
理解因果关系有助于构建干预措施,以实现特定目标,并实现干预措施下的预测。随着因果关系学习的重要性日益突出,因果发现任务已经从使用传统方法从观察数据中推断潜在的因果结构转向深度学习所涉及的模式识别领域。海量数据的快速积累促进了具有良好可扩展性的因果搜索方法的出现。现有的因果发现方法综述主要集中在基于约束、评分和FCMs的传统方法上,缺乏对基于深度学习的方法的完善梳理,也缺乏对可变范式视角下的因果发现方法的思考和探索。因此,我们根据变量范式将可能的因果发现任务划分为三种类型,并分别给出了三种任务的定义,定义并实例化了每一任务的相关数据集和最终构建的因果模型,然后回顾了现有的针对不同任务的主要因果发现方法。最后,针对目前因果发现领域的研究空白,从不同角度提出了一些路线图,并指出了未来的研究方向。
https://arxiv.org/abs/2209.06367
导论
因果关系是一种结果和导致结果的treatment 之间的关系。它在我们的生活中无处不在,涉及到几个领域,如统计学[2]-[5],经济学[6],[7],计算机科学[8]-[11],流行病学[12]-[14],心理学[15],[16]。举一个生活中常见的现象,例如,很多人因为下雨而打伞,或者一个学生因为没有学习而考试考得不好。这种因果关系是因果关系的最简单表达。然而,我们需要意识到统计相关性和因果关系[17],[18]之间的差异。例如,尼龙袜和肺癌在上个世纪同时大量出现,我们只能得出两者之间有相关性而不是因果关系,因为吸烟也在这个时候增加了。近年来,因果关系的研究已成为人工智能领域的重要组成部分,从而克服了基于统计的机器学习[19]-[21]的一些局限性。基于有向无环图(DAG)[22]、[23]结构和贝叶斯模型[24],基于有向无环图(DAG)[22],[23]结构和贝叶斯模型[24],[25],旨在了解两个观测变量在另一个变量影响下的统计关系。此外,因果关系一般可以分为两个主要方面,因果发现和因果结果推断[26],[27]。因果发现[28],[29]侧重于从观测数据中获取因果关系,构建结构因果模型[30],[31],使因果效应推理[32]-[34]可以通过结构因果模型估计变量的变化。因果发现作为因果推理的必要途径和前提条件,近年来备受关注。
因果发现是确定因果关系的过程,从建立因果骨架开始,进一步以严格的DAG(相关算法[21]通常称为SCMs)结束。因果骨架[27],[35]是一个完全无向图,所有成对变量都由其中的无向边连接。然后,根据条件约束和独立成分分析等统计方法对因果骨架上的因果算法[36],对无向边进行定向,得到每个有向边代表一个变量对另一个变量的影响的SCMs。早在机器学习[37],[38]的早期,它就提出了基于条件约束的方法,如IC [39], [40], SGS[41]和PC[38],[42],[43],后来又提出了基于分数的方法GES[44],这些传统方法提出了正确的因果假设并结合图模型来发现因果关系。然后,提出了基于LiNGAM[45]、[46]和ANM[47]、[48]功能因果模型(FCMs)的方法,进一步提高了模型的计算效率和适用性;这些都是主流的因果发现方法,因此有许多混合方法[49]-[51]和改进方法结合它们的优点。
以上都适合于探索具有一定数量和值的多个内生变量之间的因果关系,也是研究因果发现的初始领域。由于已有丰富的研究基础,因果关系的发现已逐渐扩展到模式识别[52]、[53]等领域,如图像模式识别、文本模式识别等。研究人员发现,在这些内源性二元变量样本中,不同区域和部分之间也存在因果关系,例如在人脸识别[54]、[55]、细粒度识别[56]、文本情感识别[57]和其他任务[58]、[59]中。这种因果发现方法需要根据研究者的先验知识或建模需求,将传统模式识别中的样本与标签之间的相关性解释为可识别样本中每个区域或部分的因果结构。随着这一领域因果发现方法的逐渐多样化,我们考虑是否存在另一种类型的更复杂的变量。一方面,从任务的角度来看,识别、分类、分割等静态任务的总体成就促使研究者探索由一系列静态任务组成的动态序列;另一方面,从模型的角度来看,主流网络模型的深化意味着简单的任务不再能反映模型之间的差距,因此越来越需要更细粒度的标签和更多可解释性的研究。这些原因促使因果发现的研究领域向深度学习领域的序列任务深入。
此外,因果发现的路线图是USCM的构建。根据现有方法的思想,我们提出了三种路线图:基于优先级、基于抽样和基于确定性的方法。因果关系本质上是一种理论,考虑潜在的原因[60]超过两个变量。就因果理论创立的初衷而言,如果仅仅局限于一个确定或半确定的因果骨架,是不够接近现实因果关系的。随着深度学习的不断发展,USCM是因果理论接近现实世界因果关系的最终目标。这也将驱使我们处理更多与因果相关的任务,例如构建情感和知识产品的过程。此外,基于干预和反事实的研究可以走得更远,试图达到人工智能领域的下一个阶段。
总的来说,我们的贡献如下。首先,我们定义了三种类型的任务并说明了它们的过程;其次,定义了三类变量数据集,并比较了它们的不同特征; 第三,界定了三种类型的变量因果范式,并分析了它们的构建过程; 最后,针对USCM面临的新挑战,提出了一些解决抽样不足导致因果发现方法不足问题的路线图。本文的其余部分组织如下。第二部分定义了明确任务、MVD和DSCM,总结了该范式下常见的MVD和因果发现方法。第三部分界定了半确定任务、BVD和SSCM,梳理了不同领域的BVD及其因果发现方法。同样,我们定义了不确定任务、IVD和USCM,总结了现有的常用数据集和相关任务,并在第四节比较了这三种数据集与SCM的异同。据此,我们在第五节分析了当前的挑战并提出了路线图。最后一节得出了本文的总体结论。
确定性任务
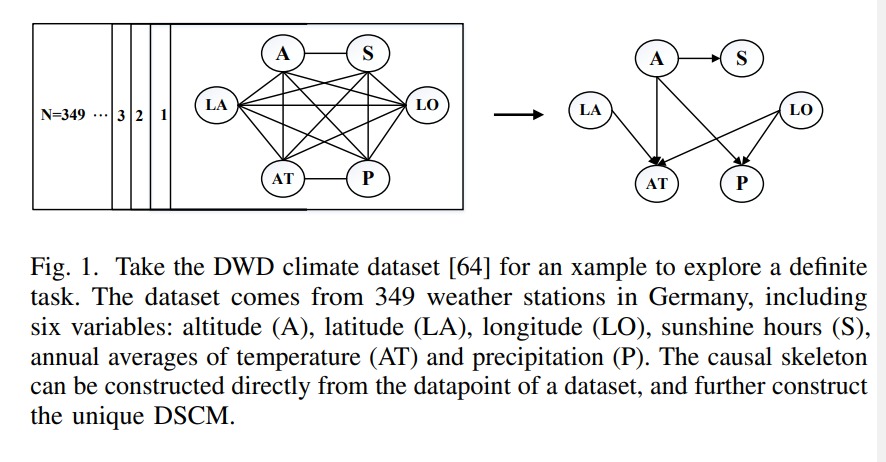
在本节中,我们将初始的因果发现任务定义为确定任务,将数据集MVD用于该任务,并将最终的模型DSCM用于显示已知多个变量中的因果关系。如前所述,我们可以使用不同类型的因果方法来构建DSCM。基于约束和基于评分的方法相对容易理解,但它们受到一些假设的限制,这些假设导致了一些问题,如MEC不可分离性,需要大量样本来证明可信度,以及无法处理潜在的混杂因素。因此,基于模糊c均值聚类(FCMs)的方法将因果关系以矩阵的形式表示,并首次引入了外生变量(噪声项)的概念,具有普适性。这些方法都有一个假设,如数据之间的独立性和外生变量的非高斯性质。既解决了上述局限性,又避免了在条件相关或评分函数中可能遇到的其他问题。混合方法的好处是它结合了不同方法的优点,但它也可能意味着增加复杂性。总之,研究人员很容易通过任何一种方法获得SCM。因此,他们可以根据建模的需要、数据集的特征和个人喜好来选择不同的方法。
半确定性任务
在本节中,我们定义了另一种常见的因果发现任务,并根据其特点定义了相应的数据集和SCM,总结了现有的研究方法。如前所述,我们对不同的方法进行了比较研究,例如图像数据比文本数据更容易划分特征块和提取先验共识。在图像数据中,因果表示直观且易于表示,但需要用词向量来表示数据,然后根据先验从关键词中提取特征块。这一过程可能会受到不同写作风格的影响,其中的特征不如图像数据那么直观,因此也会有不同,以避免我们忽略的混淆因素和其他偏见。另一方面,文本数据可以直观地向研究人员传达一些信息,容易推断因果关系,如文本主题与情感分析、语法分析等。这些优点可以帮助解决图像识别中的一些困难和矛盾。此外,我们提出了一些指标来描述与SSCM性能间接相关的视觉结果。虽然不能直接判断SSCM的好坏,但可以为后续实验带来更多的可解释性内容。综上所述,因果发现中SSCM的存在是非常重要和不可避免的,它有助于我们通过深度学习的方法更好地学习样本表示及其上下文特征。
不确定性任务
在本节中,我们定义了一种新的因果发现任务——不确定任务,并根据其特点定义了相应的数据集IVD和USCM,总结了现有的不同类型的IVD。此外,IVD还有一些特性。序列数据本身包含许多因果关系。例如,在对话序列中,不同人之间的对话是相互依赖的;在音乐序列中,不同的节奏部分相互作用;在视频序列中,视频的每一帧都是一张图片,图片中的不同物体有各自的因果关系。从另一个角度来看,视频序列的因果关系比对话序列的因果关系更连续,对话的性质导致了离散的因果关系。通过对MVD、BVD和IVD的整理和比较,我们发现它们的相似之处在于它们都涉及相同的因果问题和结论。例如,这些数据集中存在先验;所有这些数据集都可能存在混杂因素,其中混杂因素均以叉形结构存在,且都需要排除混杂因素的影响;同样,我们都可以对这些数据集进行一些因果操作,如干预和反事实。另一方面,两者之间也有一些区别。在MVD中,多个变量在数量、意义和抽样上都有明确的反映,因此,当我们可以根据MVD的先验直接获得唯一的因果骨架,进而构建唯一的DSCM时;在BVD中,只有两个确定的原始变量,多维时空序列数据被标记为多种类型,只能根据研究者的先验知识从数据中划分出其他外生变量来构建因果骨架。虽然有一定数量的因果变量,但由于BVD的弱先验,我们最终得到的SSCM并不是唯一的。此外,IVD也有两个变量,但是它的数据和标签是以序列的形式存在的,所以我们很难获得除了样本量之外的其他确定的信息。我们需要将不同的序列片段作为因果变量来构建因果骨架,因此得到的USCM并不是由于其不可抽样性而造成的唯一原因,USCM的数量接近于IVD的样本量。
专知便捷查看
便捷下载,请关注专知人工智能公众号(点击上方蓝色专知关注)
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取100000+AI(AI与军事、医药、公安等)主题干货知识资料!
点击“阅读原文”,了解使用专知,查看获取100000+AI主题知识资料







