
Hi,大家好,我是晨曦
今天这期推文,我们重点来学习一个有意思的技能,当然这个技能其实也是小伙伴私信晨曦的,那么我们先来看看这位小伙伴面临的问题是什么?
A同学:晨曦,我有一些感兴趣的基因,我想要批量的进行模型验证并且绘制ROC曲线,但是我这里的模型我想使用机器学习的模型,有没有好用的“轮子”可以让我直接使用呢?
晨曦:......
那么,其实我们可以把上面小伙伴的需求概括一下:如何快速、便捷的实现多个基因依次构建多种模型并且绘制ROC曲线
既然问题已经凝炼出来了,那么我们就开始尝试解决这个问题,然后这次我们使用的技能其实就是晨曦在前几期推文中介绍到的能力,分别是:循环操作以及mlr3包的使用,那么,我们开始吧~
library(mlr3)library(mlr3learners)library(mlr3viz)library(mlr3verse)library(tidyverse)library(ggplot2)library(patchwork)
工欲善其事必先利其器~
这里晨曦依旧推荐各位小伙伴,如果想要在R中进行机器学习,那么mlr3包是你不可以错过的一个分析利器~
load("课题设计/项目2/data.Rdata")data
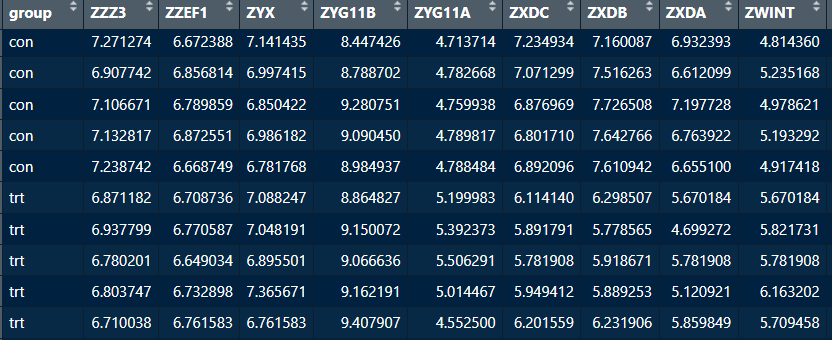
我们可以很清楚的看到,我们这个数据其实就是一个包含分组信息的数据,第一列为分组信息,我们可以理解为响应变量,然后后面的每一列都是一个基因,可以理解为预测变量,而我们构建模型的过程其实就是通过预测变量去预测响应变量
注意:我们在进行批量操作之前,一定要确保我们可以完成一次操作,所以接下来我们将尝试完成一次操作
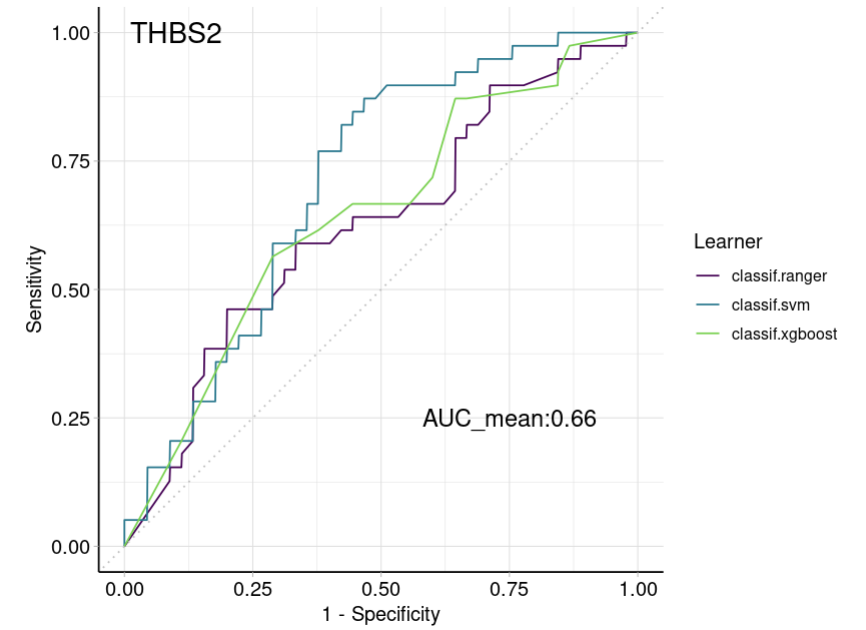
task "THBS2","group")],target = "group",positive = "trt")design = benchmark_grid( tasks = task, learners = lrns(c("classif.ranger", "classif.svm", "classif.xgboost"), predict_type = "prob", predict_sets = c("train", "test")), resamplings = rsmps("holdout") )bmr = benchmark(design)
autoplot(bmr,type = "roc") + theme(legend.position = "right")+ annotate(geom="text", x=0.75, y=0.25,size = 5,label="AUC_mean:0.66")+ annotate(geom="text", x=0.1, y=1,size = 6,label="THBS2")
那么接下来是素质三联的时间:
提问:晨曦,你这里都运用了哪三种机器学习模型?
回答:分别使用了ranger随机森林、SVM支持向量机、xgboost极限梯度提升
提问:如果建议使用一种模型,那么我们应该运用什么模型比较好?
回答:针对表达数据或者是大维度数据,随机森林的表现可能会比较好,因为对数模型对数据的要求比较宽容
提问:晨曦,我除了这个可视化,可不可以获得每一个模型的评价指标?
回答:可以尝试运行下面这行代码:
measures = list( msr("classif.auc", predict_sets = "train", id = "auc_train"), msr("classif.auc", id = "auc_test") )tab = bmr$aggregate(measures)print(tab)# nr resample_result task_id learner_id resampling_id iters#1: 1 data[, c("THBS2", "group")] classif.ranger holdout #1#2: 2 data[, c("THBS2", "group")] classif.svm holdout #1#3: 3 data[, c("THBS2", "group")] classif.xgboost holdout #1# auc_train auc_test#1: 0.9476912 0.6250712#2: 0.7106061 0.7068376#3: 0.8313853 0.6444444
好,到这里我们完成了一次操作,那么我们结合前面推文中学习到的循环技能,我们就可以进行批量的操作
df
sig "THBS2","SIRPA","SFRP1","SERPINA5","SAA1","PLAT")
for (i in sig) { print(i) task "group")],target = "group",positive = "trt") design = benchmark_grid( tasks = task, learners = lrns(c("classif.ranger", "classif.svm", "classif.xgboost"), predict_type = "prob", predict_sets = c("train", "test")), resamplings = rsmps("cv") ) bmr = benchmark(design) df[[i]] }
df
我们可以看到,我们先前创建的容器中就包含了多次循环的结果,然后我们只需要把结果提取出来进行绘图+拼图,我们就可以制作出一张比较精美的批量ROC+多模型的结果
p1 "THBS2"]],type = "roc") + theme(legend.position = "right" ,legend.box = "horizontal") + annotate(geom="text", x=0.75, y=0.25,size = 5,label="AUC_mean:0.66")+ annotate(geom="text", x=0.1, y=1,size = 6,label="THBS2") p2 "SFRP1"]],type = "roc") + theme(legend.position = "right" ,legend.box = "horizontal"
) + annotate(geom="text", x=0.75, y=0.25,size = 5,label="AUC_mean:0.83")+ annotate(geom="text", x=0.1, y=1,size = 6,label="SFRP1") p3 "SERPINA5"]],type = "roc") + theme(legend.position = "right" ,legend.box = "horizontal") + annotate(geom="text", x=0.75, y=0.25,size = 5,label="AUC_mean:0.96")+ annotate(geom="text", x=0.1, y=1,size = 6,label="SERPINA5") p1 + p2 + p3 + plot_layout(guides = 'collect')
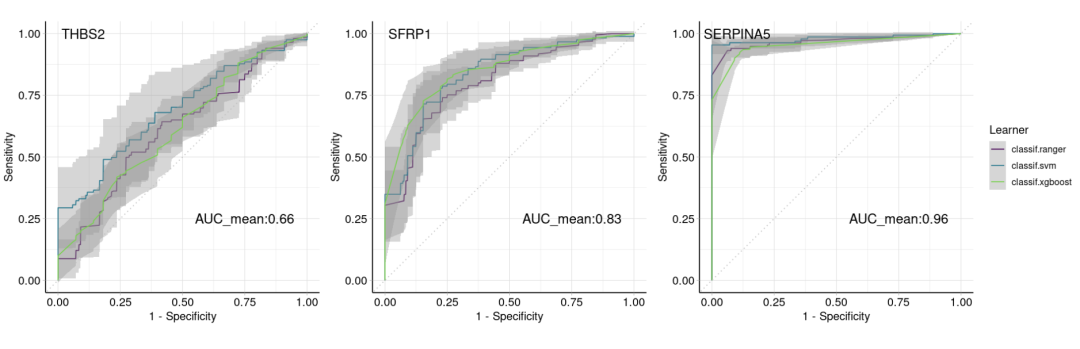
我们通过mlr3实现多个模型同时进行构建并进行模型评价,同时通过for循环执行重复操作,并通过patchwork包把我们的可视化结果拼起来,整套流程还算是比较简洁的~希望本期推文可以给学习机器学习或者正在进行模型构建的小伙伴一点启发,也欢迎各位小伙伴在评论区评论感兴趣的内容,晨曦也好有方向进行浪学~








