近期,微软开源了一个可以在模型训练中加入完整RLHF流程的系统框架——DeepSpeed Chat。也就是说,各种规模的高质量类ChatGPT模型,现在都唾手可得了!
项目地址:https://github.com/microsoft/DeepSpeed
众所周知,由于OpenAI太不Open,开源社区为了让更多人能用上类ChatGPT模型,相继推出了LLaMa、Alpaca、Vicuna、Databricks-Dolly等模型。但由于缺乏一个支持端到端的RLHF规模化系统,目前类ChatGPT模型的训练仍然十分困难。而DeepSpeed Chat的出现,正好补全了这个「bug」。
更亮的是,DeepSpeed Chat把成本大大地打了下来。此前,昂贵的多GPU设置超出了许多研究者的能力范围,并且,即使能访问多GPU集群,现有的方法也无力负担数千亿参数ChatGPT模型的训练。现在,只要花1620美元,就可以通过混合引擎DeepSpeed-HE,在2.1天内训练一个OPT-66B模型。而如果使用多节点、多GPU系统,DeepSpeed-HE可以花320美元,在1.25小时内训练一个OPT-13B模型,花5120美元,就能在不到一天的时间内训练一个OPT-175B模型。前Meta AI专家Elvis激动转发,称这是一件大事,并表示好奇DeepSpeed Chat和ColossalChat相比起来如何。经过DeepSpeed-Chat的训练,13亿参数版「ChatGPT」在问答环节上的表现非常亮眼。不仅能get到问题的上下文关系,而且给出的答案也有模有样。在多轮对话中,这个13亿参数版「ChatGPT」所展示出的性能,也完全超越了这个规模的固有印象。git clone https://github.com/microsoft/DeepSpeed.gitcd DeepSpeedpip install .
git clone https://github.com/microsoft/DeepSpeedExamples.gitcd DeepSpeedExamples/applications/DeepSpeed-Chat/pip install -r requirements.txt
一杯咖啡,训完13亿参数版ChatGPT
如果你只有大约1-2小时的咖啡或午餐休息时间,也可以尝试使用DeepSpeed-Chat训练一个「小玩具」。团队特地准备了一个针对1.3B模型的训练示例,可在消费级GPU上进行测试。最棒的是,当你从午休回来时,一切都已准备就绪。python train.py --actor-model facebook/opt-1.3b --reward-model facebook/opt-350m --num-gpus 1
配备48GB显存的消费级NVIDIA A6000 GPU:一个GPU Node,半天搞定130亿参数
如果你只有半天的时间,以及一台服务器节点,则可以通过预训练的OPT-13B作为actor模型,OPT-350M作为reward模型,来生成一个130亿参数的类ChatGPT模型:python train.py --actor-model facebook/opt-13b --reward-model facebook/opt-350m --num-gpus 8
单DGX节点,搭载了8个NVIDIA A100-40G GPU:超省钱云方案,训练660亿参数模型
如果你可以使用多节点集群或云资源,并希望训练一个更大、更高质量的模型。那么只需基于下面这行代码,输入你想要的模型大小(如66B)和GPU数量(如64):python train.py --actor-model facebook/opt-66b --reward-model facebook/opt-350m --num-gpus 64
8个DGX节点,每个节点配备8个NVIDIA A100-80G GPU:具体来说,针对不同规模的模型和硬件配置,DeepSpeed-RLHF系统所需的时间和成本如下:
DeepSpeed Chat是一种通用系统框架,能够实现类似ChatGPT模型的端到端RLHF训练,从而帮助我们生成自己的高质量类ChatGPT模型。DeepSpeed Chat具有以下三大核心功能:
1. 简化ChatGPT类型模型的训练和强化推理体验
开发者只需一个脚本,就能实现多个训练步骤,并且在完成后还可以利用推理API进行对话式交互测试。
2. DeepSpeed-RLHF模块
DeepSpeed-RLHF复刻了InstructGPT论文中的训练模式,并提供了数据抽象和混合功能,支持开发者使用多个不同来源的数据源进行训练。
3. DeepSpeed-RLHF系统
团队将DeepSpeed的训练(training engine)和推理能力(inference engine) 整合成了一个统一的混合引擎(DeepSpeed Hybrid Engine or DeepSpeed-HE)中,用于RLHF训练。由于,DeepSpeed-HE能够无缝地在推理和训练模式之间切换,因此可以利用来自DeepSpeed-Inference的各种优化。
DeepSpeed-RLHF系统在大规模训练中具有无与伦比的效率,使复杂的RLHF训练变得快速、经济并且易于大规模推广:
DeepSpeed-HE比现有系统快15倍以上,使RLHF训练快速且经济实惠。例如,DeepSpeed-HE在Azure云上只需9小时即可训练一个OPT-13B模型,只需18小时即可训练一个OPT-30B模型。这两种训练分别花费不到300美元和600美元。DeepSpeed-HE能够支持训练拥有数千亿参数的模型,并在多节点多GPU系统上展现出卓越的扩展性。因此,即使是一个拥有130亿参数的模型,也只需1.25小时就能完成训练。而对于拥有1750 亿参数的模型,使用DeepSpeed-HE进行训练也只需不到一天的时间。仅凭单个GPU,DeepSpeed-HE就能支持训练超过130亿参数的模型。这使得那些无法使用多GPU系统的数据科学家和研究者不仅能够轻松创建轻量级的RLHF模型,还能创建大型且功能强大的模型,以应对不同的使用场景。
为了提供无缝的训练体验,研究者遵循InstructGPT,并在DeepSpeed-Chat中包含了一个完整的端到端训练流程。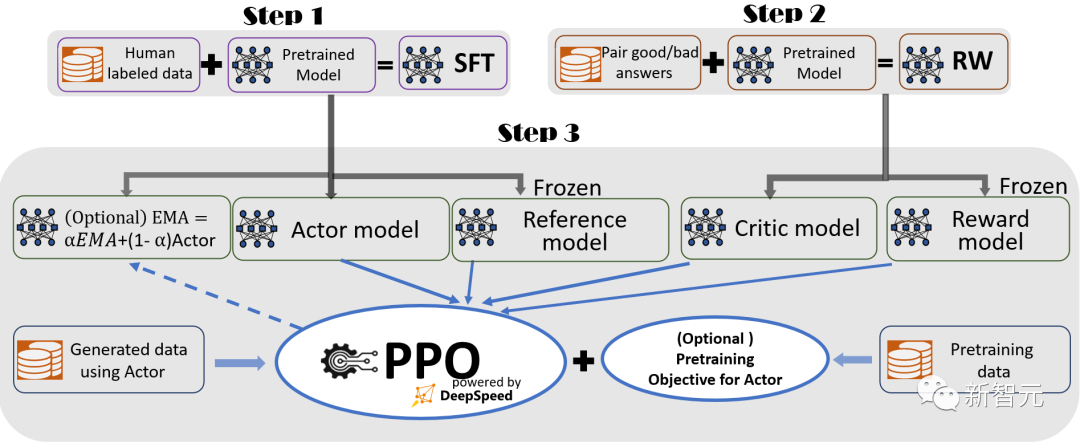
DeepSpeed-Chat的RLHF训练流程图示,包含了一些可选择的功能监督微调 (SFT),使用精选的人类回答来微调预训练的语言模型,以应对各种查询。奖励模型微调,用一个包含人类对同一查询的多个答案打分的数据集,来训练一个独立的(通常比SFT小)奖励模型(RW)。RLHF训练,在这一步,SFT模型通过使用近似策略优化(PPO)算法,从RW模型的奖励反馈进一步微调。在步骤3中,研究者还提供了两个附加功能,来帮助提高模型质量:- 指数移动平均线(EMA)的收集,可以选择一个基于EMA的检查点,进行最终评估。- 混合训练,将预训练目标(即下一个词预测)与 PPO 目标混合,以防止在公共基准(如SQuAD2.0)上的性能回归。EMA和混合训练这两个训练特征,常常被其他的开源框架所忽略,因为它们并不会妨碍训练的进行。然而,根据InstructGPT,EMA检查点往往比传统的最终训练模型提供更好的响应质量,而混合训练可以帮助模型保持训练前的基准解决能力。因此,研究者为用户提供了这些功能,让他们可以充分获得InstructGPT中描述的训练经验。而除了与InstructGPT论文高度一致外,研究者还提供了功能,让开发者使用多种数据资源,训练自己的RLHF模型:DeepSpeed-Chat配备了(1)抽象数据集层,以统一不同数据集的格式;以及(2)数据拆分/混合功能,从而使多个数据集被适当地混合,然后在3个训练阶段进行分割。
指示引导的RLHF管道的第1步和第2步,类似于大模型的常规微调,它们由基于ZeRO的优化和DeepSpeed训练中灵活的并行策略组合,来实现规模和速度。每个迭代都需要有效地处理两个阶段:a)推理阶段,用于token/经验的生成,产生训练的输入;b)训练阶段,更新actor和reward模型的权重,以及它们之间的互动和调度。它引入了两个主要的困难:(1)内存成本,因为在整个第三阶段需要运行多个SFT和RW模型;(2)生成回答阶段的速度较慢,如果没有正确加速,将显著拖慢整个第三阶段。此外,研究者在第三阶段增加的两个重要功能——指数移动平均(EMA)收集和混合训练,将产生额外的内存和训练成本。为了应对这些挑战,研究者将DeepSpeed训练和推理的全部系统能力组成了一个统一的基础设施,即混合引擎(Hybrid Engine)。它利用原有的DeepSpeed引擎进行快速训练模式,同时毫不费力地应用DeepSpeed推理引擎进行生成/评估模式,为第三阶段的RLHF训练提供了一个更快的训练系统。如下图所示,DeepSpeed训练和推理引擎之间的过渡是无缝的:通过为actor模型启用典型的eval和train模式,在运行推理和训练流程时,DeepSpeed选择了不同的优化,以更快地运行模型,并提高整个系统的吞吐量。 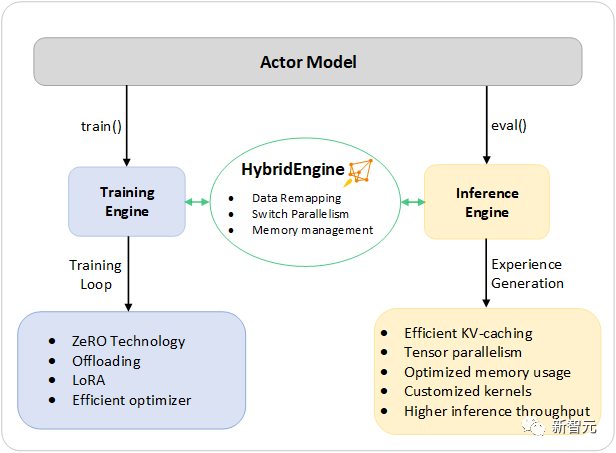
用于加速RLHF流程中最耗时部分的DeepSpeed混合引擎设计在RLHF训练的经验生成阶段的推理执行过程中,DeepSpeed混合引擎使用轻量级的内存管理系统,来处理KV缓存和中间结果,同时使用高度优化的推理CUDA核和张量并行计算,与现有方案相比,实现了吞吐量(每秒token数)的大幅提升。
在训练期间,混合引擎启用了内存优化技术,如DeepSpeed的ZeRO系列技术和低阶自适应(LoRA)。而研究者设计和实现这些系统优化的方式是,让它们彼此兼容,并可以组合在一起,在统一的混合引擎下提供最高的训练效率。混合引擎可以在训练和推理中无缝地改变模型分区,以支持基于张量并行的推理,和基于ZeRO的训练分片机制。它还可以重新配置内存系统,以便在每一种模式中最大限度地提高内存可用性。这就避免了内存分配瓶颈,能够支持大的batch size,让性能大大提升。总之,混合引擎推动了现代RLHF训练的边界,为RLHF工作负载提供了无与伦比的规模和系统效率。
与Colossal-AI或HuggingFace-DDP等现有系统相比,DeepSpeed-Chat具有超过一个数量级的吞吐量,能够在相同的延迟预算下训练更大的演员模型或以更低的成本训练相似大小的模型。例如,在单个GPU上,DeepSpeed使RLHF训练的吞吐量提高了10倍以上。虽然CAI-Coati和HF-DDP都可以运行1.3B的模型,但DeepSpeed可以在相同的硬件上运行6.5B模型,直接高出5倍。在单个节点的多个GPU上,DeepSpeed-Chat在系统吞吐量方面比CAI-Coati提速6-19倍,HF-DDP提速1.4-10.5倍。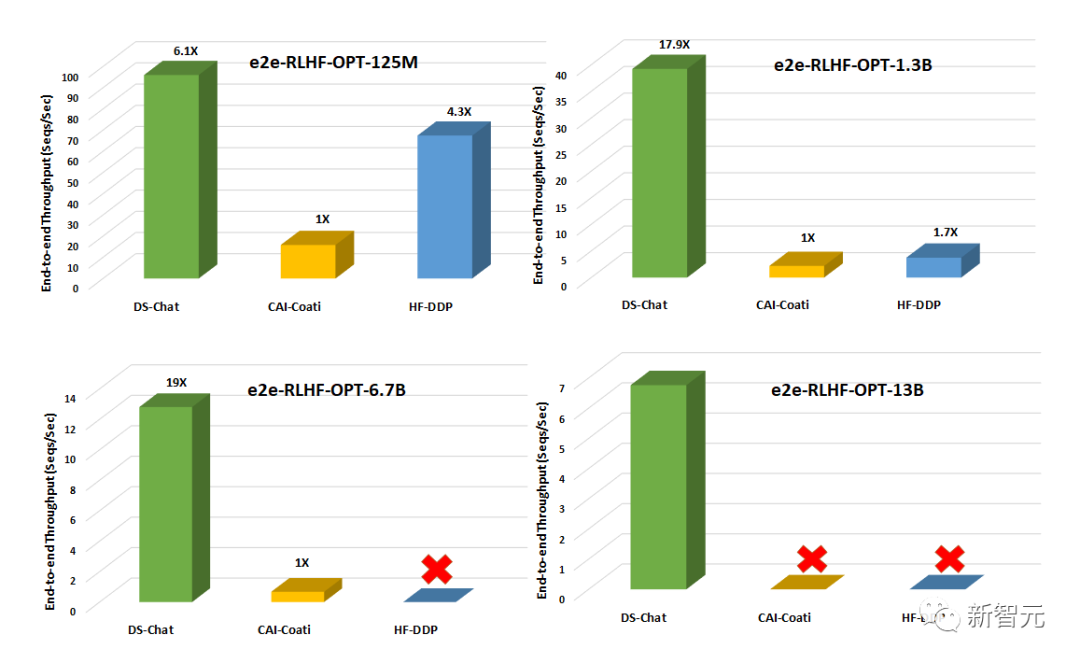
团队表示,DeepSpeed-Chat能够获得如此优异的结果,关键原因之一便是混合引擎在生成阶段提供的加速。https://github.com/microsoft/DeepSpeed











