Hi,大家好,我是晨曦
这期依旧是熟悉的机器学习内容,我们继续把我们树模型家族给补充完毕,同时在开篇也回答一下小伙伴的私信问题
A同学:曦曦,机器学习是不是Python会优于R呢,我们究竟应该如何选择呢?
晨曦:.........
晨曦碎碎念系列传送门
想白嫖单细胞生信文章?这五大源头数据库,是你发文章的源泉!高频预警!你一定要收藏!
盘活国自然的新思路!你研究的热点真的是热点吗?大数据帮你定位!
好家伙!90%以上审稿人都会问到的问题,今天帮你解决!就是这么齐齐整整!
没想到!生信分组还有这个大坑!你被坑过吗?!
关于富集分析这件事,我有话想说。。。
好御好高级!CNS级别美图是如何炼成的?看这篇就懂了!
化繁为简!一文帮你彻底搞懂机器学习!想发高分文章,这篇是基础!
你不知道的机器学习算法!关键时候能救命!
致命!芯片&测序的联合到底能不能联合分析?审稿人最爱用这刁难你!
躲不过的树!80%的生信SCI中都见过它!你真的搞懂了吗?
其实上面这个问题是一个很“引战”的问题,基本上说什么答案你都会被另一方予以反对,其实没有必要对此产生争论,在有限的精力掌握适合的工具晨曦觉得这就够了,大部分医学领域的生信人员都是有着临床工作或者实验室工作,在R上已经投入了大量的精力,晨曦觉得针对和晨曦处在相同领域的人犯不上再额外去学习另一门语言,不是那么语言不好,而是没有过多的精力。
那么,为什么说Python会比R更适合机器学习呢?
其实这个已经是老说法了,Python之所以适合机器学习,抛开语言本身,其实是有一个机器学习的库sk-learn,可以更加方便的让算法和算法之间得到切换或者,其包含了大量用于实现传统机器学习和数据挖掘任务的算法,比如数据降维、分类、回归、聚类、以及模型选择等,可以简单理解为相当于R语言一个包就囊括了所有算法和功能,这个在R语言上,严谨点说是以前的R语言上是很少见到的,正因为这一点,R语言实现机器学习,需要掌握很多R包,这个不光给学习造成难度,同时因为不同R包的参数还有输出数据类型的不同,导致你在把数据转到另一个R包上会产生错误,甚至于不同R包的接口不同,会让使用者记忆大量的参数。
但是,这个弊端在现在已经被优秀的R语言工程师解决了,两大集成式机器学习算法的R包诞生,可以帮助我们像Python一样解决机器学习的问题,分别是秉承着工作流的——tidymodels以及mlr包的升级版mlr3,这两款R包让R语言可以更加流畅的完成机器学习,以后的推文,在秉承原始代码的基础上,也会提供tidymodels的相关代码
如果各位小伙伴对于tidymodels包感兴趣,想要看到这个R包的相关教程,也欢迎在评论区留言哦~
Ps:评论多就写教程(手动狗头)~
好,我们就开始进行今天的正式内容
书接上回,决策树算法一般用于样本的分类,但是也可以用于数值变量的预测,用于数值变量预测的树模型我们起个全新的名字,分别是:1.回归树;2.模型树
1.回归树
回归树算法并不使用线性回归模型进行数值变量预测,而是在决策树算法的基础上,利用每个叶子节点所有样本的目标变量的均值进行数值变量预测
2.模型树
模型树也采用决策树算法进行分类,但在每个叶子节点建立一个线性回归模型,并以此进行数值变量预测
综上所述,模型树比回归树在结果的解读上可能会困难一点,但是也会产生一个更为准确的模型
然后我们看一下,模型树和回归树相比较于常用的线性回归方法有哪些优势,又有哪些缺点?
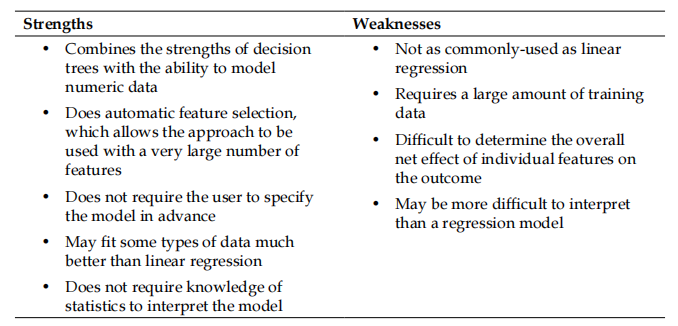
模型树和回归树的构建方法与决策树的构建方法基本是相同的
从根节点开始,根据特征,使用分割策略对数据进行分割,分割的好处是可以让分割后的数据同质性大大提高
在决策树中,同质性的衡量是通过信息熵来评估的,但是这个对于数值型数据是无法定义的,对于数值型数据,同质性可以通过诸如方差、标准差等统计数据来衡量,根据所使用的数算法不同,同质性测度的衡量标准可能会有不同,但是原理基本是相同的
粗略的概括一下:回归树本身又是一个大概念,根据如何划分数据又分为很多亚类,我们只需要掌握最常用的就可以,同时回归树和模型树具体通过什么方法划分,晨曦觉得这里我们了解个大概就可以,只需要知道一个通过目标变量的统计数据一个通过线性模型足矣~
接下来,我们通过一个实际的例子,来看一下如何构建回归树并使用回归树进行预测
这里我们就举一个具有生活气息的例子——酿酒

酒逢知己千杯少,再来一.......打住,跑题了,我们的例子并不是喝酒,而是酿酒酿酒行业是一个具有挑战性和竞争力的行业,咱们作为消费者,决定购买一款酒受到很多种因素的影响,比如说酒的口感、酒的颜色、包装的设计等等,但是各位重要的其实是酒本身,即使是酒的营销方式一样,从酒瓶的设计到价格再到本身等一系列因素都会影响到顾客
所以,我们下面这个案例,就来使用回归树和模型树来创建一个能够模拟品酒师对葡萄酒打分的模型,来探索哪一种因素可对葡萄酒打分更加重要,毕竟品酒师打分越高,酒本身的售价也越高,这是一个很直观的正相关

我们可以很清楚的看到,有11个特征以及一个终点结局打分
与其他类型的机器学习模型相比,树模型的优点之一是它们可以处理多种类型的数据,而不需要进行预处理。这意味着我们不需要规范化或标准化这些特性
尽管如此,我们依旧需要探索结局变量,以评估模型的性能。例如,假设葡萄酒的质量变化不大,或者葡萄酒属于双峰分布:要么很好,要么非常坏。这些情况可能会给我们的模型带来麻烦。为了检查这些极端情况,我们可以使用直方图来检查质量的分布,毕竟只有值得预测的数据才值得我们使用模型
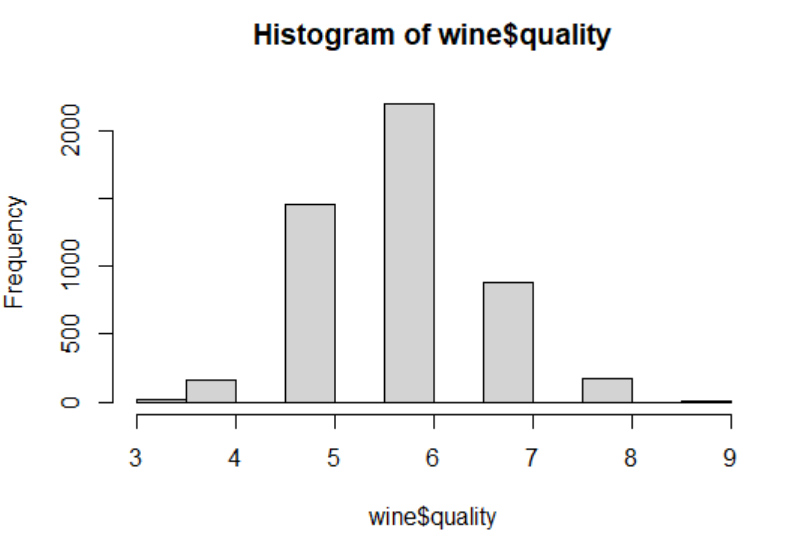
](https://imgtu.com/i/TX1IQx)
葡萄酒的打分值遵循一个相当正常的正态分布,以值6为中心。这在我们固有印象中是正常的,因为大多数葡萄酒的质量都是一般的;很少有特别坏或好。树模型本身对于缺失值和异常值有很好的处理能力,所以我们也方便我们不需要进一步探究
library(rpart)m.rpart data = wine_train)

对于回归树中的每个节点,列出了到达决策点的示例的数量。例如,所有3750个例子都从根节点开始,其中2372个有酒精<10.85,1378个有酒精>=10.85。因为酒精首先在回归树中使用,所以它是葡萄酒质量最重要的预测因素
*表示的节点是终点节点或叶节点,这意味着它们提供了一个预测结果。例如,节点5的为5.971091。当该树用于预测时,alcohol
然后接下来我们把树模型进行可视化
library(rpart.plot)rpart.plot(m.rpart, digits = 3)
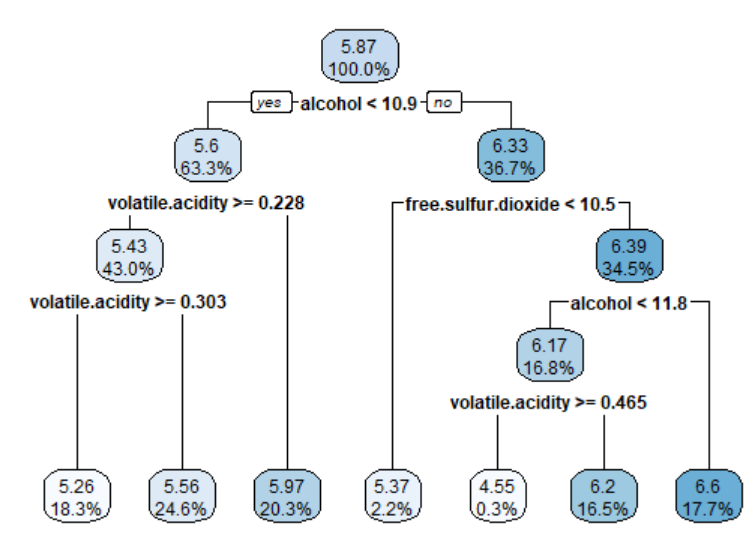
rpart.plot(m.rpart, digits = 4, fallen.leaves = TRUE,type = 3, extra = 101)
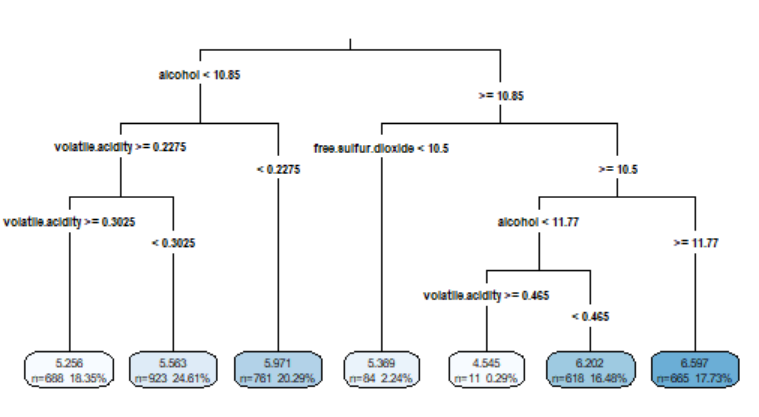
p.rpart summary(p.rpart)summary(wine_test$quality)
可以很直观的发现,我们预测的结果明显就偏窄,也就是预测的范围比真实值要小很多
这表明,该模型不能正确地识别极端情况,特别是最好和最差的葡萄酒。另一方面,在第一和第三个四分位数之间,我们可能做得很好
预测值和实际质量值之间的相关性为衡量模型的性能提供了一种简单的方法。回想一下,cor()函数可以用来测量两个等长向量之间的关系。我们将使用这个方法来比较预测值与真实值的对应程度
cor(p.rpart, wine_test$quality)
0.54的相关性当然是可以接受的。然而,这种相关性只能衡量预测与真实值的关联程度;它并不是用来衡量预测与真实值之间的距离
Ps:因为不是预测分类变量所以无法简单的运用正确率来衡量模型的正确性
另一种评估模型性能的方法是考虑它的预测平均与实际价值有多远。这种测量方法被称为平均绝对误差(MAE)
MAE的方程如下,其中n表示预测的次数,e表示预测的误差(了解即可,函数已经编辑好,到时候直接使用即可)
MAE function(actual, predicted) {mean(abs(actual - predicted)) }MAE(p.rpart, wine_test$quality)
这意味着,平均而言,我们的模型的预测和真实的质量分数之间的差异约为0.59。在从0到10的质量范围内,这似乎表明我们的模型做得相当好
接下来,我们要探索如何改进我们的模型
为了提高模型的表现,让我们尝试建立一个模型树
回想一下,模型树通过用回归模型替换叶节点算法来改进回归树。这通常比回归树产生更准确的结果,回归树只使用一个值对叶节点进行预测。目前最先进的模型树是由Wang和Witten提出的M5‘算法(M5-prime),它是对Quinlan在1992年提出的原始M5模型树算法的改进
library(RWeka)m.m5p data = wine_train)

m.m5p#结果很长默认只展示部分
可以很直观的看到,与我们之前构建的回归树非常相似。酒精是最重要的变量
然而,一个关键的区别是,节点的终点不是在一个数值预测中,而是在一个线性模型中(这里显示为LM1和LM2)
线性模型本身将在输出的后面显示。例如,LM1的模型如下
每个数字都是相关特征对预测的葡萄酒质量的净效应。fixed.acidity系数为0.266意味着增加1单位fixed.acidity,葡萄酒打分预计将增加0.266
需要注意的是,线性模型的预测结果只适用于到达这个节点的葡萄酒样品;在这个模型树中总共建立了36个线性模型,每个模型都对fixed.acidity和其他10个特征的影响进行了不同的估计
当然,我们也可以对模型树进行和回归树一样的评估
summary(m.m5p)#=== Summary ===#Correlation coefficient 0.6666#Mean absolute error 0.5151#Root mean squared error 0.6614#Relative absolute error 76.4921 %#Root relative squared error 74.6259 %#Total Number of Instances 3750p.m5p summary(p.m5p)# Min. 1st Qu. Median Mean 3rd Qu. Max. # 4.389 5.430 5.863 5.874 6.305 7.437cor(p.m5p, wine_test$quality)#[1] 0.6272973MAE(wine_test$quality, p.m5p)#[1] 0.5463023
至此,三类树即决策树、回归树、模型树就给大家介绍到了这里,我们先小小的总结一下
首先这三类模型都属于树模型,树模型本身具有的性质它们都有,包括
1.易于理解和解释,可视化理解清晰,容易提取出规则
2.可以同时处理缺失值、数值型、不相关数据等等,所以意味着我们不需要对数据进行预处理
3. 测试数据集时候,运行速度算是比较快的
其中决策树应用在终点结局为分类变量的情况下,回归树和模型树应用在终点结局为数值型变量的情况下
至于各个的优缺点在推文中都提到过,掌握输入数据的要求最起码可以完成模型的生成,更多细节推文中写的很清楚了~
然后接下来,我们来感受一下工作流下回归树的生成
#tidymodels包_回归树#准备工作library(tidymodels)library(tidyverse)#读取数据df "whitewines.csv")#划分训练集和测试集df_split 0.7)#观察训练集数据df_split %>% analysis() %>% glimpse()
#提取训练集和测试集df_train df_test #拟合模型df_tree "regression",tree_depth = 5) %>% set_engine("rpart") %>% fit(quality ~ ., data = df_train)#预测predict(df_tree, df_test)#将预测结果添加到测试集上df_tree %>% predict(df_test) %>% bind_cols(df_test) %>% glimpse()#很直观的看到第一列是预测打分,最后一列为真实打分#Rows: 1,470#Columns: 13#$ .pred 6.179715, 6.179715, 6.558383, 6.558383, 5.92558~#$ `fixed acidity` 6.4, 7.7, 6.8, 5.5, 7.9, 8.2, 6.5, 6.2, 7.0, 5.~#$ `volatile acidity` 0.29, 0.44, 0.27, 0.29, 0.18, 0.23, 0.16, 0.28,~#$ `citric acid` 0.21, 0.24, 0.28, 0.30, 0.49, 0.29, 0.33, 0.33,~#$ `residual sugar` 9.65, 11.20, 7.80, 1.10, 5.20, 1.80, 4.80, 1.70~#$ chlorides 0.041, 0.031, 0.038, 0.022, 0.051, 0.047, 0.043~#$ `free sulfur dioxide` 36, 41, 26, 20, 36, 47, 45, 24, 13, 20, 35, 32,~#$ `total sulfur dioxide` 119, 167, 89, 110, 157, 187, 114, 111, 91, 155,~#$ density 0.99334, 0.99480, 0.99150, 0.98869, 0.99530, 0.~#$ pH 2.99, 3.12, 3.24, 3.34, 3.18, 3.13, 3.18, 3.24,~#$ sulphates 0.34, 0.43, 0.34, 0.38, 0.48, 0.50, 0.44, 0.50,~#$ alcohol 10.93333, 11.30000, 12.50000, 12.80000, 10.6000~#$ quality 6, 7, 6, 7, 6, 6, 6, 6, 5, 6, 5, 6, 7, 6, 7, 5,~
至此,本期推文到这里就结束啦~
如果大家对于tidymodels包感兴趣,欢迎在评论区留言哦~
Ps:留言多就考虑写个系统教程(疯狂暗示QAQ)
我是晨曦,我们下期再见~~~
晨曦单细胞笔记系列传送门
1. 首次揭秘!不做实验也能发10+SCI,CNS级别空间转录组套路全解析(附超详细代码!)
2. 过关神助!99%审稿人必问,多数据集联合分析,你注意到这点了吗?
3. 太猛了!万字长文单细胞分析全流程讲解,看完就能发文章!建议收藏!(附代码)
4. 秀儿!10+生信分析最大的难点在这里!30多种方法怎么选?今天帮你解决!
5. 图好看易上手!没有比它更适合小白入手的单细胞分析了!老实讲,这操作很sao!
6. 毕业救星!这个R包在高分文章常见,实用!好学!
7. 我就不信了,生信分析你能绕开这个问题!今天一次性帮你解决!
晨曦单细胞数据库系列传送门
1. 宝儿,5min掌握一个单细胞数据库,今年国自然就靠它了!(附视频)
2. 审稿人返修让我补单细胞数据咋办?这个神器帮大忙了!
3. 想白嫖、想高大上、想有高大上的SCI?这个单细胞数据库,你肯定用得上!(配视频)
4. What? 扎克伯格投资了这个数据库?炒概念?跨界生信?
5. 不同物种也能合并做生信?给你支个妙招,让数据起死回生!
6. 零成本装逼指南!单细胞时代,教你用单细胞数据库巧筛基因,做科研!
7. 大佬研发的单细胞数据库有多强? 别眼馋 CNS美图了!零基础的小白也能10分钟学会!
8. 纯生信发14分NC的单细胞测序文章,这个北大的发文套路,你可以试下!实在不行,拿来挖挖数据也行!
9. 如何最短时间极简白嫖单细胞分析?不只是肿瘤方向!十分钟教你学会!
10. 生信数据挖掘新风口!这个单细胞免疫数据库帮你一网打尽了!SCI的发文源头!

欢迎大家关注解螺旋生信频道-挑圈联靠公号~