将 ScienceAI 设为星标
第一时间掌握
新鲜的 AI for Science 资讯

编辑 | 绿萝
逆合成旨在寻找能够合成目标化合物的反应物和合成路径。
利用人工智能实现逆合成自动化可加快数字实验室中的有机化学研究。然而,大多数现有的深度学习方法都很难解释,就像一个缺乏洞察力的「黑匣子」。
在此,来自山东大学、湖南大学、天津大学和电子科技大学的研究团队提出了 一种基于分子组装的深度学习方法 RetroExplainer,将逆合成任务公式化为分子组装过程。能够实现精准逆合成可解释预测以及路径规划。
为了保证模型的稳健性能,研究人员提出了三个深度学习模块:多含义(multi-sense )多尺度图 Transformer、结构感知对比学习和动态自适应多任务学习。
12 个大型基准数据集的结果证明了 RetroExplainer 的有效性,其性能优于最先进的单步逆合成方法。此外,分子组装过程使其模型具有良好的可解释性,允许透明的决策和定量归因。当扩展到多步骤逆合成计划时,RetroExplainer 已识别出 101 条途径,其中 86.9% 的单步反应与文献中已报道的反应相对应。
因此,RetroExplainer 有望为药物开发中可靠、高通量和高质量的有机合成提供有价值的见解。
该研究以「Retrosynthesis prediction with an interpretable deep-learning framework based on molecular assembly tasks」为题,于 2023 年 10 月 3 日发布在《Nature Communications》上。

逆合成旨在确定一组合适的反应物以有效合成目标分子,这在计算机辅助合成规划中是不可或缺的基础。
近年来,随着化学反应数据的积累和人工智能技术的发展,产生许多基于数据驱动的逆合成方法,使得化学家在设计合成实验时节省了大量成本并提升了合成效率。
尽管现有的逆合成方法在加速数据驱动的逆合成预测方面取得了显著进展,但它们仍然存在以下主要问题:
(1)基于序列的方法会丢失有关分子的先验信息。同时,基于图的方法忽略了序列信息和远程特征。这两种方法都受到特征表示学习的限制,限制了性能的进一步提高。
(2)许多现有的基于深度学习的逆合成方法面临可解释性差的问题。
(3)大多数现有方法侧重于单步逆合成预测,该预测能够生成看似合理的反应物,但可能无法购买,并且通常伴随着繁琐的人工选择预测过程。因此,从产物到可及反应物的路径规划的多步逆合成预测对于实际化学合成中的实验研究人员来说更有意义。
基于此,研究人员提出了 RetroExplainer,一种化学知识和深度学习引导的分子组装方法,用于具有定量解释性的逆合成预测。该方法的总体框架如图 1 所示。
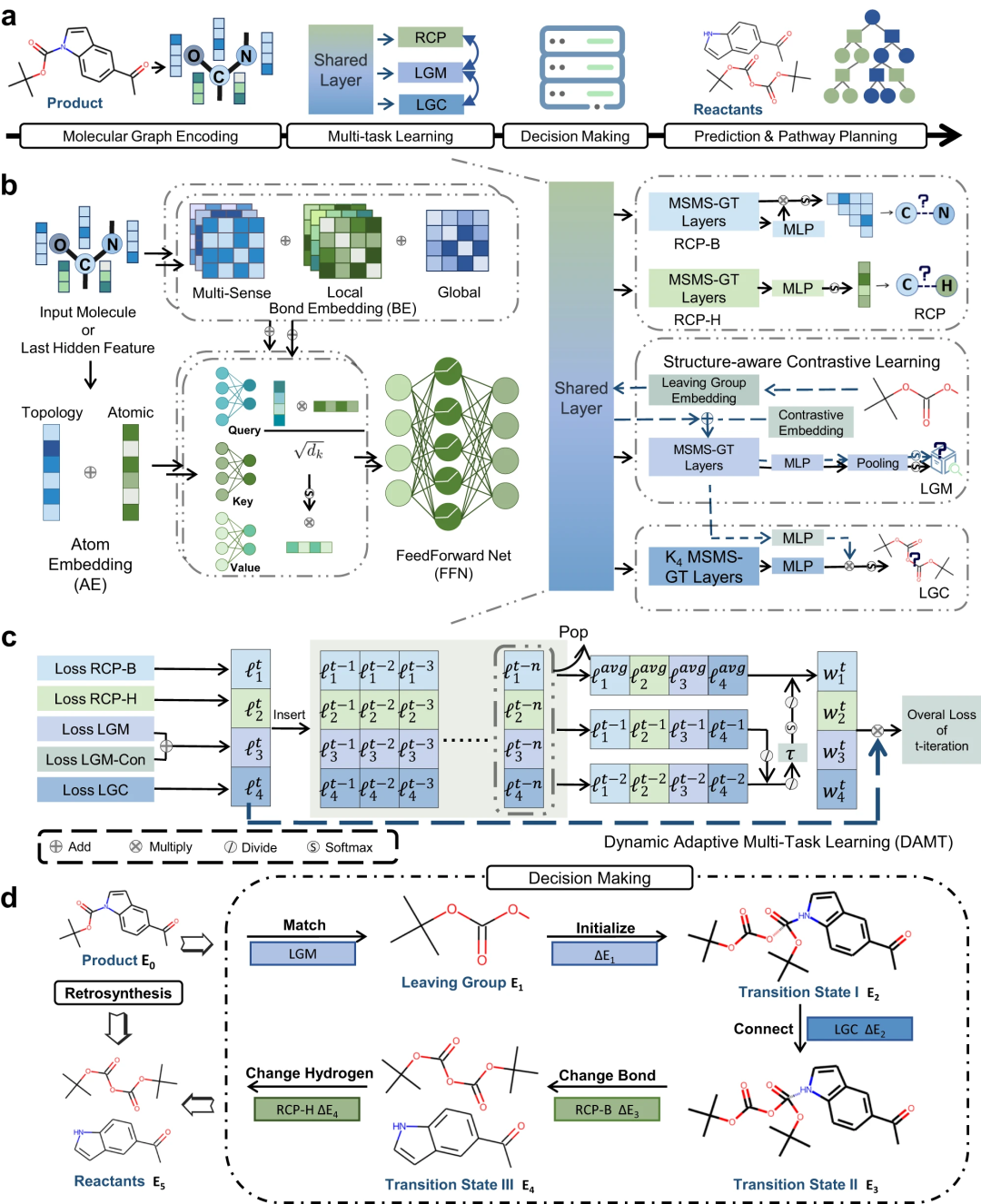
图 1:RetroExplainer 概述。(来源:论文)
稳健性
为了获得稳健且信息丰富的分子表示,提出了用于广义分子表示学习的多含义多尺度图 Transformer(MSMS-GT)、用于平衡多目标优化的动态自适应多任务学习(DAMT)以及用于分子结构信息捕获的结构感知对比学习(SACL)。结果表明,RetroExplainer 在几乎所有 12 个大型基准数据集上都表现出色,包括三个常用数据集(USPTO-50K、USPTO-FULL 和 USPTO-MIT),以及使用分子相似性分割方法新建的 9 个数据集。
为了简化比较,仅选择现有方法中表现最好的前 2 个方法(R-SMILES 和 LocalRetro)作为对照。从图 2 中可以看出,RetroExplainer 在 9 个数据集的大部分上都优于基准控制的 top-1、-3、-5 和 -10 精度。这进一步证明了RetroExplainer 的有效性和稳健性。此外,结果还表明,与现有方法相比,RetroExplainer 模型对带有支架的看不见的分子具有更强的域适应性。
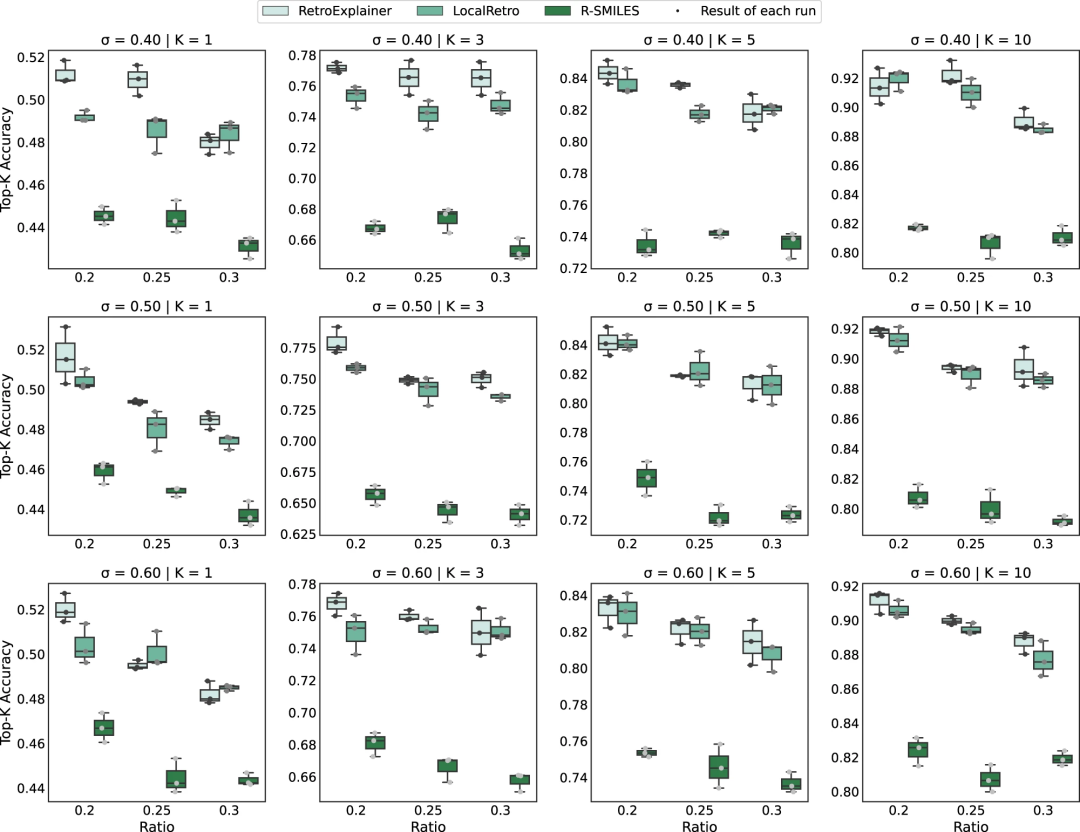
图 2:USPTO-50K 数据集与 Tanimoto 相似性分割的性能比较。(来源:论文)可解释性
为了获得良好的可解释性,引入了基于能量的分子组装过程,该过程提供透明的决策和可解释的逆合成预测。这个过程可以生成一条能量决策曲线,将预测分解为多个阶段,并允许子结构级别的归因;前者可以帮助理解「反事实」预测,以发现数据集中的潜在偏差,后者可以提供更细粒度的参考(例如某种化学键被破坏的置信度),以启发研究人员设计定制的反应物。
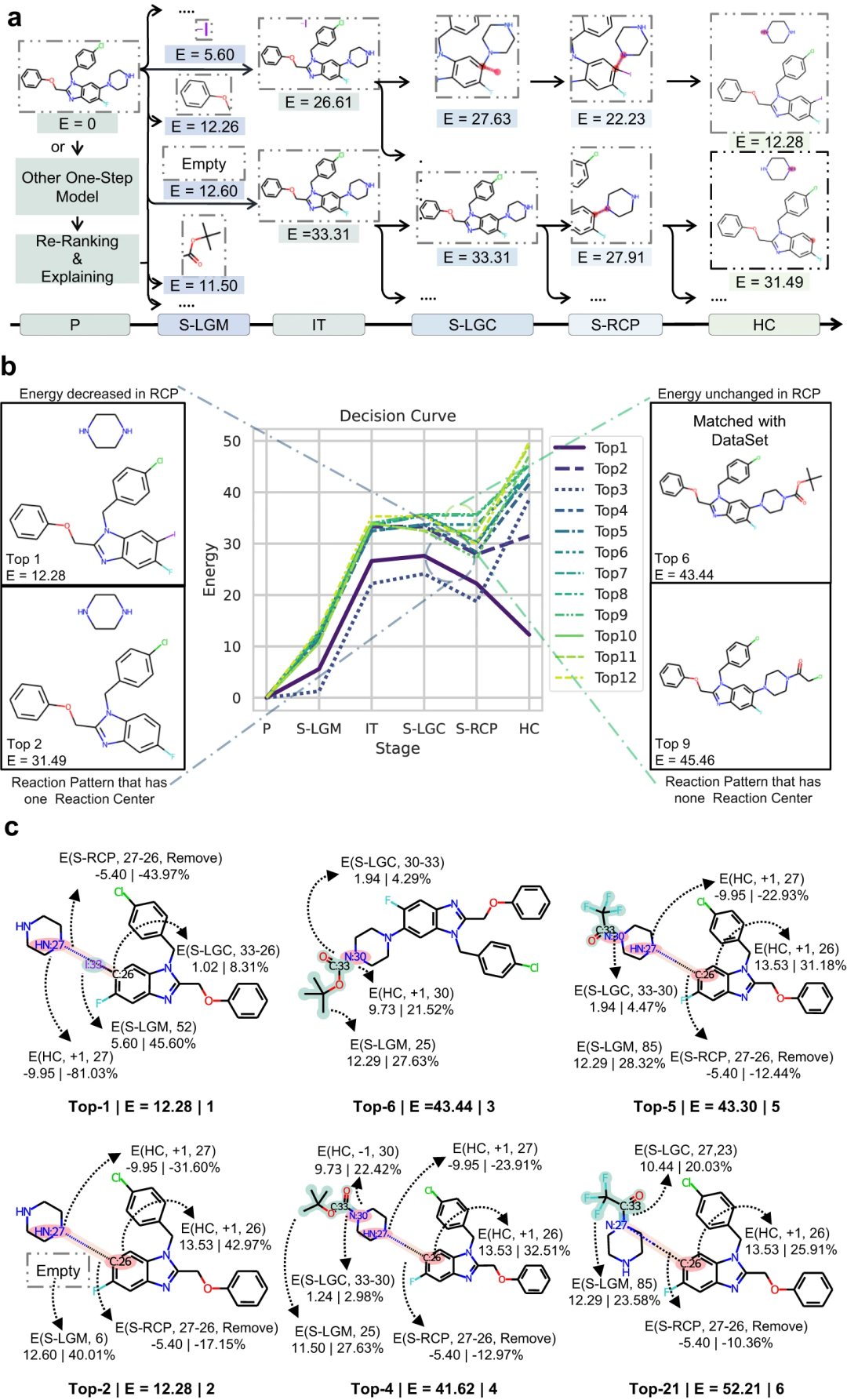
图 3:通过基于分子组装的决策过程生成解释。(来源:论文)研究人员还设计实验证明了 RetroExplainer 重排序能力。具体做法,将现有逆合成模型预测的前 50 组反应物,使用 RetroExplainer 评估这些预测结果的能量值。结果表明现有方法的预测结果经过重排序的预测准确率有了显著提高。
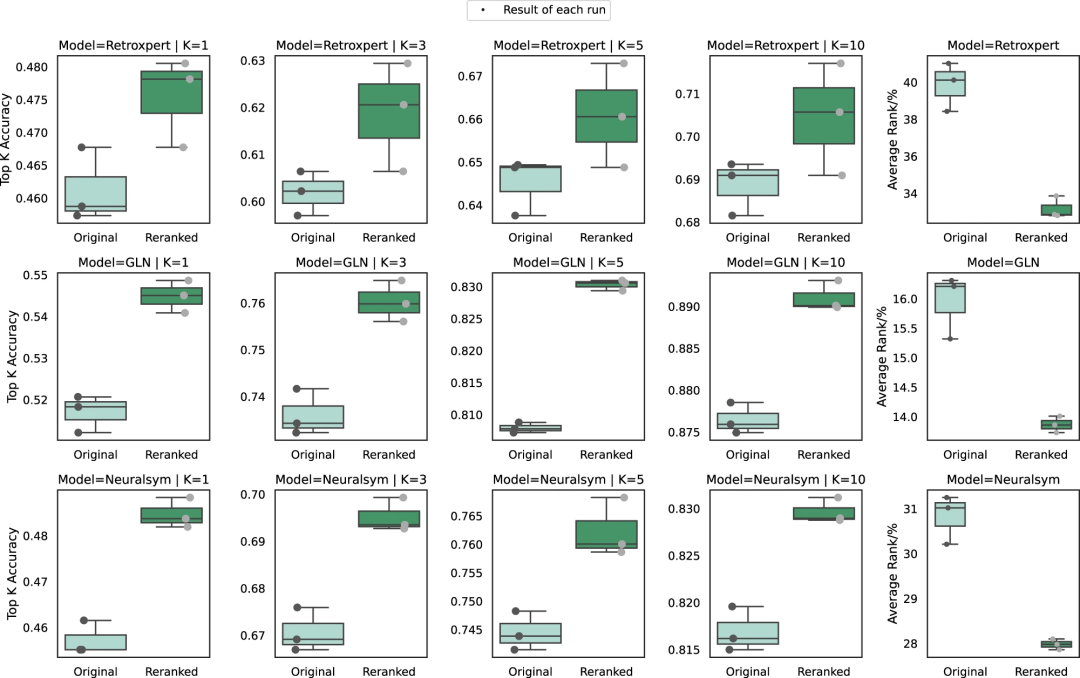
图 4:RetroExplainer 的重排序性能。(来源:论文)
实用性
为了提高 RetroExplainer 在路径规划方面的实用性,确保产品的可合成性并避免繁琐的手动选择候选反应物,研究人员将所提出的模型与 Retro* 算法相结合,具体来说,Retro* 的单步模型被 RetroExplainer 取代。
为了说明 RetroExplainer 的解释,以 protokylol(一种 β-肾上腺素能受体激动剂,用作支气管扩张剂)为例。RetroExplainer 设计了设计了一个四步合成 protokylol 的路线。决策过程的能量得分说明了支持 RetroExplainer 做出相应预测的关键子过程。
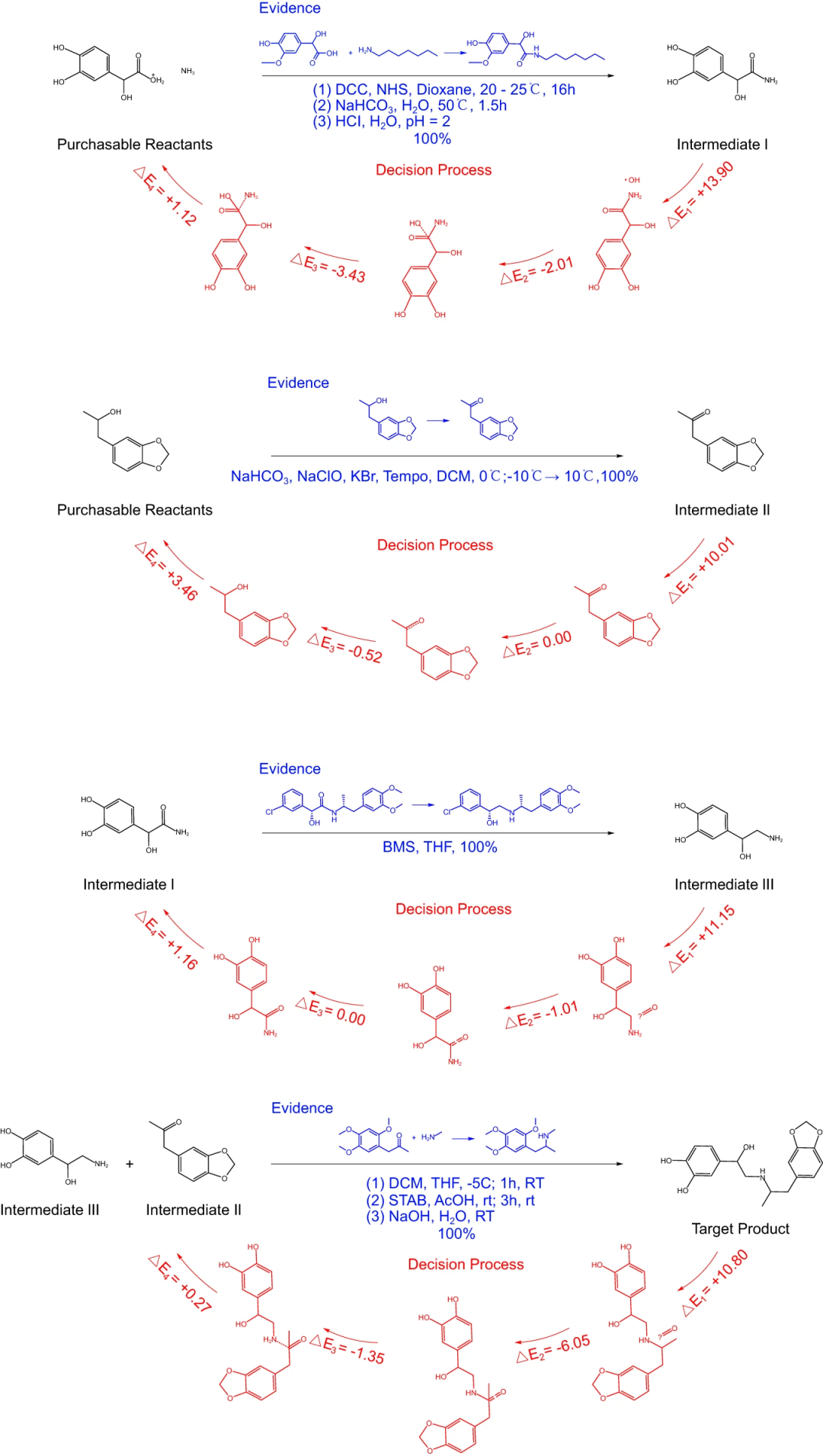
图 5:利用 RetroExplainer 对 protokylol 进行了逆合成规划。(来源:论文)为了进一步证明提出的方案的实用性,研究人员进行了文献检索以寻找每个反应步骤的证据。尽管许多提议的反应未能被发现,但能够找到与提议的反应相匹配的高产率的类似反应。此外,研究还提供了 101 个包含 176 个单步的路径规划案例,其中 153个单步预测可通过 SciFindern 引擎搜索找到,并具有类似的反应模式。
局限性
尽管 RetroExplainer 实现了令人印象深刻的性能和可解释性,但该方法存在一些局限性,值得未来进一步研究。
- 预测稀有离去基团的性能有限。几种深度学习技术,例如 LGM 预训练、元学习、主动学习和数据增强,可能有望引入深度逆合成学习,以提高针对罕见离去基团预测的稳健性。
- 决策过程的灵活性有限。可以引入许多其他反应机制,可以灵活参考来设计决策过程。此外,建议添加一个由LGM 和 RCP 的置信度确定的机制选择模块,以决定哪种类型的机制适合产生更容易人类理解的解释。
- 无法产生细粒度的预测。与大多数数据驱动的逆合成模型一样,由于相应 DL 模型的研究空白和缺乏公共数据集,RetroExplainer 无法预测更详细的反应信息,这已经成为自动化合成平台发展面临的越来越紧迫的挑战。这是其未来研究要探讨的问题。
论文链接:https://www.nature.com/articles/s41467-023-41698-5
人工智能 × [ 生物 神经科学 数学 物理 化学 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展
。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。








