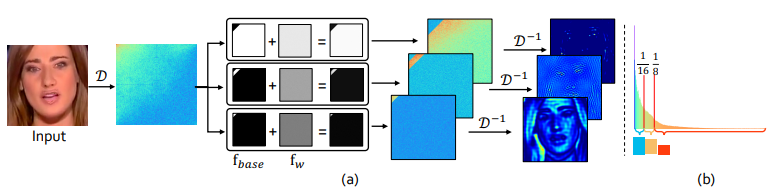
对于频率感知图像分解,以前的研究通常在空间域中应用手工制作的滤波器组,因此无法覆盖整个频域。同时,固定的滤波配置使得难以自适应地捕获伪造模式。为此,我们提出了一种新的频率感知分解(FAD),根据一组可学习的频率滤波器在频域中自适应地分割输入图像。分解后的频率分量可以逆变换到空间域,从而产生一系列频率感知图像分量。这些组件沿着通道轴堆叠,然后输入到卷积神经网络中(在我们的实现中,我们使用Xception作为主干),以全面挖掘伪造模式。
LFS: Local Frequency Statistics
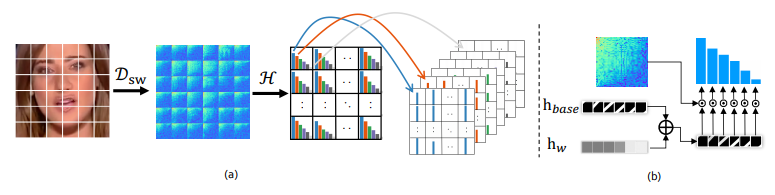
(a) 提出了局部频率统计(LFS)来提取局部频域的统计信息。SWDCT表示应用滑动窗口离散余弦变换,H表示自适应地收集每个网格上的统计信息。(b) 从DCT功率谱图中提取统计数据。
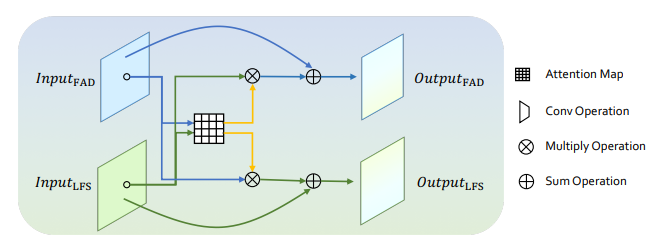
The proposed MixBlock
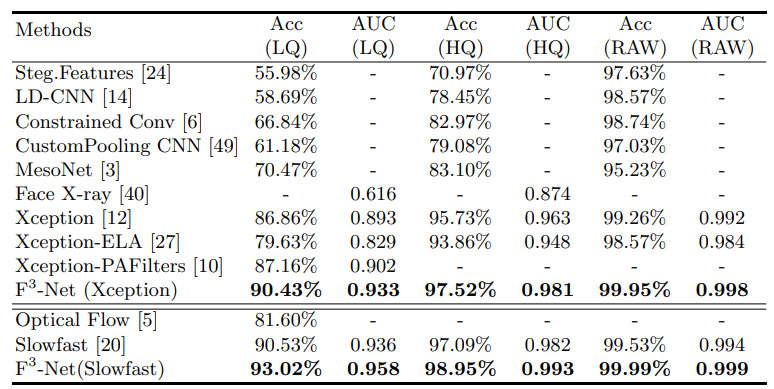
下表的对比很好的表现了F3-Net在低质量图片中的表现,可见在频域内做检测确实有更好的抗压缩性能。
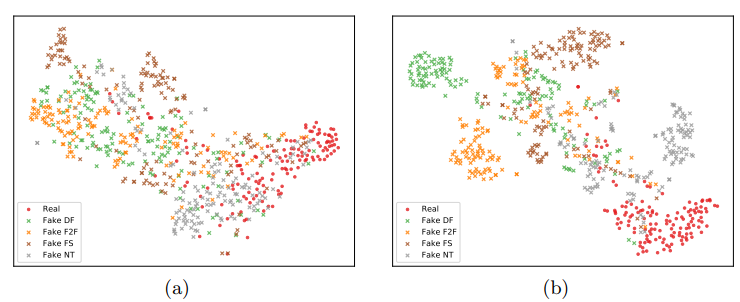
FaceForensics++低质量(LQ)任务上基线(a)和F3-Net(b)的t-SNE嵌入可视化。红色表示真实视频,其余颜色表示通过不同操作方法生成的数据。

转载请联系本公众号获得授权
计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
- Sparse R-CNN:稀疏框架,端到端的目标检测(附源码)









