计算机视觉研究院专栏
作者:Edison_G
目标检测是计算机视觉系统中的一项关键任务,在自动驾驶、医学成像、零售、安全、人脸识别、机器人技术等领域都有广泛的应用。目前,基于神经网络的模型被用于对特定类目标的实例进行定位和分类。

1、动机&摘要
当不需要实时推理时,模型的整合就有助于获得更好的结果。在这项工作中,研究者提出了一种新的方法来结合目标检测模型的预测:加权边界框融合。新提出的算法利用所有提出的边界框的置信度分数来构造平均的边界框。
2、背景
目标检测是一种计算机视觉技术,它处理图像和视频中特定类别的语义目标的实例。检测是一系列实际应用的基本任务,包括自主驾驶、医学成像、机器人、安全等。该任务将定位与分类相结合。目标检测模型通常会返回目标的候选位置、类标签和置信度分数。使用非极大抑制(NMS)方法选择预测框。首先,它会根据它们的置信度分数对所有的检测框进行分类。然后,选择具有最大置信值的检测框。同时,所有其他有明显重叠的检测框都会被过滤掉。它依赖于一个硬编码的阈值来丢弃冗余的边界框。最近的一些工作使用了一个可微分的模型来学习NMS,并引入了soft-NMS来提高过滤性能。
3、相关工作

回顾下NMS和Soft-NMS
经典NMS最初第一次应用到目标检测中是在RCNN算法中,其实现严格按照搜索局部极大值,抑制非极大值元素的思想来实现的,具体的实现步骤如下:- 选取置信度最高的框A添加到输出列表,并将其从候选框列表中删除
- 计算A与候选框列表中的所有框的IoU值,删除大于阈值的候选框
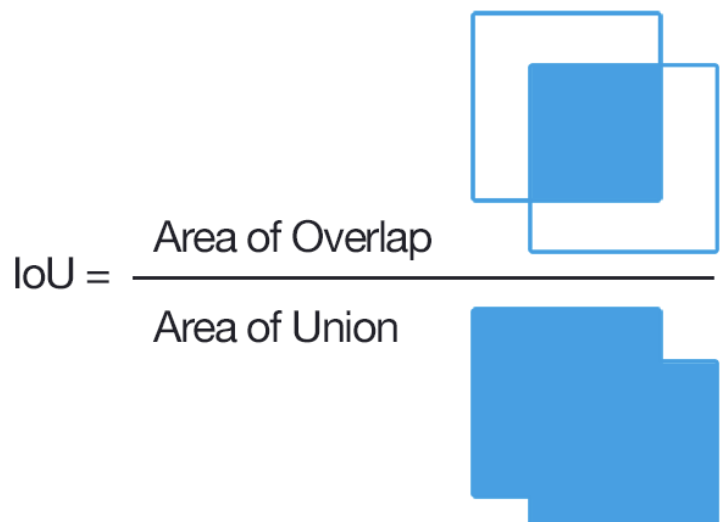
其中IoU(Intersection over Union)为交并比,如上图所示,IoU相当于两个区域交叉的部分除以两个区域的并集部分得出的结果。下图是IoU为各个取值时的情况展示,一般来说,这个score > 0.5 就可以被认为一个不错的结果了。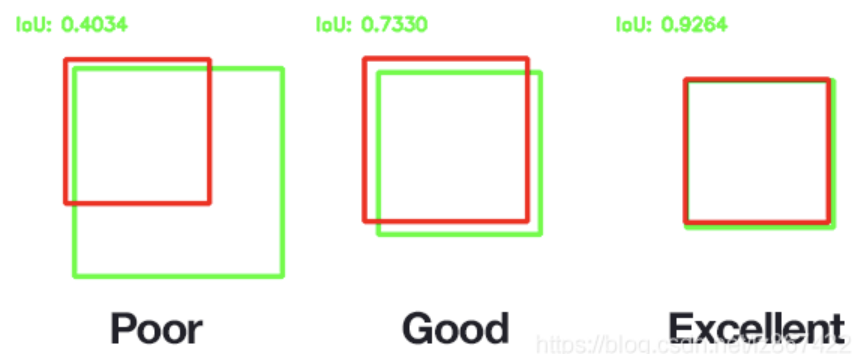
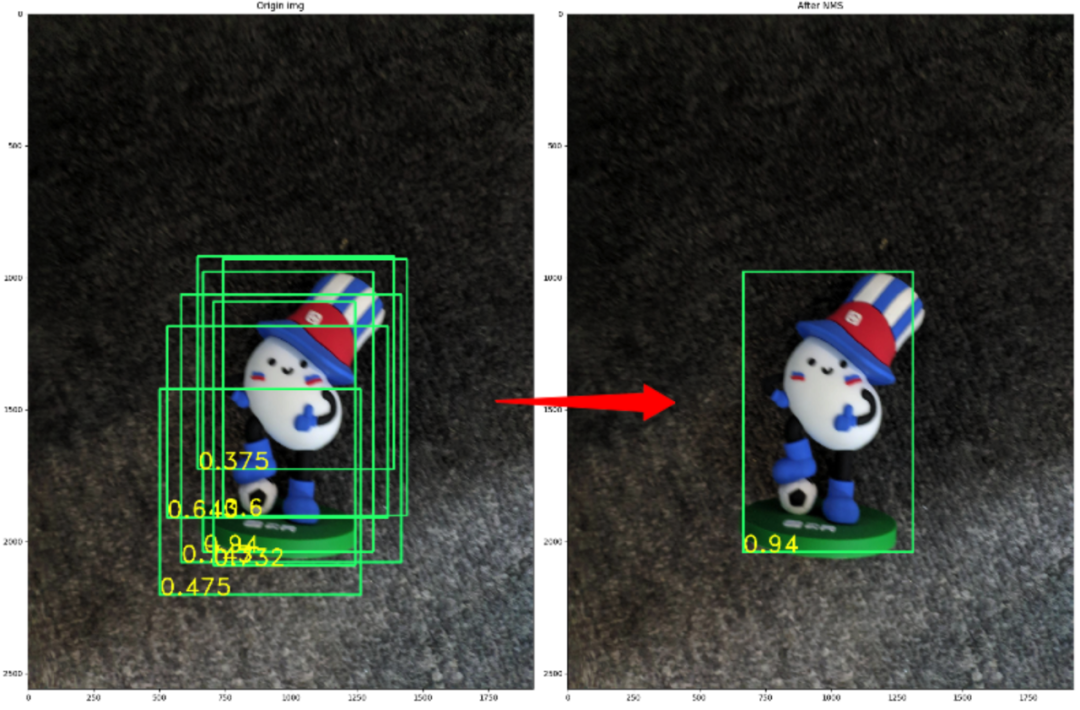
下面,通过一个具体例子来说明经典NMS究竟做了什么。下图的左图是包含一个检测目标(王闹海)的实例图片。其中的绿色矩形框代表了经过目标检测算法后,生成的大量的带置信度的Bounding box,矩形框左下角的浮点数即代表该Bounding box的置信度。在这里,使用Python对经典NMS算法实现,并应用到该实例中去。当NMS的阈值设为0.2时,最后的效果如下图中右图所示。
def nms(bounding_boxes, Nt): if len(bounding_boxes) == 0: return [], [] bboxes = np.array(bounding_boxes)
# 计算 n 个候选框的面积大小 x1 = bboxes[:, 0] y1 = bboxes[:, 1] x2 = bboxes[:, 2] y2 = bboxes[:, 3] scores = bboxes[:, 4] areas = (x2 - x1 + 1) * (y2 - y1 + 1)
# 对置信度进行排序, 获取排序后的下标序号, argsort 默认从小到大排序 order = np.argsort(scores)
picked_boxes = [] # 返回值 while order.size > 0: # 将当前置信度最大的框加入返回值列表中 index = order[-1] picked_boxes.append(bounding_boxes[index])
# 获取当前置信度最大的候选框与其他任意候选框的相交面积 x11 = np.maximum(x1[index], x1[order[:-1]]) y11 = np.maximum(y1[index], y1[order[:-1]]) x22 = np.minimum(x2[index], x2[order[:-1]]) y22 = np.minimum(y2[index], y2[order[:-1]]) w = np.maximum(0.0, x22 - x11 + 1) h = np.maximum(0.0, y22 - y11 + 1) intersection = w * h
# 利用相交的面积和两个框自身的面积计算框的交并比, 将交并比大于阈值的框删除 ious = intersection / (areas[index] + areas[order[:-1]] - intersection) left = np.where(ious < Nt) order = order[left] return picked_boxes
soft-NMS
经典NMS是为了去除重复的预测框,这种算法在图片中只有单个物体被检测的情况下具有很好的效果。然而,经典NMS算法存在着一些问题:对于重叠物体无法很好的检测。当图像中存在两个重叠度很高的物体时,经典NMS会过滤掉其中置信度较低的一个。如下图所示,经典NMS过滤后的结果如下下图所示:

而我们期望的结果是两个目标都被算法成功检测出来。
为了解决这类问题,Jan Hosang,等人提出了Soft-NMS算法。Soft-NMS的算法伪代码如图5所示。其中红色框为经典NMS的步骤,而绿色框中的内容为Soft-NMS改进的步骤。可以看出,相对于经典NMS算法,Soft-NMS仅仅修改了一行代码。当选取了最大置信度的Bounding box之后,计算其余每个Bounding box与Bounding box的I ou值,经典NMS算法的做法是直接删除Iou大于阈值的Bounding box;而Soft-NMS则是使用一个基于Iou的衰减函数,降低Iou大于阈值Nt的Bounding box的置信度,IoU越大,衰减程度越大。
def soft_nms(bboxes, Nt=0.3, sigma2=0.5, score_thresh=0.3, method=2): # 在 bboxes 之后添加对于的下标[0, 1, 2...], 最终 bboxes 的 shape 为 [n, 5], 前四个为坐标, 后一个为下标 res_bboxes = deepcopy(bboxes) N = bboxes.shape[0] # 总的 box 的数量 indexes = np.array([np.arange(N)]) # 下标: 0, 1, 2, ..., n-1 bboxes = np.concatenate((bboxes, indexes.T), axis=1) # concatenate 之后, bboxes 的操作不会对外部变量产生影响 # 计算每个 box 的面积 x1 = bboxes[:, 0] y1 = bboxes[:, 1] x2 = bboxes[:, 2] y2 = bboxes[:, 3] scores = bboxes[:, 4] areas = (x2 - x1 + 1) * (y2 - y1 + 1)
for i in range(N): # 找出 i 后面的最大 score 及其下标 pos = i + 1 if i != N - 1: maxscore = np.max(scores[pos:], axis=0) maxpos = np.argmax(scores[pos:], axis=0) else: maxscore = scores[-1] maxpos = 0 # 如果当前 i 的得分小于后面的最大 score, 则与之交换, 确保 i 上的 score 最大 if scores[i] < maxscore: bboxes[[i, maxpos + i + 1]] = bboxes[[maxpos + i + 1, i]] scores[[i, maxpos + i + 1]] = scores[[maxpos + i + 1, i]] areas[[i, maxpos + i + 1]] = areas[[maxpos + i + 1, i]] # IoU calculate
xx1 = np.maximum(bboxes[i, 0], bboxes[pos:, 0]) yy1 = np.maximum(bboxes[i, 1], bboxes[pos:, 1]) xx2 = np.minimum(bboxes[i, 2], bboxes[pos:, 2]) yy2 = np.minimum(bboxes[i, 3], bboxes[pos:, 3]) w = np.maximum(0.0, xx2 - xx1 + 1) h = np.maximum(0.0, yy2 - yy1 + 1) intersection = w * h iou = intersection / (areas[i] + areas[pos:] - intersection) # Three methods: 1.linear 2.gaussian 3.original NMS if method == 1: # linear weight = np.ones(iou.shape) weight[iou > Nt] = weight[iou > Nt] - iou[iou > Nt] elif method == 2: # gaussian weight = np.exp(-(iou * iou) / sigma2) else: # original NMS weight = np.ones(iou.shape) weight[iou > Nt] = 0 scores[pos:] = weight * scores[pos:] # select the boxes and keep the corresponding indexes inds = bboxes[:, 5][scores > score_thresh] keep = inds.astype(int) return res_bboxes[keep]

后期我们详细给大家说说NMS一系列知识!
4、Weighted Boxes Fusion
在这里,我们描述了新的边界框融合方法:加权边界框融合(WBF)。假设,我们已经绑定了来自N个不同模型的相同图像的框预测。或者,我们对相同图像的原始和增强版本(即垂直/水平反射,数据增强)有相同模型的N个预测)。WBF工作如下步骤:


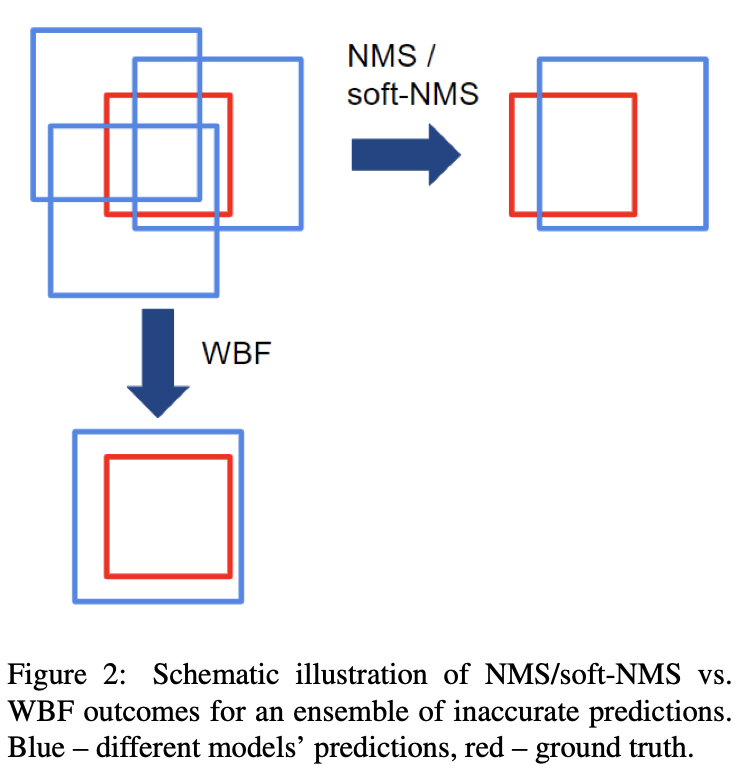
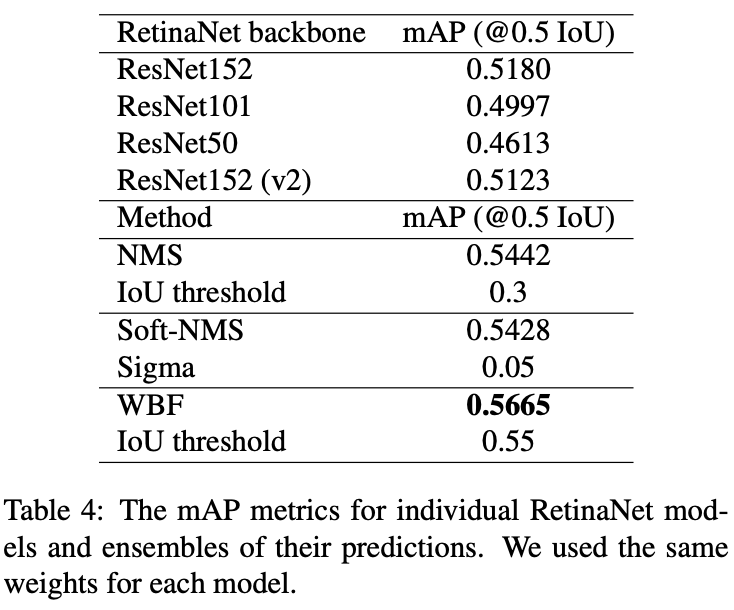
NMS和Soft-NMS都排除了一些框,而WBF则使用了所有框。因此,它可以修复所有模型都预测不准确的情况。本案例如下图所示。NMS/Soft-NMS将只留下一个不准确的框,而WBF将使用所有预测的框来融合它。
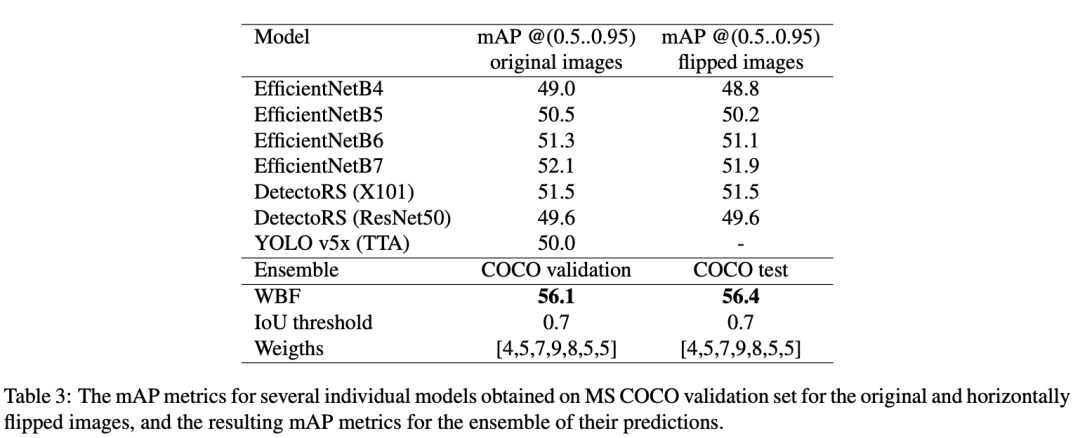
5、实验结果
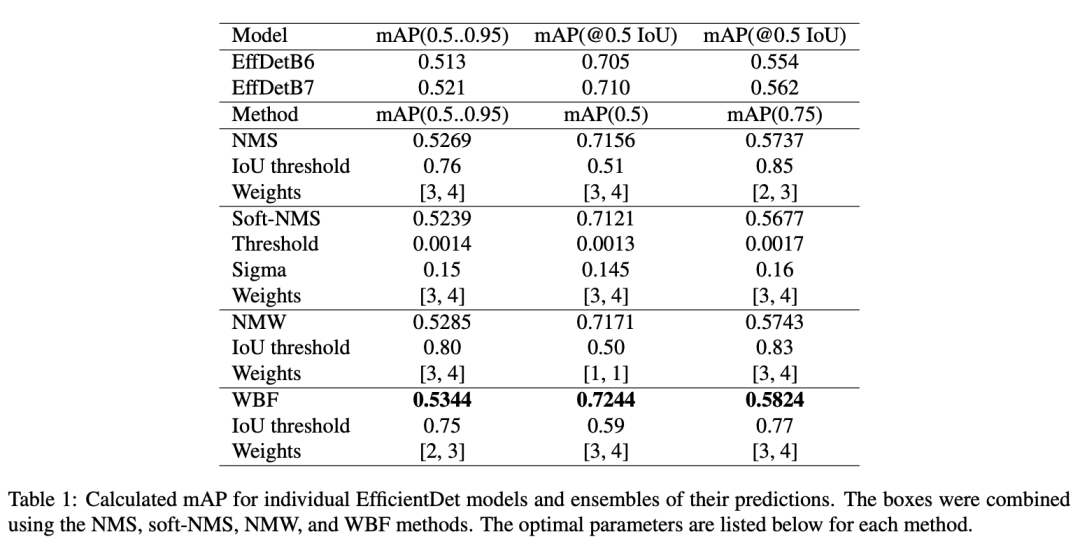
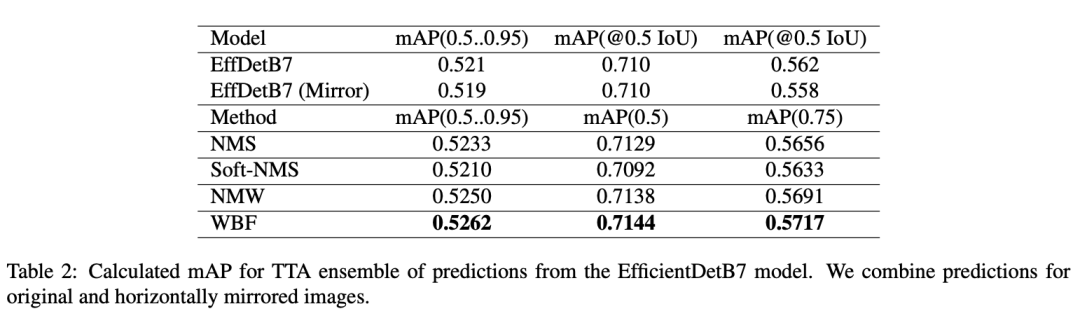
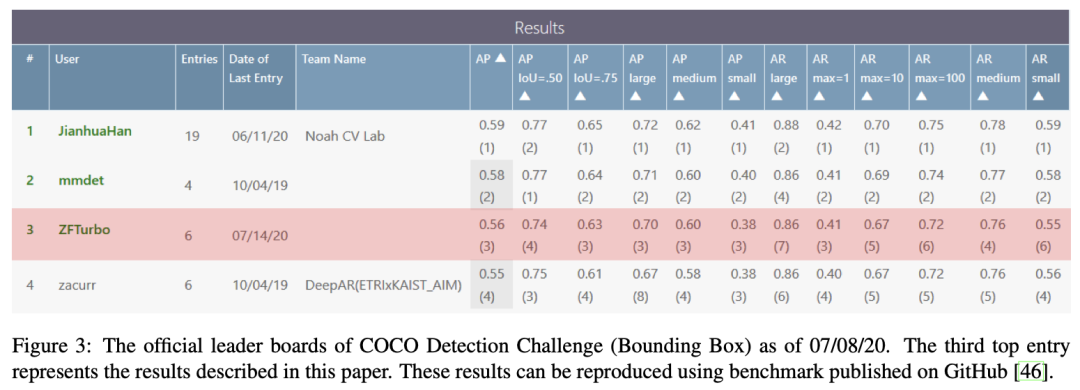
[46]: ZFTurbo. Coco wbf benchmark. https://github.
com/ZFTurbo/Weighted-Boxes-Fusion/tree/master/benchmark, 2020.
转载请联系本公众号获得授权
计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!









