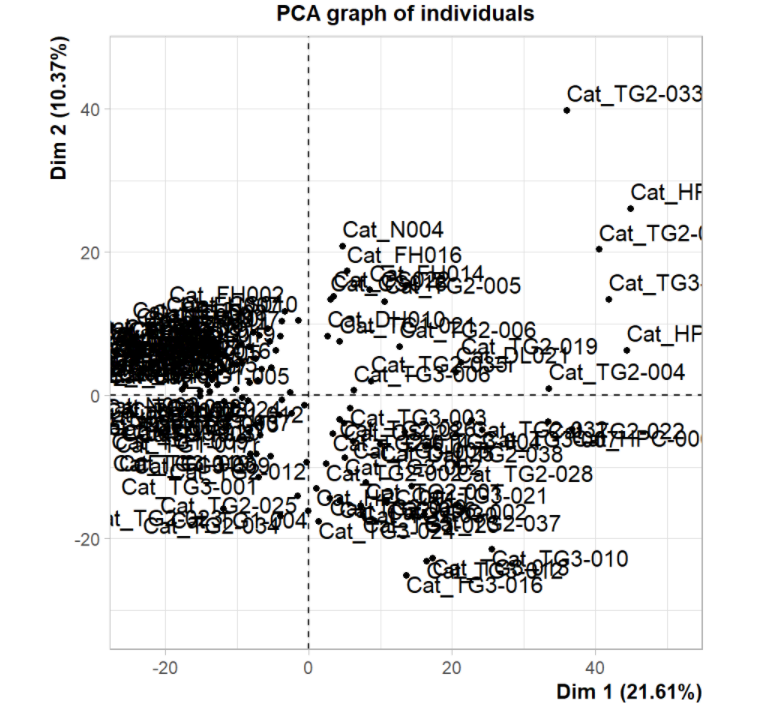
PCA(Principal Components Analysis)即主成分分析,也称主分量分析或主成分回归分析法,是一种无监督的数据降维方法。首先利用线性变换,将数据变换到一个新的坐标系统中;然后再利用降维的思想,使得任何数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上。其实,关键是减少数据集的维数,同时还保持数据集贡献最大的特征,最终使数据直观呈现在二维坐标系。(===图===)
PCA图一般是在分析前期用来探索不同样本间的关系。这里作者根据1000个最可变的蛋白质编码基因,将样本投影到二维坐标系。发现肿瘤与非肿瘤样本明显分离,而那些来自纤维化和肝硬化肝组织与正常样本接近。
文章来源:"Preoperative immune landscape predisposes adverse outcomes in hepatocellular carcinoma patients with liver transplantation" (2021,npj Precision Oncology),数据与代码全部公开在https://github.com/sangho1130/KOR_HCC。
现在来展示PCA图的绘制以及如何突出展示某一部分内容。
二、数据载入
参考资料:http://www.sthda.com/english/articles/31-principal-component-methods-in-r-practical-guide/112-pca-principal-component-analysis-essentials/
rm(list = ls())
library(FactoMineR)
library(ggplot2)
library(factoextra)
table data sep = '\t', check.names = FALSE, row.names = 1)
# 已经是挑选好了基因,并且转置的表达矩阵,适合做PCA分析
data[1:4,1:4]
# 将data$Grade信息提取出来做矩阵
dataGrade head(dataGrade)
# 删除Grade的信息,留下基因表达量
data$Grade unique(dataGrade$grade)
# 排好顺序
dataGrade$grade = factor(dataGrade$grade, c("Normal", 'FL', 'FH', 'CS', 'DL', 'DH', 'T1', 'T2', 'T3-4', 'Mixed'))
三、PCA分析
data[1:4,1:4]
# 这个时候的pca图非常的原始,丑爆了
pca print(pca) # 主要输出这15个结果
# 每个变量对每个主成分的贡献程度保存在pca$var$contrib
contribution colnames(contribution) contribution head(contribution)
# write.table(contribution, '../results/Figure 1B PCA contribution.txt',
# row.names = F, col.names = T, quote = F, sep = '\t')
四、可视化
# 把坐标信息提取出来,再用ggplot2绘制
pcaScores colnames(pcaScores) pcaScores$Grade head(pcaScores)
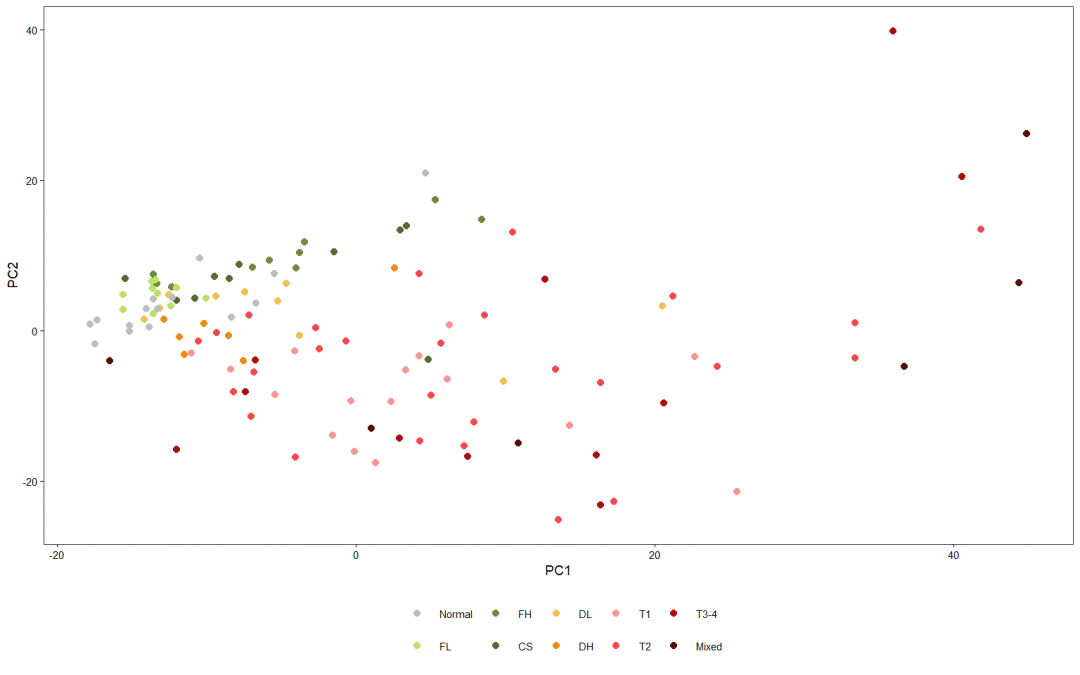
# 一般使用PC1,PC2就可以绘制出数据特征
# 绘图
plt geom_point(size = 1.5) +
scale_colour_manual(name='',
values = c("Normal" = "#bebdbd",
"FL" = "#bbe165", 'FH' = '#6e8a3c', 'CS' = '#546a2e',
"DL" = "#f1c055", 'DH' = '#eb8919',
"T1" = '#f69693', 'T2' = '#f7474e', 'T3-4' = '#aa0c0b', 'Mixed' = '#570a08')) +
theme_bw(base_size = 7) + #字体大小
theme(axis.text = element_text(colour = 'black'), # 轴刻度值
axis.ticks = element_line(colour = 'black'),# 轴刻度线
plot.title = element_text(hjust = 0.5), # 标题 hjust介于0,1之间,调节标题的横向位置
panel.grid = element_blank(), #空白背景
legend.position = 'bottom' ) #注释位置
plt
# # 本来是非常细小的点以及legend,但是 units = 'cm', width = 8, height = 6 就可以调整为适合浏览的
# ggsave('../results/Figure 1B.pdf', plt, units = 'cm', width = 8, height = 6)
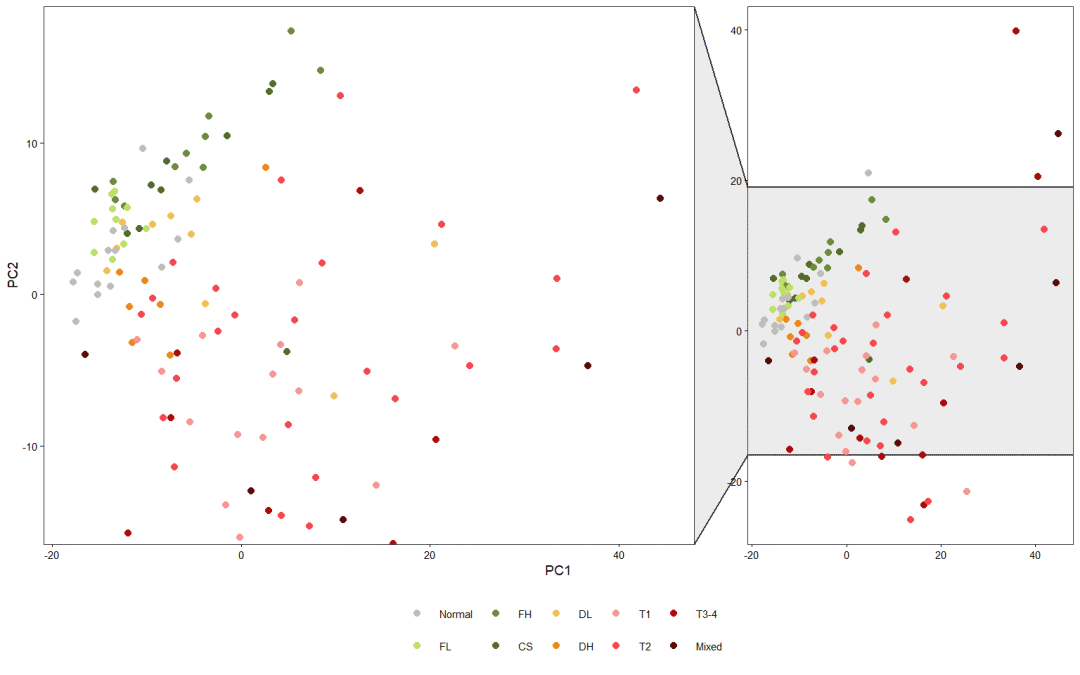
五、突出展示
如何突出展示图中内容呢?这里应该使用AI或者PS直接进行拼图。
我下面展示第二种方案:借助ggforce这个包里的facet_zoom()函数。不过还是原文有些出入,我还是很喜欢R语言+AI美化,这才是王道!
# install.packages("ggforce")
library(ggforce)
# 通过xy设置聚焦区域
plt+facet_zoom(y=pcaScores$PC2<20 & pcaScores$PC2> -15, split = F)
ggforce包是由Thomas Pedersen开发的ggplot2扩展包。它擅长根据数据绘制轮廓以及区域放大。有兴趣可以了解以下:https://rviews.rstudio.com/2019/09/19/intro-to-ggforce/
。实用性非常强,以后再来介绍这个包吧!
可以看到,这个本质上是散点图的PCA图仍然是不够美观,其实仅仅是因为分辨率问题,调整输出的pdf大小和像素即可






