Attention is All You Need
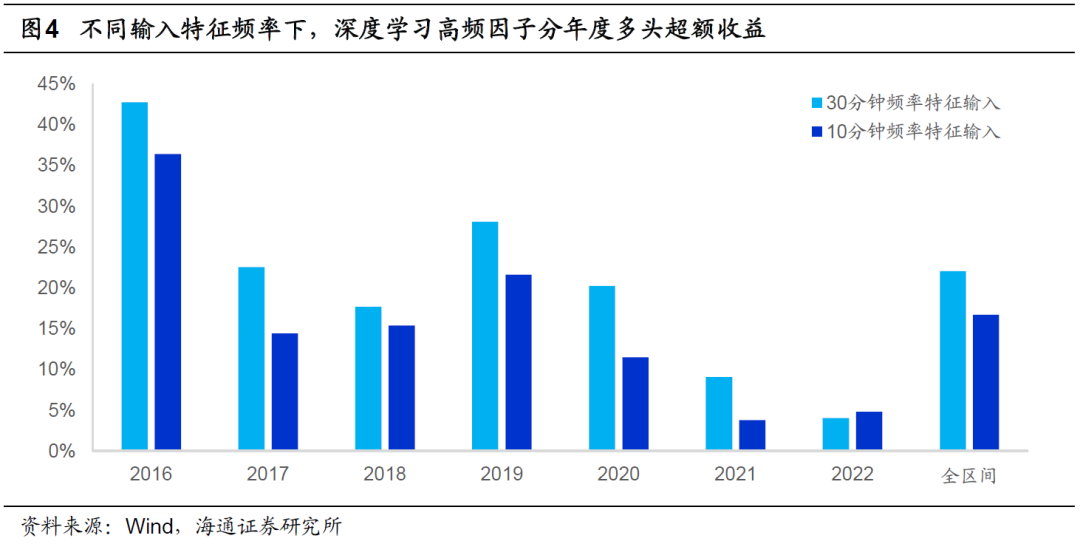
但是,在这一系列的改进中,我们发现,当我们尝试将模型的输入特征频率从30分钟提升至10分钟时,因子表现,如周均IC、ICIR和分年多头超额收益,反而出现了下降(表1、图4)。

直觉上,更高频的输入特征应当包含更多的信息,选股效果也会更好,但相反的测试结果不得不让人思考可能的原因。我们认为,在处理长度大幅提升的序列时,GRU和LSTM模型信息提取能力不足的问题被暴露出来。换句话说,当输入序列过长时,GRU和LSTM模型前期学习到的特征很难体现在最终的输出中,也就是模型“遗忘”了部分信息。
具体到我们当前使用的模型中,高频特征集合被输入RNN后,可得到T期的隐含状态。经过迭代后,最后一期的隐含状态被输入后续模型。我们发现,这一做法在输入序列长度适中时不会产生较为严重的“遗忘”问题,最后一期的隐含状态依旧能够保留早期数据中的重要信息。但输入序列一旦过长,即使是本身就用于解决序列“记忆性”问题的GRU和LSTM模型,也会“遗忘”大量早期数据中的信息。
面对“遗忘”问题,一个较为直接的解决办法是,对于RNN每一期输出的隐含状态进行第二次信息提取,再输入后续模型,而非简单地使用最后一期的隐含状态。至于如何实现信息再提取,最简单的思路就是对每期的隐含状态赋权,而权重则可以通过引入注意力机制来确定。
注意力机制的研究发轫于上世纪90年代。2014年Volodymyr发表的《Recurrent Models of Visual Attention》,介绍了它在视觉领域的应用。2017年,随着Ashish Vaswani等人撰写的《Attention is All You Need》的发表,注意力机制开始被推广至NLP、CV等领域。近年来,注意力机制因具备较强的处理信息“遗忘”问题的能力,而被广泛应用于时间序列数据的研究中。
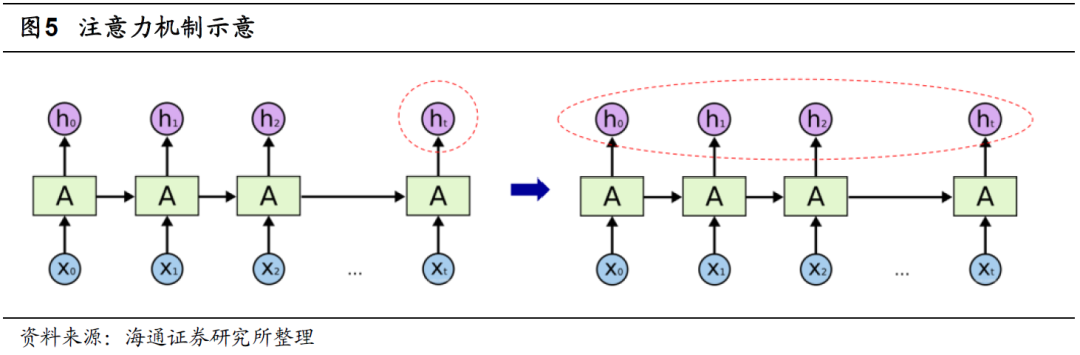
简单来说,注意力机制的本质是将人类关注重要信息而忽略无效信息的行为方式应用在机器上,让机器学会感知数据中重要和不重要的信息。在本文的应用情境下,就是训练模型学会如何在历史各期隐含状态之间合理分配权重,将更高的权重赋予重要时刻。
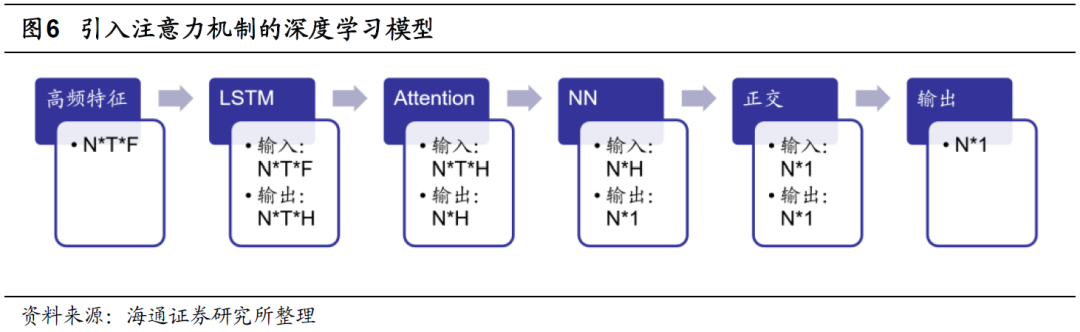
注意力机制有多种形式,本文选择的是自注意力机制(Self-Attention)。即,使用查询(Query)-键(Key)-值(Value)的模式计算注意力分数。由于篇幅的限制,本文不详细介绍自注意力机制,感兴趣的投资者可自行查阅相关内容或咨询作者。基于注意力分数,我们可对RNN输出的各期隐含状态赋权,并将它们一同输入后续模型中。引入注意力机制后的深度学习高频因子的训练流程如下图所示。
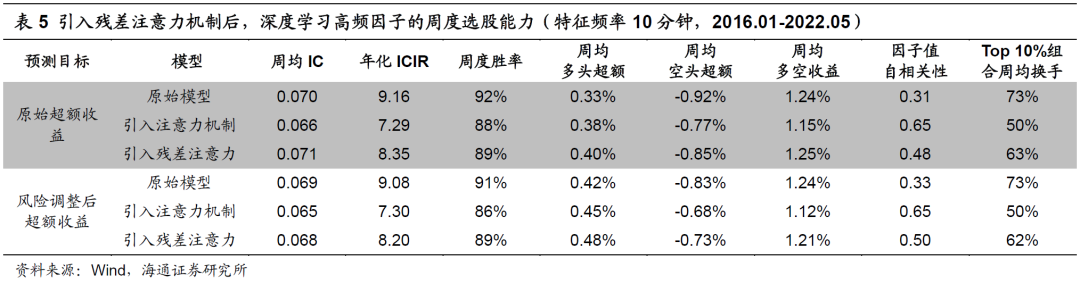
在下表展示了滚动6个月训练且特征频率为10分钟时,引入注意力机制前后,因子费前的周度选股能力。

引入注意力机制后,因子周均IC、ICIR和IC周度胜率虽出现了小幅下降,但周均多头超额收益反而有所增加。同时,因子的自相关性从原来的0.31大幅提升至0.65,Top 10%组合的周均换手率则从原来的73%下降至50%。
在实际应用中,更高的换手率意味着更高的成本。因此,引入注意力机制对因子多头超额收益的提升幅度或将比上表中展示的更加显著。
组合换手率的下降主要是因为,原模型仅使用RNN模型最后一期的隐含状态作为后续模型的输入,而引入注意力机制后,历史各期的隐含状态会按照一定的权重共同向后传导,相当于对历史信息进行了平滑。因此,最终得到的因子自相关性更高,由此构建的多头组合的换手率更低。
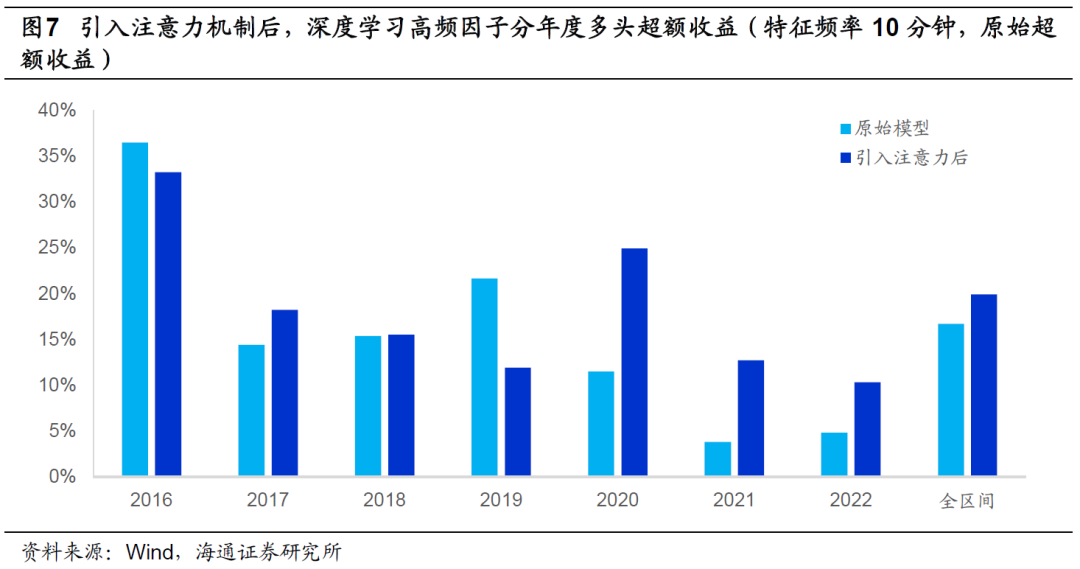
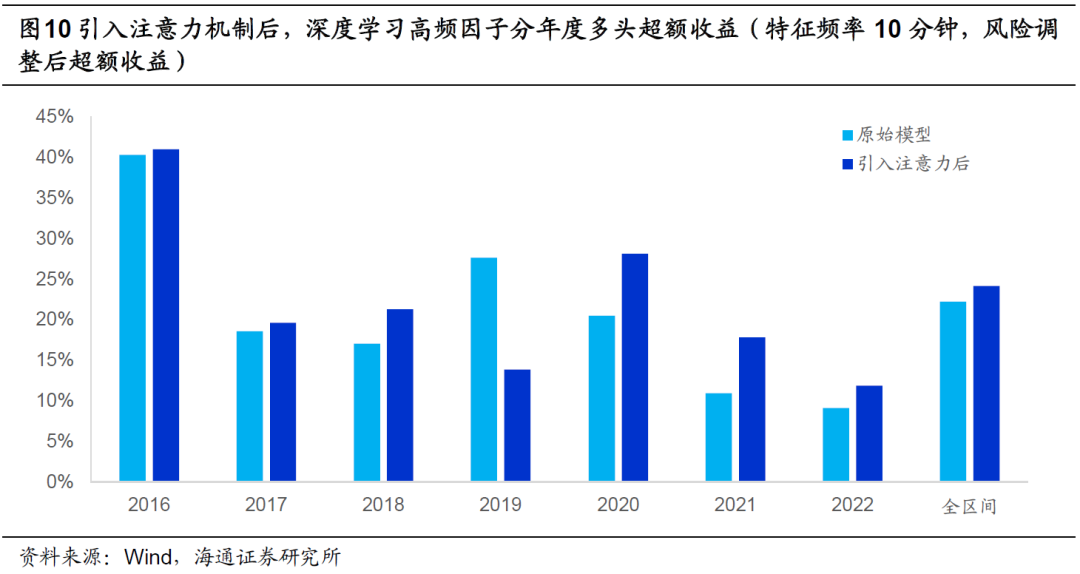
下图进一步对比了引入注意力机制前后,因子的分年度多头超额收益。在全区间以及大部分年份中,引入注意力机制都可提升因子的多头选股能力。尤其是2020-2022年,提升幅度较为明显。但需要注意的是,引入注意力机制也会使得2019年的多头超额收益蒙受较大幅度的损失。
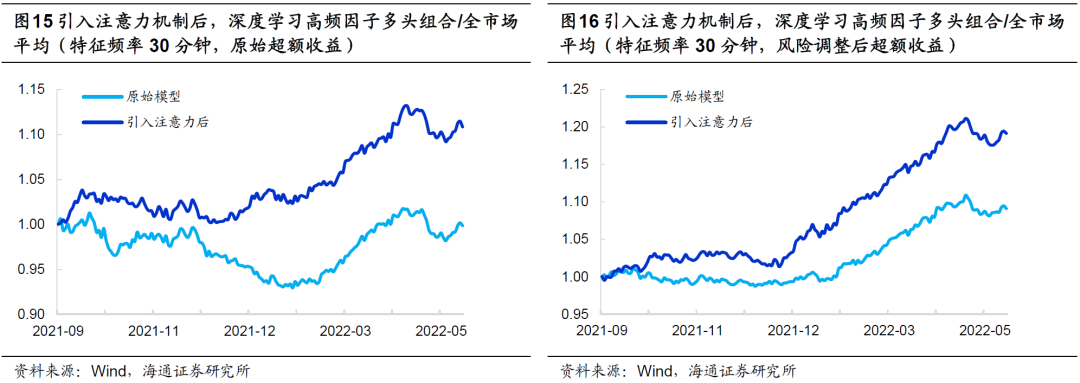
我们进一步观察引入注意力机制前后,因子2021年9月至今的多头超额收益以及相对全市场平均的强弱走势。引入注意力机制后,因子的回撤大幅减小,相对净值创新高的速度更快,改进十分明显。
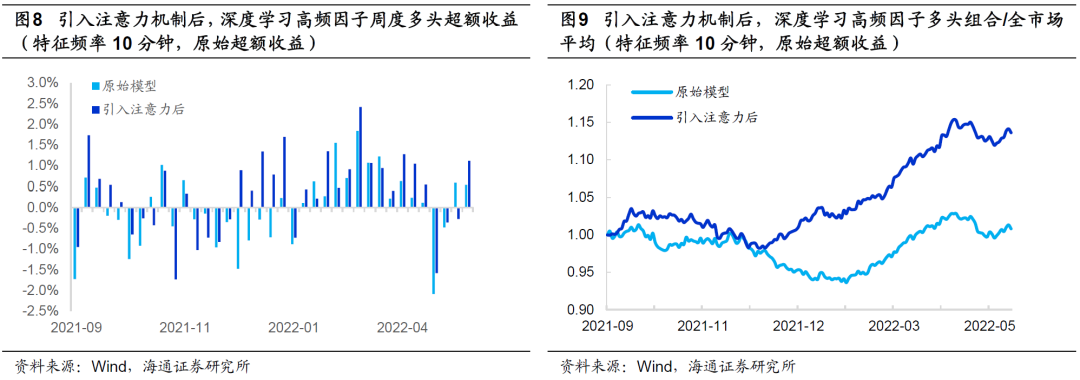
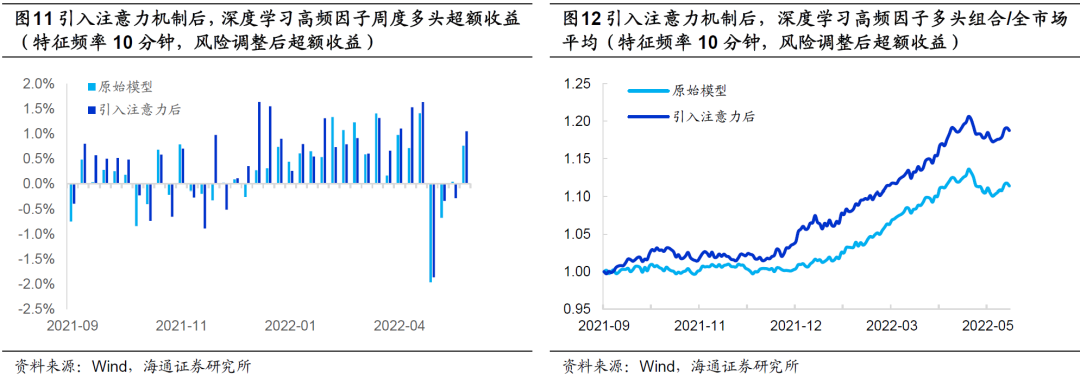
在报告《改进深度学习高频因子的9个尝试》中,我们发现,用风险调整后收益代替原始收益作为预测目标,可提升深度学习高频因子的表现。引入注意力机制后,同样可从以下图表中观察到选股效果的提升,且改进的幅度和方式与使用原始超额收益一致。

综上所述,我们认为,在利用GRU或LSTM生成深度学习高频因子的过程中,若输入特征的频率较高、序列较长,可引入注意力机制优化因子的多头超额收益。根据我们的测试结果,2016-2022.05,引入注意力机制的因子有着更高的多头年化超额收益。
更为值得一提的是,因子2020年至今的表现显著提升,2021.09-2022.01期间的回撤大幅减小,净值创新高的速度也更快,在一定程度上改善了潜在的因子拥挤问题。此外,注意力机制的引入还大幅提高了因子的自相关性,使得多头组合的换手率明显下降,对实际应用更有价值。
引入注意力机制有效改善了特征频率为10分钟时,GRU和LSTM模型的信息“遗忘”问题。那么,当频率下降至30分钟后,是否也会产生类似的效果呢?
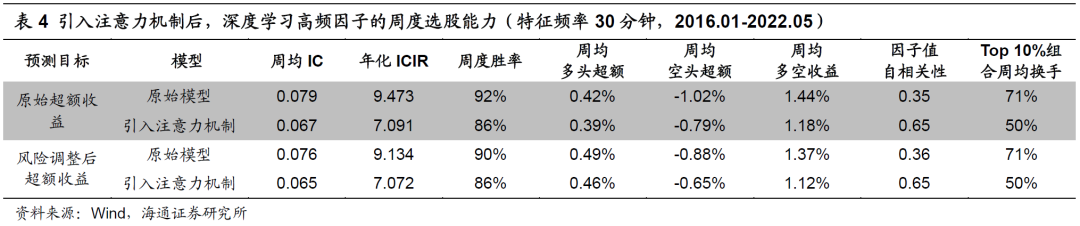
如上表所示,除了Top 10%组合换手率下降以外,因子的表现全面不及原始模型。不过,由以下两图可见,引入注意力机制在一定程度上提升了2020年至今的因子多头超额收益。
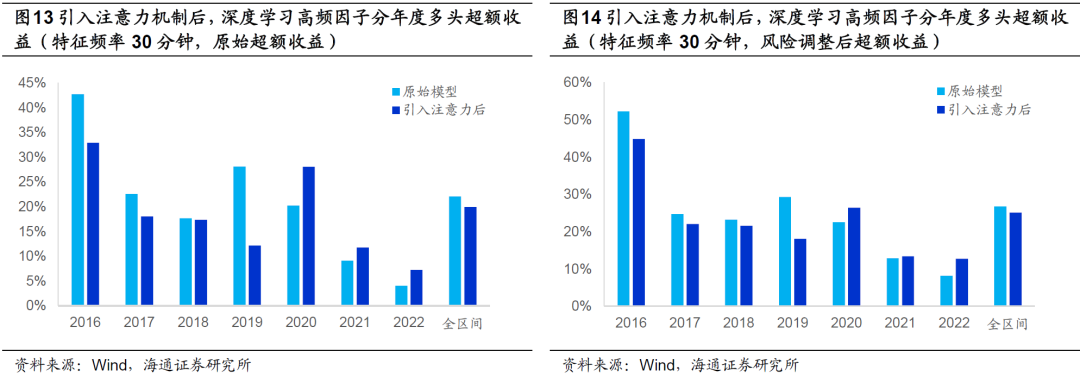
类似地,特征频率为30分钟时,引入注意力机制同样能显著改善因子在2021年四季度的回撤幅度。
综合以上分析结果,我们认为,在利用GRU或者LSTM训练深度学习高频因子的过程中,引入注意力机制至少是一个值得一试的选择。首先,多头组合的换手率下降几乎是确定的,这对那些有一定换手率约束的机构投资者,如公募基金,有着十分积极的意义。其次,当输入序列较长时,训练得到的因子的多头超额收益获得了较为显著的提升。第三,不论特征频率为10分钟还是30分钟,2020年至今的因子表现都明显改善,包括每一年度更高的超额收益、2021年四季度更小的回撤以及更快的净值创新高速度。
然而,不论是何种特征频率或预测目标,引入注意力机制后,因子2019年的表现都出现了大幅下降,难免让人担忧因子的稳健性。因此,我们借鉴Transformer模型的理念,在引入注意力机制的基础上结合残差连接(后文简称为残差注意力),进一步优化深度学习高频因子。
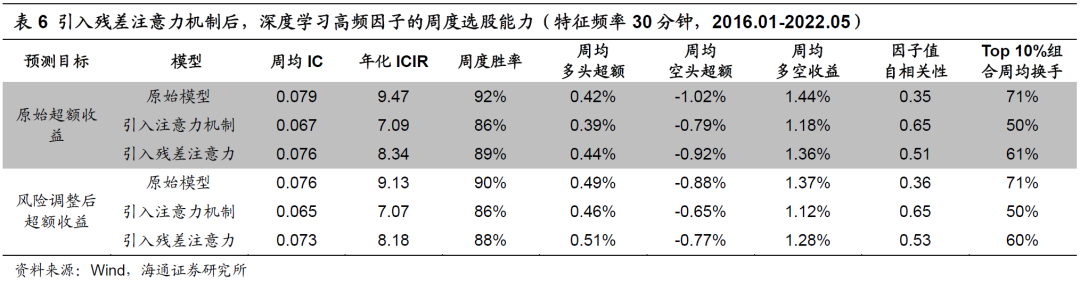
下表展示了输入特征频率为10分钟时,原始模型、引入注意力机制和残差注意力机制后,因子选股效果的对比。
在两种预测目标下,引入残差注意力机制后,因子的周均IC回升到了和原始模型几乎一致的水平。与此同时,多头超额收益则相对引入注意力机制的因子进一步提升。因子自相关性和Top10%组合的换手率方面,引入残差注意力机制的模型恰好是另外两个模型的折中。
将特征频率降至30分钟后,三个模型对应的因子业绩表现和特征频率为10分钟时无异。具体表现为,引入残差注意力机制后的因子有更高的多头超额收益,相对适中的因子自相关性和周度换手率。
下图展示了不同模型的分年度多头超额收益。引入残差注意力机制并没有明显削弱注意力机制模型2020年至今的选股表现,同时,2019年的多头超额收益也大致与原始模型持平。因此,在两种特征频率之下,2016年以来,残差注意力机制模型均获得了最高的年化超额收益。
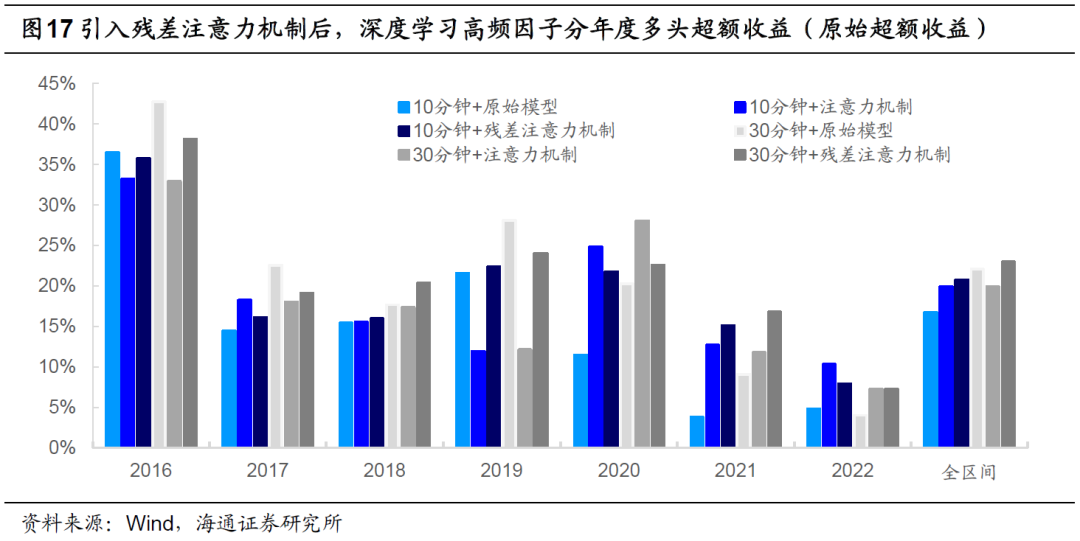
将预测目标变化为风险调整后超额收益,得到了和图17类似的结果。相对而言,特征频率为30分钟时,引入残差注意力机制生成的因子在所有模型中的多头年化超额收益最高。
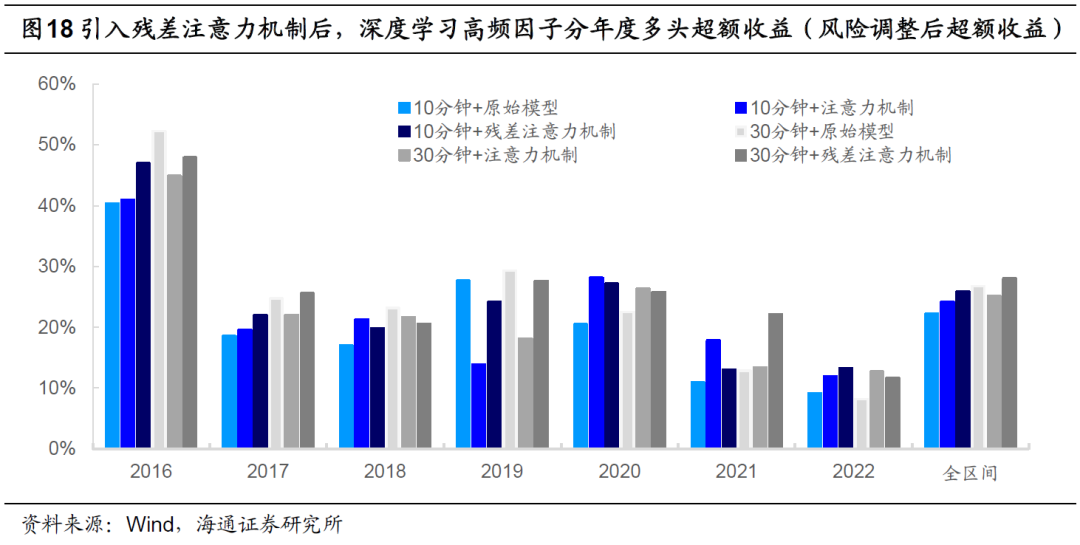
如以下4图所示,2021年9月以来,注意力机制模型和残差注意力机制模型的表现较为接近,均显著优于相同特征频率下的原始模型。
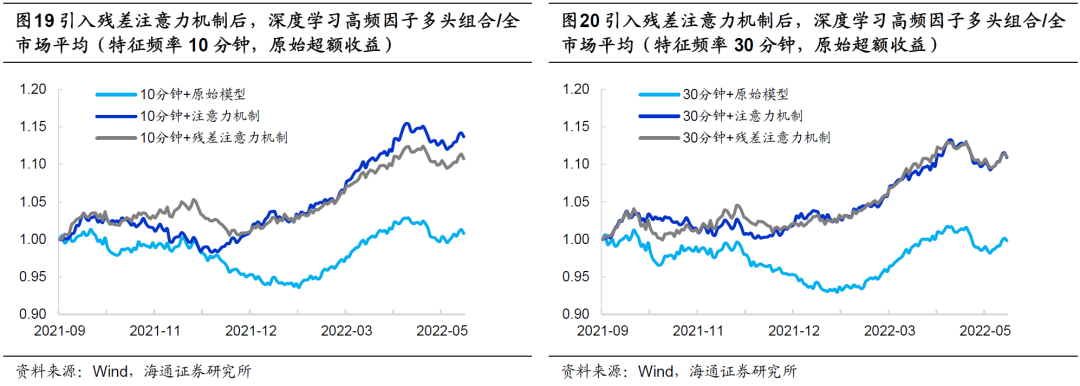
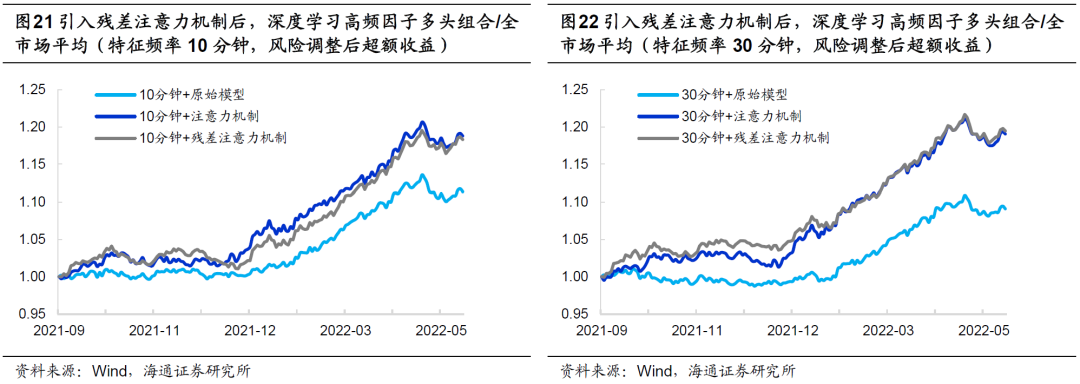
综上所示,我们认为,用残差注意力机制替换简单注意力机制能够进一步优化深度学习高频因子的表现。具体表现为,因子不仅在2020年起的每一年都取得了更高的多头超额收益,而且在2016-2019期间,展现出不弱于原始模型的业绩,尤其是在简单注意力机制模型表现较弱的2019年。此外,因子的自相关性显著高于原始模型,因而Top 10%组合的换手率更低。
分别将引入注意力机制前后,RNN模型生成的深度学习因子加入周度调仓的中证500指数增强模型,对比最终的业绩。其他因子包括:市值、中盘(市值三次方)、估值、换手、反转、波动、盈利、SUE、分析师推荐、尾盘成交占比、买入意愿占比和大单净买入占比。
在预测个股收益时,我们首先采用回归法得到因子溢价,再计算最近12个月的因子溢价均值估计下期的因子溢价,最后乘以最新一期的因子值。
风险控制模型包括以下几个方面的约束:
1) 个股偏离:相对基准的偏离幅度不超过1%、2%;
2) 因子敞口:市值、估值中性、常规低频因子≤ ±0.5,高频因子≤ ±2.0;
3) 行业偏离:严格中性;
4) 换手率限制:单次单边换手不超过30%。
组合的优化目标为最大化预期收益,目标函数如下所示:
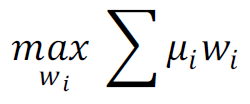
其中,wi为组合中股票i的权重,μi为股票i的预期超额收益。为使本文的结论贴近实践,如无特别说明,下文的测算均假定以次日均价成交,同时扣除3‰的交易成本。
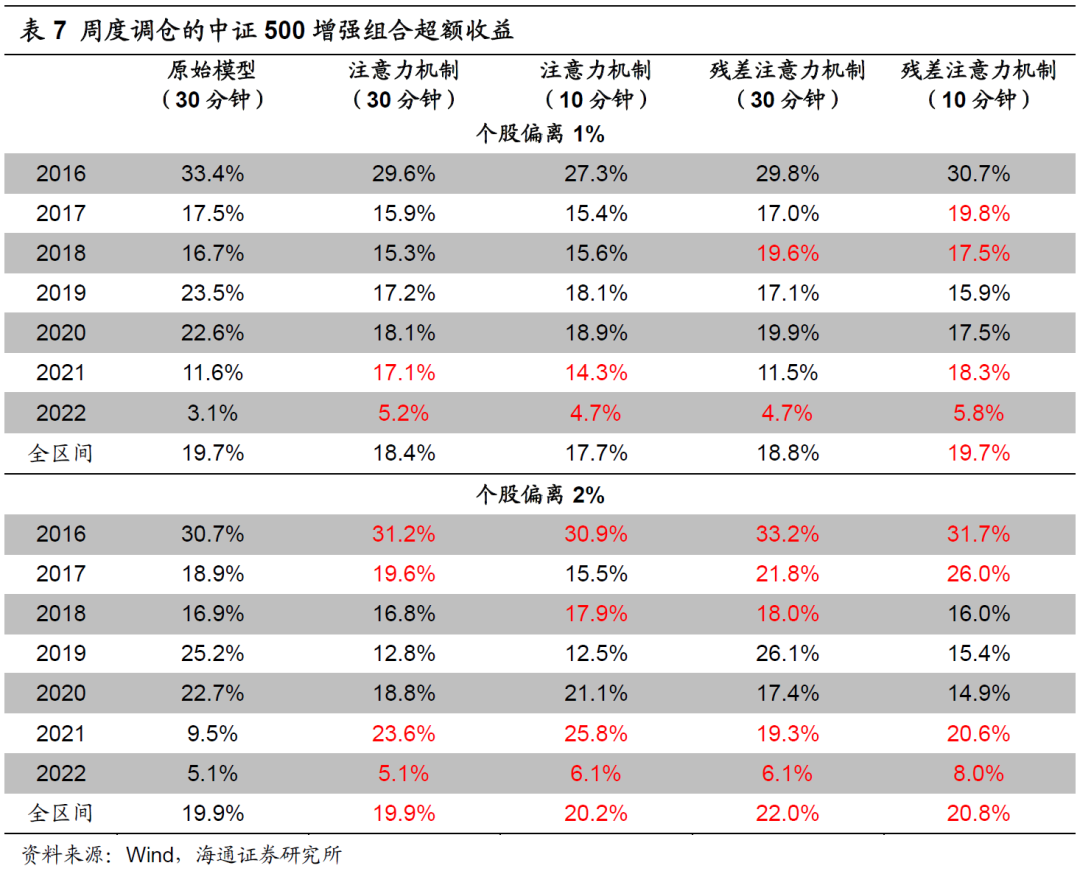
由下表可见,将注意力机制模型生成的因子替换原始高频因子,均能有效改进原始模型2021年至今的超额收益。当个股偏离为2%时,全区间的年化超额收益也获得提升。
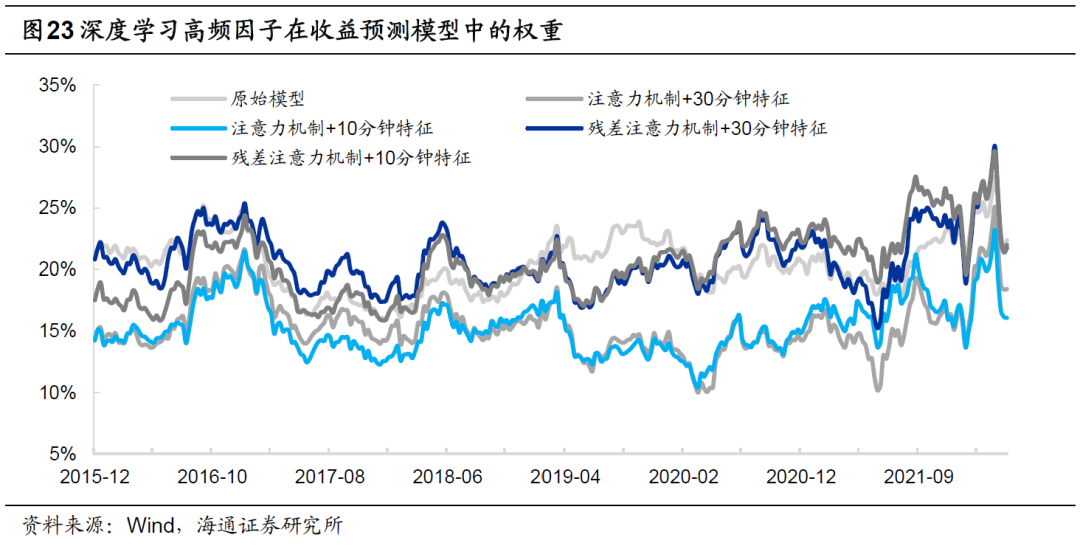
简单分析发现,2019年超额收益下降的原因是,引入简单注意力机制后,深度学习高频因子的IC降低,使其在以因子动量赋权的多因子模型中,权重低于原始因子,从而降低了对收益的贡献。使用残差注意力机制模型生成的因子代替后,权重大体接近于原始因子,故而增强组合的超额收益得到了进一步优化。
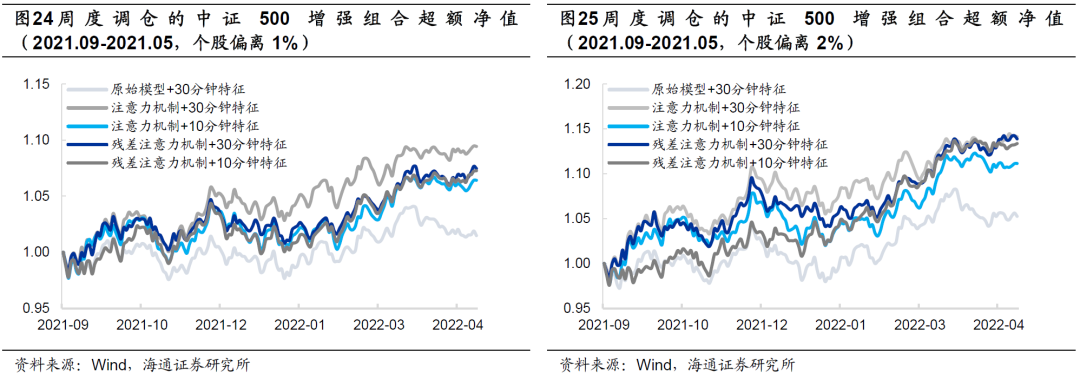
和单因子的结果类似,2021年9月以来,使用简单或残差注意力机制生成的深度学习高频因子的中证500增强组合有着更好的超额收益表现。
在前期报告中,基于30分钟的高频指标序列,我们使用RNN+NN的模型架构训练生成的深度学习高频因子具有突出的周度选股能力。然而,当输入特征的频率缩短至10分钟,即序列长度大幅增加时,GRU和LSTM生成的因子选股效果反而出现了下降。我们认为,原因可能是这两个模型在处理较长的序列时,产生了信息“遗忘”的问题。因此,本文在原来的训练过程中,引入注意力机制对RNN每一期输出的隐含状态进行第二次信息提取,再输入后续模型,而非简单地使用最后一期的隐含状态。
回测结果表明,当输入特征的频率较高、序列较长时,引入注意力机制可以优化因子的多头年化超额收益。更为值得一提的是,因子2020年至今的表现有着较为显著的提升,2021.09-2022.01期间的回撤大幅减小,净值创新高的速度也更快,在一定程度上改善了潜在的因子拥挤问题。此外,注意力机制的引入还大幅提高了因子的自相关性,使得多头组合的换手率明显下降,对实际应用更有价值。
但是,引入注意力机制后,因子2019年的表现出现了大幅下降,因此,我们进一步用残差注意力机制替换简单注意力机制,不仅保持了2020年以来的优异表现,而且大幅提升了2019年的多头超额收益,取得了较为完美的平衡。
将注意力机制模型生成的因子替换原深度学习高频因子,加入周度调仓的中证500指数增强模型,均能有效改进原模型2021年至今的超额收益。当个股偏离为2%时,全区间的年化超额收益也获得提升。











