将 ScienceAI 设为星标
第一时间掌握
新鲜的 AI for Science 资讯

编辑 | 白菜叶
像 Llama 2 和 ChatGPT 这样的大型语言模型现在非常流行。但当今数据中心级计算机的执行效果如何?答案是很好,根据机器学习的最新一组基准结果,最好的人能够在一秒钟内总结 100 多篇文章。MLPerf 每年两次的数据交付于 9 月 11 日发布,其中首次包含大型语言模型(LLM)GPT-J 的测试。
15 家计算机公司在首次 LLM 审判中提交了绩效结果,加上总共 26 家公司提交的 13,000 多项其他结果。作为数据中心类别的亮点之一,Nvidia 公布了其 Grace Hopper 的第一个基准测试结果——H100 GPU 与该公司的新型 Grace CPU 连接在同一封装中,就好像它们是单个「超级芯片」一样。
MLPerf 有时被称为「机器学习的奥林匹克」,由七个基准测试组成:图像识别、医学成像分割、对象检测、语音识别、自然语言处理、新的推荐系统,以及现在的 LLM。这组基准测试了已训练的神经网络在不同计算机系统上的执行情况,这一过程称为推理。
LLM(称为 GPT-J)于 2021 年发布,对于此类人工智能来说偏小。它由大约 60 亿个参数组成,而 GPT-3 有 1750 亿个参数。但 MLCommons 执行董事 David Kanter 表示,规模较小是有意而为之的,因为该组织希望计算行业的大部分人都能实现这一基准。它也符合更紧凑但仍然有能力的神经网络的趋势。
这是推理竞赛的 3.1 版本,与之前的迭代一样,Nvidia 在使用其芯片的机器数量和性能方面都占据主导地位。然而,Intel 的 Habana Gaudi2 继续紧追 Nvidia H100, Qualcomm 的 Cloud AI 100 芯片在功耗基准测试中表现强劲。
Nvidia仍处于领先地位
这组基准见证了 Grace Hopper 超级芯片的到来,这是一款基于 Arm 的 72 核 CPU,通过 Nvidia 专有的 C2C 链路与 H100 融合。大多数其他 H100 系统依赖于单独封装中的 Intel Xeon 或 AMD Epyc CPU。
与 Grace Hopper 最接近的同类系统是 Nvidia DGX H100 计算机,它结合了两个 Intel Xeon CPU 和一个 H100 GPU。Grace Hopper 机器在每个类别中都比该机器高出 2% 到 14%,具体取决于基准。最大的差异是在推荐系统测试中实现的,最小的差异是在 LLM 测试中实现的。
Nvidia 人工智能推理、基准测试和云总监 Dave Salvatore 将 Grace Hopper 的优势很大程度上归功于内存访问。通过将 Grace 芯片与 Hopper 芯片绑定的专有 C2C 链路,GPU 可以直接访问 480GB 的 CPU 内存,并且 Grace 芯片本身还附加了 16GB 的高带宽内存。(Salvatore 表示,下一代 Grace Hopper 将增加更多内存容量,从目前的 96 GB 增至 140 GB。)当 CPU 不太繁忙时,组合芯片还可以为 GPU 提供额外的功率,从而使 GPU 能够提高其性能。
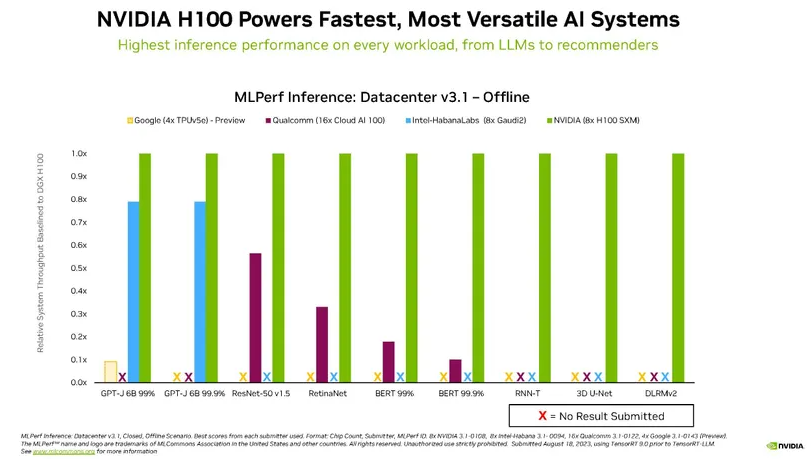
除了 Grace Hopper 的到来之外,Nvidia 也一如既往地表现出色,你可以在下面的图表中看到数据中心级计算机的所有推理性能结果。
MLPerf 数据中心推理 v3.1 结果
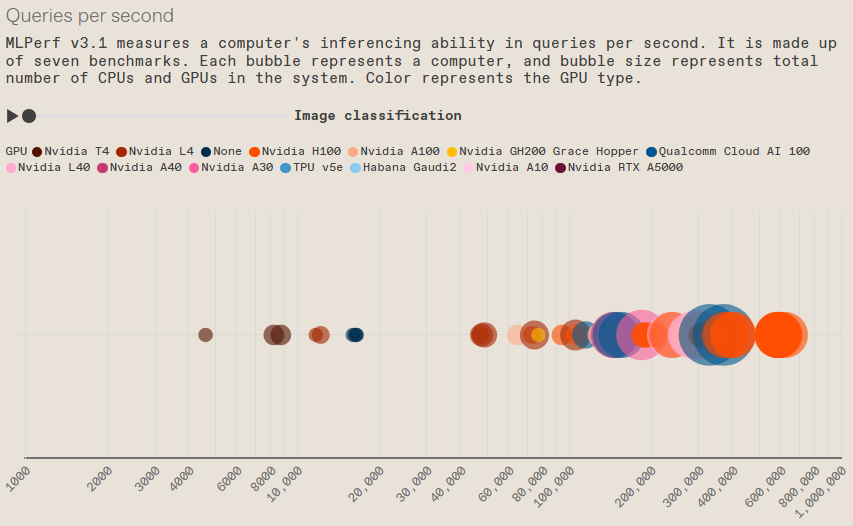
对于 GPU 巨头来说,情况可能会变得更好。Nvidia 发布了一个新的软件库,可以有效地将 H100 在 GPT-J 上的性能提高一倍。它名为 TensorRT-LLM,尚未及时准备好进行 MLPerf v3.1 测试,该测试已于 8 月初提交。Salvatore 表示,关键的创新是所谓的「飞行批处理」。执行 LLM 所涉及的工作可能有很大差异。例如,可以要求同一个神经网络将一篇 20 页的文章变成一篇一页的文章,或者用 100 个单词总结一篇一页的文章。TensorRT-LLM 基本上可以防止这些查询相互拖延,因此在大型作业正在进行时也可以完成小型查询。
Intel Closes In
Intel的 Habana Gaudi2 加速器在前几轮基准测试中一直紧追 H100。这次,Intel仅测试了一台 2 个 CPU、8 个加速器的计算机,并且仅在 LLM 基准测试上进行了测试。在这项任务中,该系统落后 Nvidia 最快的机器 8% 到 22%。
Intel人工智能产品高级总监 Jordan Plawner 表示:「在推理方面,我们几乎与 H100 持平。」 他说,客户逐渐将 Habana 芯片视为「H100 的唯一可行替代品」,而 H100 的需求量非常大。
他还指出,Gaudi2在芯片制造技术方面落后H100一代。他说,下一代将使用与 H100 相同的芯片技术。
Intel历史上也曾使用 MLPerf 来展示单独使用 CPU 可以完成多少工作,尽管 CPU 现在配备了专用的矩阵计算单元来帮助神经网络。这一轮也不例外。六个包含两个 Intel Xeon CPU 的系统均在 LLM 基准测试中进行了测试。虽然它们的性能远未达到 GPU 标准(Grace Hopper 系统的速度通常是它们的 10 倍甚至更快),但它们仍然可以每秒左右输出一个摘要。
数据中心效率结果
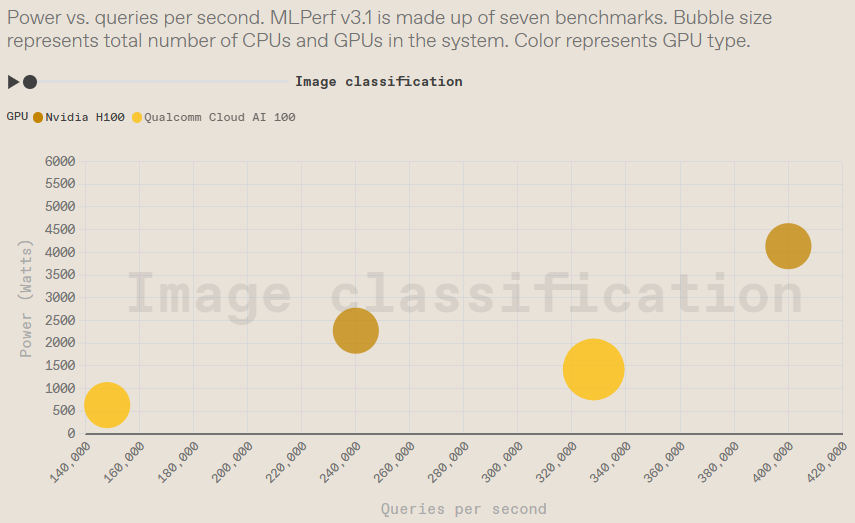
该类别仅测量了 Qualcomm和 Nvidia 芯片。Qualcomm此前曾强调其加速器的功效,但 Nvidia H100 机器也表现出色。
相关报道:https://spectrum.ieee.org/mlperf
人工智能 × [ 生物 神经科学 数学 物理 化学 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。










