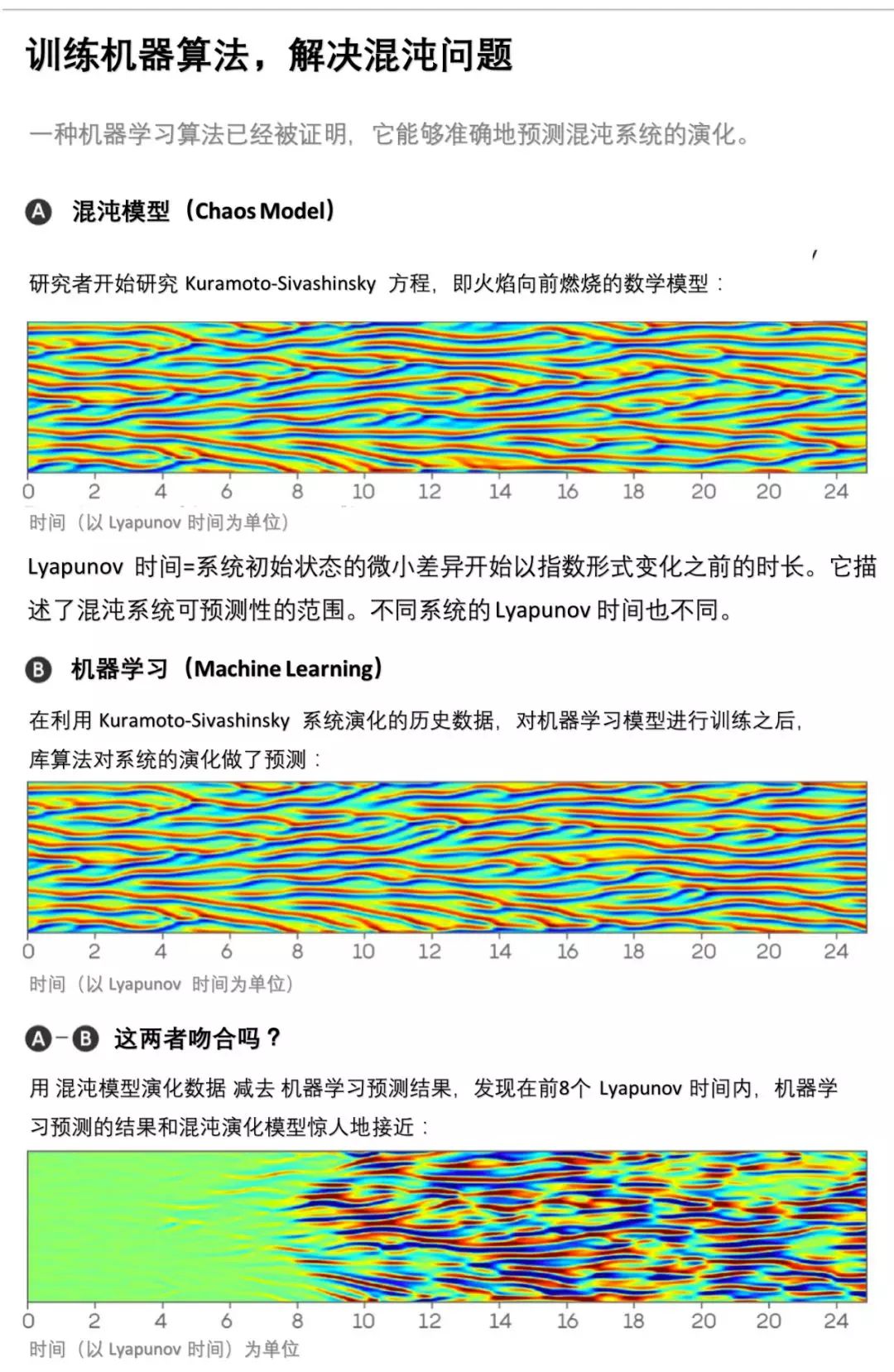
前不久,Quanta Magazine 报道了马里兰大学的研究者利用机器学习解决混沌系统的预测问题(参见集智俱乐部的译文下一秒火焰如何燃烧?机器学习成功预测混沌)。其中的一篇研究成果,题为《Model-Free Prediction of Large Spatiotemporally Chaotic Systems from Data: A Reservoir Computing Approach》,发表在了物理学顶级期刊 Physical Review Letters 上,下面是对论文的解读。
拉普拉斯曾断言:只要知道宇宙中每个原子确切的位置和动量,便能根据牛顿定律预测任何时刻的情况。这种思想被称为“决定论”。然而,20 世纪的两大发现彻底粉碎了这一梦想。海森堡测不准原理指出:一个粒子的位置和动量不可能同时精确确定。而混沌理论则指出了混沌系统的初值敏感性,也就是熟知的“蝴蝶效应”:初值的微小变化,会导致整个系统的长期的巨大的连锁反应。
这篇论文想解决的问题就是:如何预测大型时空混沌系统的演化?对一个动力学系统建立公式化的描述是困难的,但获得该系统长时间、高精度的观测数据却是容易的。我们自然希望机器能够从数据中学习到系统的演化规律,方便我们做预测。
一种机器学习预测算法
2. 方法:Reservoir Computing
储层计算
这篇论文中用到的方法称为 Reservoir Computing,Goodfellow 的《深度学习》中文版一书中将其翻译成“储层计算”。这里简单介绍一下 Reservoir Computing 的历史。
循环神经网络的训练是困难的,存在着计算量大、收敛慢、梯度消失等难点。为了克服上述难点,一种解决办法是:可以只初始化隐藏层而不去训练它,只去学习隐藏层到输出的权重,这样,问题就可以简化成一个回归问题。
基于上述想法,Jaeger 和 Maass 分别独立提出了 Echo State Network(回声状态网络)和 Liquid State Machine(流体状态机)。后来,这两种方法被统称为 Reservoir Computing。
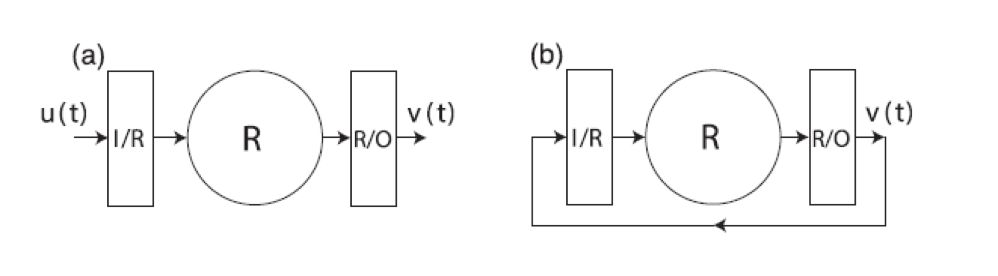
图 1: Reservoir computing 示意图。
(a)训练阶段;(b)预测阶段。
图片来源:
https://journals.aps.org/prl/abstract/10.1103/PhysRevLett.120.024102
下面介绍 Reservoir Computing。先介绍接下来需要用到的符号:对于时间序列 u,输入为 u 在 t 时刻的 Din 维向量 u(t),输出是 Dout 维向量 v(t),隐藏 层状态用 Dr 维向量 r(t) 表示。
输入为 u(t) 时,首先可以得到下一时刻(t + ∆t 时刻)隐藏层的状态:
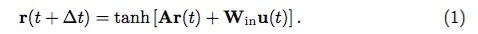
其中,Win 是一个 Dr × Din 维矩阵(矩阵元素从 [−σ, σ] 的均匀分布抽样),A 是隐藏层(reservoir)的邻接矩阵(Dr×Dr 维),且满足回声状态性质(简单地说, 就是网络当前时刻的状态 r(t) 由网络从初始到当前的输入唯一决定;数学上,满足矩阵 A 的谱半径 ρ 说明,可参考 The“echo state”approach to analysing and training recurrent neural networks –with an Erratum note)。
t + ∆t 时刻隐藏层的预测输出为:
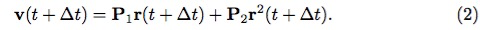
P1、P2 都是 Dout × Dr 维矩阵。由于 t + ∆t 时刻的真实值是时间序列中的 u(t + ∆t),因此训练的目标是找到合适的 P1、P2,使得 v(t + ∆t) 尽可能接近 u(t + ∆t) 。
在训练阶段,将 −T ≤ t ≤ 0 时间的 u(t) 依次输入网络,则损失函数可写作:
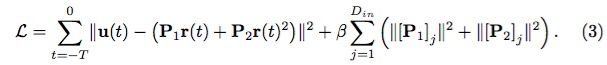
等号右边第一项为正常的损失函数项,第二项为正则项。
在算出 P1、P2 之后,就可以做预测了。在预测阶段,每一时刻的输入都是当前时刻的输出值,即 u(t) = v(t)。但由于混沌系统的指数分离特性(exponential separation of trajectories),很快 v(t) 就会彻底偏离真实的 u(t)。因此,当预测某一未来时刻 θ > 0 的状态,需要利用 θ 之前的一小段时间 (θ − ε ≤ t ≤ θ) 根据公式 (1) 重新初始化 r(θ),再去做预测。
利用上述方法,文章作者在一个叫做 Kuramoto-Sivashinsky(KS) 方程的时空混沌系统上小试牛刀。KS 方程为:
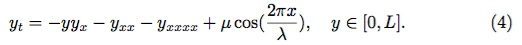
标准的 KS 方程无最后的空间不均项。方程满足周期边界条件 y(x, t) = y(x + L, t),方程的解由系统大小 L 和初始条件 y(x, 0) 决定。关于 KS 方程的详细介绍,可参考
Kuramoto-Sivashinsky: an investigation of spatiotemporal “turbulence”。
在一个 L = 22,格点数(输入向量维度)Q = 64,μ = 0 的系统上的预测结果如图(3)所示。(a)是真实数据,(b)是预测值,(c)是两者的误差。可以看到,在 6 个李雅普诺夫时间内,模型的预测与实际数据符合的相当好。
图 2: Kuramoto-Sivashinsky(KS) equation 的示意图。

图 3: L = 22 尺度的实验结果,
Q = 64,Dr = 5000,μ = 0。
图片来源:
https://journals.aps.org/prl/abstract/10.1103/PhysRevLett.120.024102
4. 如何处理大型时空混沌系统?
多个 reservoir 并行计算
对于上面 L = 22 的系统,隐藏层(reservoir)的大小已经达到了 Dr = 5000。对于更大空间尺度的系统而言,隐藏层的大小会急剧增加,此时再利用单个 reservoir 进行预测有点不切实际。这篇论文为的亮点便在于:提出了多个reservoir 并行处理的框架。
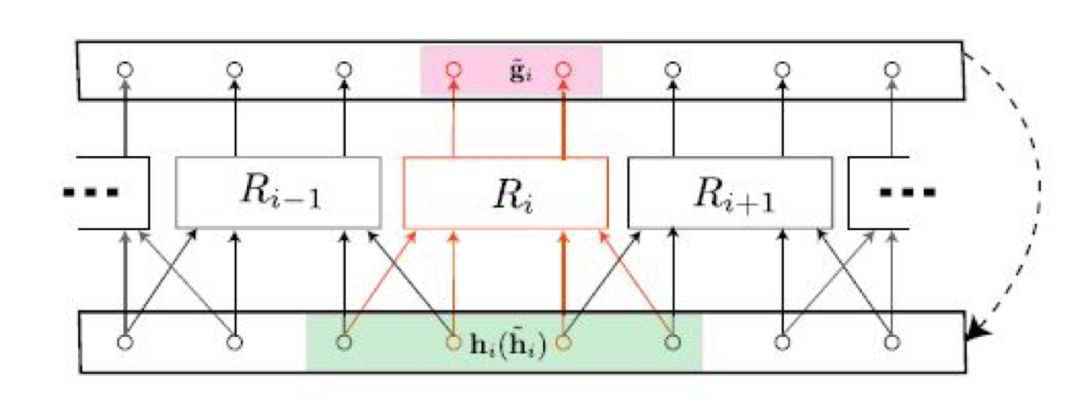
图 4: 多个 reservoir 并行处理示意图。
这里 q = 2,l = 1。
具体地,我们依然考虑空间格点数(输入向量维度)为 Q,但是将输入向 量 u(t) 按照维数平均分成 g 组,每组的维数是 q。
每组向量记为:


这样就相当于将原来的高维向量平均切分成 g 个低维向量。一个简单的并行处理的想法是:设置 g 个 reservoir,第 i 个 reservoir 的输入为:
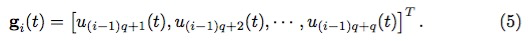
这样可以实现 g 个 reservoir 的并行处理。然而,这样做只是单纯把一个大的混沌系统看做 g 个彼此独立的子系统。论文中的做法是:同样是设置 g 个 reservoir,输入不再是 gi(t),而是 gi(t) 加上和它左右相邻的 l 个点的值,即输入是一个q + 2l 维向量:
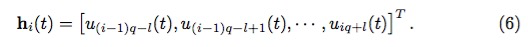
这样做的目的是为了尽可能利用到混沌系统的局部相互作用特性。
我们写出第 i 个 reservoir 的所有方程:
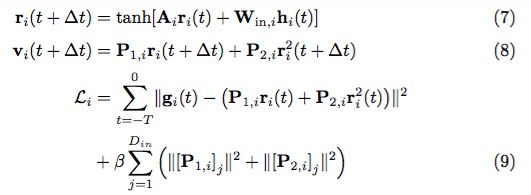
下面是 L = 200 的 KS 方程的预测结果。这里的参数设置为 Dr = 5000,T = 70000,ρ = 0.6,σ = 1.0,l = 6,并将需要预测的未来平均分成 K = 30 个时间间隔 θk ≤ t ≤ θk + τ ,τ = 1000 时间步。
预测阶段,在对每个时间间隔 θk ≤t≤θk +τ 的预测开始前,都需要初始化 ri =0,再利用 θk −ε≤t≤θk,ε = 10 时间步的数据,根据 式(7) 更新 ri 。预测结果如 图(5) 所示,(a)是真实数据,(b)是预测值,(c)是两者的误差,(d)是将 t = 0 时的预测值 y(x, 0) 作为初始条件的数值解和真实数据的误差。可以看到,图(c) 的结果只比 图(d) 差一点点,说明 reservoir computing 的方法能够很好的学到系统的真实动力学,其效果可以媲美数值方法。
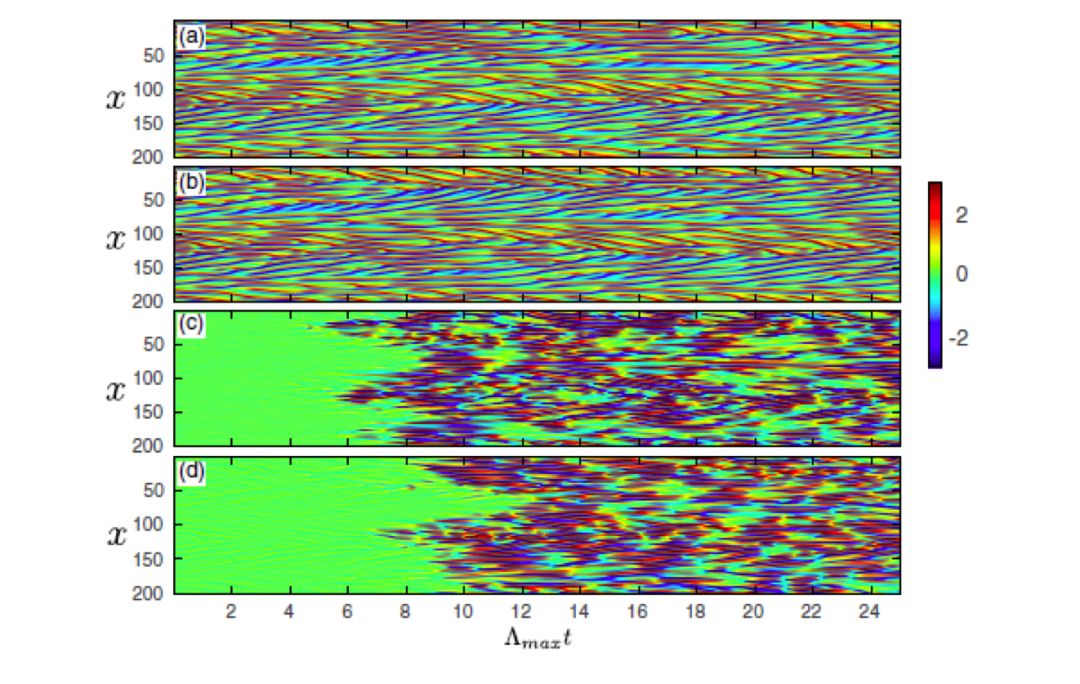
图 5: L = 200 尺度的实验结果,
Q = 512,Dr = 5000,μ = 0.01。
图片来源:
https://journals.aps.org/prl/abstract/10.1103/PhysRevLett.120.024102
一方面,这篇论文向我们展示了机器学习预测大型时空混沌系统的强大能力;另一方面,为何 Reservoir Computing 的效果如此之好,它的内部学习机制是什么,仍有待研究。
此外,通过前面的讲解不难发现,Reservoir Computing 本质上讲依然是传统的机器学习方法。那么,当下前沿的深度学习技术能否处理类似的混沌预测也是一个值得研究的问题。
作者:刘晶
审校:高飞
编辑:小风
论文地址:
https://journals.aps.org/prl/abstract/10.1103/PhysRevLett.120.024102
下一秒火焰如何燃烧?机器学习成功预测混沌
加入集智,一起复杂!集智俱乐部团队招新啦!

集智QQ群|292641157
商务合作|zhangqian@swarma.org
投稿转载|wangting@swarma.org
搜索公众号:集智俱乐部
加入“没有围墙的研究所”
让苹果砸得更猛烈些吧!