
前言
非线性的机器学习模型确实能够捕捉股票特征和未来回报之间复杂关系。然而,相关文献主要侧重预测收益,而忽略了相关交易成本。在基于美股的数据测试后,我们发现这类模型表现较好的区间集中在2004年之前。2004年之后的表现大幅下滑。
在本文中,我们首先证明了有效的投资组合构建规则能够使机器学习模型在2004年后的表现有明显提升。然后,我们展示了2004年后基于更长周期的预测的机器学习策略能够带来更好的表现。
本文主要的发现有:
- 我们发现机器学习模型的多空收益非常明显。但随着预测周期的增加,模型表现很换手同时降低,但换手降低的更明显。所以考虑交易成本后,长周期的预测模型更优。
- 在短周期预测模型中,高换手的短期因子占主导;而在长周期预测模型中,低换手的基本面(如质量和价值)占主导;
- 考虑交易成本后,我们发现长周期模型与短周期的Alpha是正交的。而且在2004之后,长周期模型表现更优。
数据和模型
- 去除微盘股的所有美股上市公司1957年至2021年的数据(以2004年分成前后两段),平均每月2651个股票;
- 因子:Chen和Zimmermann的开源因子库(OSAP)中206个因子;
- 测试方法:每个月末更具模型未来的预测对所有股票进行排序,并分为十组,每组市值加权。
有启发的测试结果
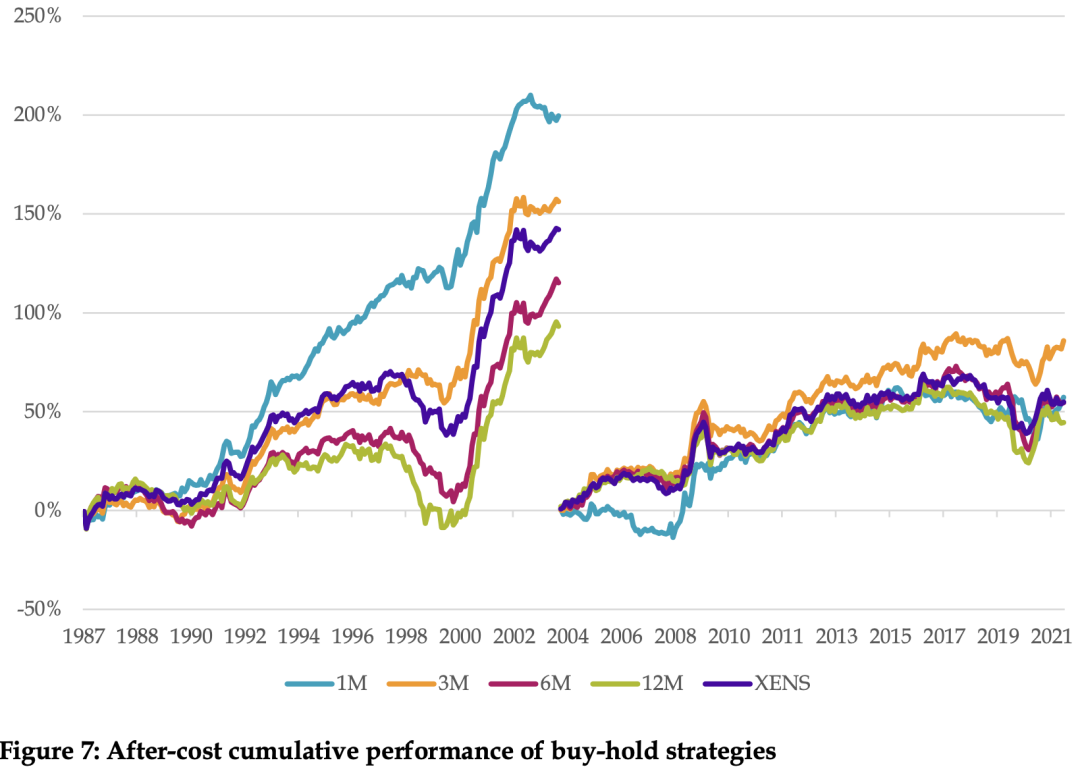
1、整体而言模型越复杂,表现越好;复合模型表现最好。(费前)预测周期越长,策略表现越差。在互联网泡沫破裂和全球金融危机期间,这些策略都表现强劲,在2018年至2020年所谓的“量化危机”期间,特别是价值投资挣扎普遍存在弱点。其次,在样本的后半段,性能显著减弱。在2004年后的这段时间里,1M策略与其他周期的差异显著减小。(费后)1M相对其他周期的优势不再那么明显,而且2004年之后甚至表现垫底。


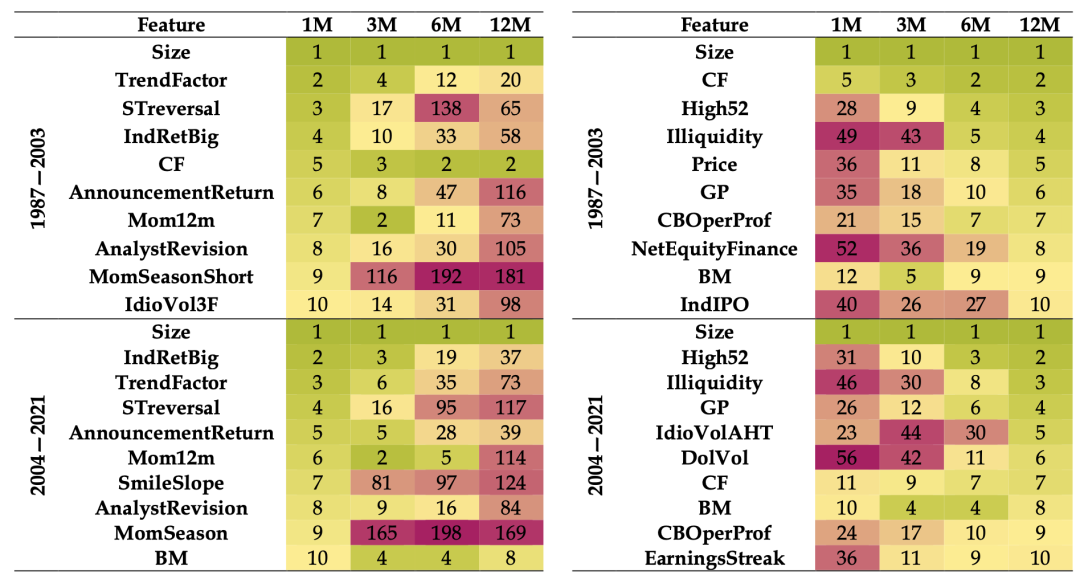
2、下图左边包含了1M预测期排名前10重要的因子,以及这些因子在其他预测周期的重要性;下图右边包含了12M预测期排名前10重要的因子,以及这些因子在其他预测周期的重要性。在较短的预测期,重要的因子主要是短期因子,如短期反转(STreversal),趋势(TrendFactor)和行业势头(IndRetBig)是重要的。
在12M预测期里,与价值(BM、CF和NetEquityFinance)、盈利能力(GP和CBOperProf)和动量(High52)相关的更传统的因子占主导地位。在所有四个预测范围内,我们发现Size特征是最重要的。在某种程度上,这是由样本早期规模因子的强劲表现驱动的,导致模型将规模确定为回报的强大预测因子这也部分解释了2004年后模型表现较弱的原因,当时规模因子的表现衰减严重。
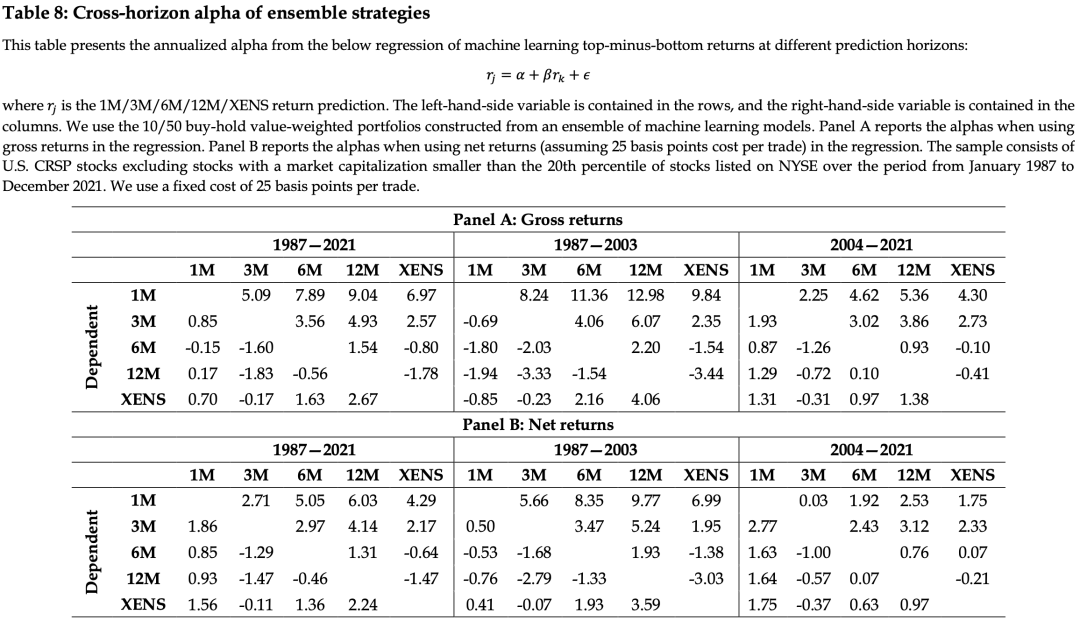
3、对1M、3M、6M、12M、XENS的多空收益两两配对做回归,表格中的数字是回归的截距,也就是未被自变量解释的部分。Panel A用的费前收益,Panel B用的费后收益。无论从Panel A还是B,都可以看出,短周期的收益大部分不能被中长周期的收益解释,而中长周期的能被短周期解释。但是相对费前,费后中长周期无法被短周期解释的部分更大,说明经过长期预测训练的机器学习模型能够释放额外的净Alpha。
参考文献
1、CHEN, A.Y., and ZIMMERMANN, T., 2022. “Open Source Cross-Sectional Asset Pricing.” Critical Finance Review 11 (2): 207–264.
2、Blitz, David and Hanauer, Matthias Xaver and Hoogteijling, Tobias and Howard, Clint, The Term Structure of Machine Learning Alpha (June 12, 2023).
作者:David Blitz、Matthias X. Hanauer、Tobias Hoogteijling、Clint Howard
标题:The Term Structure of Machine Learning Alpha
🏴☠️宝藏级🏴☠️ 原创公众号『数据STUDIO』内容超级硬核。公众号以Python为核心语言,垂直于数据科学领域,包括可戳👉 Python|MySQL|数据分析|数据可视化|机器学习与数据挖掘|爬虫 等,从入门到进阶!
长按👇关注- 数据STUDIO -设为星标,干货速递









