 夕小瑶科技说 分享
夕小瑶科技说 分享
来源 | 新智元
代码能否跑起来的不是判断可靠性的标准,用语言模型写代码还需要考虑生产环境下的预期外输入。
大型语言模型(LLM)在理解自然语言和生成程序代码方面展现出了非凡的性能,程序员们也开始在编码过程中使用Copilot工具辅助编程,或是要求LLM生成解决方案。
经过几版迭代后,目前LLM生成的代码已经很少有语法错误了,也更贴合用户输入的文本、符合预期语义,但针对LLM代码生成的可靠性和鲁棒性仍然缺乏彻底的研究。
代码的可执行并不等同于可靠,软件的开发环境、部署环境都存在很大的不确定性。

如果直接使用LLM生成的代码,可能会因为AP误用(misuse)导致更严重的问题,例如资源泄漏、程序崩溃;最糟糕的是,使用LLM代码生成服务的用户大多数都是新手开发人员,很难识别出「貌似可运行代码」下的隐藏问题,进一步增加了漏洞代码在现实中的应用风险。
现有的代码评估基准和数据集主要专注于小任务,例如面试中的编程问题,可能不符合开发人员在工作中的实际需求。
最近,来自加州大学的两位华人研究人员发布了一个用于评估生成代码可靠性和鲁棒性的新数据集RobustAPI,包括从StackOverflow中收集得到的1208个编码问题,涉及24个主流Java API的评估。

论文链接:
https://arxiv.org/pdf/2308.10335.pdf
研究人员总结了这些API的常见误用模式,并在当下常用的LLM上对其进行评估,结果表明,即使是GPT-4,也有高达62%的生成代码包含API误用问题,如果代码被实际部署,可能会导致意想不到的后果。
论文相关的数据和评估器不久后将开源。
方法
数据收集
为了利用软件工程领域现有的研究成果,RobustAPI没有从零构建,而是基于在线问答论坛中频繁出现的Java API误用数据集ExampleCheck

研究人员从数据集中选择了23个流行的Java APIs,涵盖了字符串处理、数据结构、移动开发、加密和数据库操作等。
然后再从Stack Overflow中爬取与上述API相关的问题,只选择问题中包含在线答案的,可以保证RobustAPI是可回答的(answerable),能够更有效地评估LLM在「人类容易犯错问题」上的代码能力。
收集数据后将问题转换为JSON格式,包含四个字段:
提示生成(prompt generation)
研究人员设计了一个提示模板,并用数据集中的样本进行填充,再从LLMs收集回复内容,并实现一个API使用检查器来评估代码的可靠性。

在少样本演示下进行实验时,每个示例都提供回复的格式,然后在最后放入数据集中的问题及相应API提示,模拟新手用户询问时提出的问题。
LLM在对话时可以识别特殊标签的结构,所以研究人员将问题和答案封装起来指示LLM生成问题的答案。
演示样本(Demonstration Samples)
为了深入分析LLMs的代码生成能力,研究人员设计了两个少样本实验:
- one-shot-irrelevant,使用不相关的API(如Arrays.stream)作为语言模型的提示样例。

研究人员假定该示例可以消除生成代码中的语法错误。
- one-shot-relevant,使用相同的API作为示例,包括一组问题和答案。
JAVA API误用
研究人员在使用API时,需要充分理解API的使用规则,以便实现理想的API效果。
一个典型的例子是文件操作,通过RandomAccessFile打开和写入文件时,需要注意两条使用规则:
如果在读取预期字节之前达到缓冲区限制,API将抛出IndexOutOfBoundsException异常;当该文件同时被其他进程关闭时,API将抛出ClosedChannelException。
为了处理这些异常,正确的实现应该将API包含在try-catch块中。
- 使用后应应该关闭文件通道,否则的话,如果此代码片段位于在多个实例中并发运行的长期程序中,文件资源可能会耗尽,代码需要在所有文件操作后调用close API

另一个容易被误用的API使用规则的例子是一个特殊的数据对象TypedArray,需要开发人员调用recycle()来手动启用垃圾收集,否则,即使不再使用此TypedArray,Java虚拟机中的垃圾收集也不会被触发。

在没有垃圾回收的情况下使用该API会导致未释放的内存消耗,在生产环境部署后,在大工作负载和高并发性下会降低甚至挂起软件系统。
在RobustAPI数据集中,研究人员总结了40个API使用规则,具体包括:
API的保护条件,在API调用之前应该检查,例如File.exists()应该在调用File.createNewFile()之前;
API的调用顺序,例如close()的调用应该在File.write()之后;
API的控制结构,例如SimpleDataFormat.parse()应该被try-catch结构所包围。
检测API误用
现有的评估LLMs生成的代码的研究通常使用人工编写或自动测试生成的测试用例,但即使是高覆盖率的测试用例也只能覆盖语义正确性,无法模拟生产环境中的各种意外输入,无法对代码的可靠性和健壮性进行完善的评估。
为了解决这个难题,研究人员使用静态分析的方法,在不运行测试用例的情况下,通过代码结构分析代码误用,可以保证对整个程序的全面覆盖,并且比测试解决方案的效率更高。
为了评估代码中API用法的正确性,先从代码片段中提取调用结果和控制结构,然后根据API使用规则检测API误用。
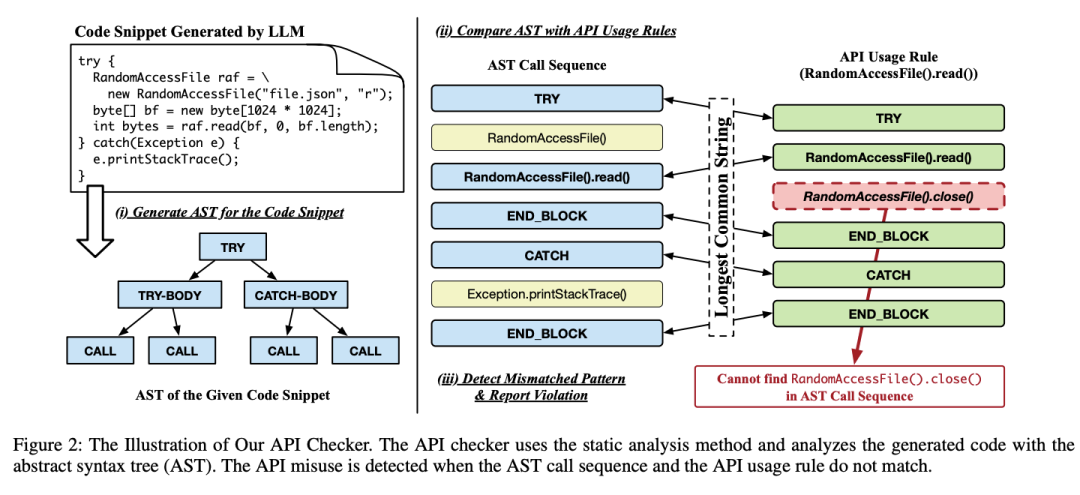
代码检查器(code checker)首先检查代码片段,判断是一个方法的片段还是一个类的方法,然后就可以对代码片段进行封装,并从代码片段中构造抽象语法树(AST)。
然后检查器遍历AST,按顺序记录所有的方法调用和控制结构,从而生成一个调用序列;检查器将调用序列与API使用规则进行比较,判断每个方法调用的实例类型,并使用类型和方法作为键来检索相应的API使用规则。
最后,检查器计算调用序列和API使用规则之间的最长公共序列:如果调用序列与预期的API使用规则不匹配,则报告API误用。
实验结果
研究人员使用4个语言模型(GPT-3.5,GPT-4,Llama-2,Vicuna-1.5)在RobustAPI上进行评估。
将可编译且包含API误用的答案除以所有可编译的答案后,计算得到各个语言模型的误用率。
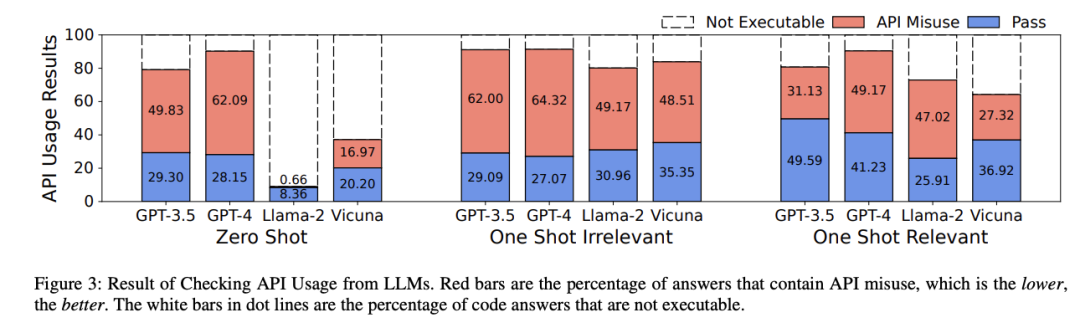
从实验结果上来看,即便是最先进的商业模型,如GPT-3.5和GPT-4也存在误用的问题。
在零样本设置下,Llama的API误用率最低,不过大多数Llama的答案中都不包含代码。
一个与直觉相反的发现是,虽然OpenAI官方宣称GPT-4比GPT-3.5在代码生成上的性能提升达到40%,但实际上GPT-4的代码误用率要更高。
这一结果也表明,代码在现实世界生产中的可靠性和健壮性没有得到业界的重视,并且该问题存在巨大的改进空间。














