“ 快速高效学会python的终极奥义:过、抄、仿、改、调、看、练、创、悟”
正文开始前,先碎碎念几句。
1、本文的数据分析和机器学习系列会分成很多讲,这块涉及到的包包非常多,从大家会在各种报导里看到的人脸识别到文本识别还有简单的数据挖掘,每一个研究内容都对应不同的包包和完全不同的理论体系,今天的文章介绍的是最基本的一个入门包包;
2、由于很多读者爸爸反映说不能翻墙然后单纯看公众号的内容可能没办法全部看懂,于是从youtube上扒下来了视频供大家使用,但是视频一个一个看完还是需要花比较长的时间的,后续我也会继续扒视频,丰富下前面讲的一些内容,这里的视频我都声明了转载,非常感谢data school的创始人的辛勤劳动~~
3、机器学习的内容汗牛充栋,入门只需要抄代码+调参,但是要学好很难,我也不是很专业,虽然确实是学这个的,但是实际经验有限,同时也是觉得对于金融数据这种高频数据来说,确实使用一些黑箱模型可能会有一些奇妙的效果出来,比如用图像识别模式识别来看股票的波段,还是有一些实用性的~
视频课程(从youtube上一个一个扒下来的)
机器学习入门
主要回答几个问题
什么是机器学习?
机器学习的两大类是什么?
机器学习的例子有哪些?
机器学习是如何“工作”的?
其实,总结下来,机器学习是一种数据处理手段,跟我们常用的一些模型差不多,但是大部分机器学习的模型是从大量的样本中获得数据的规律,然后机器自己去学习出一套适应的模型,用于预测或者分类某个结果~~
2、为机器学习设置Python:scikit learn和Jupyter
3、开始使用scikit学习著名的iris数据集
什么是著名的iris数据集,它与机器学习有什么关系?
如何将iris数据集加载到sciket learn中?
如何使用机器学习术语来描述数据集?
scikit learn对数据处理的四个关键要求是什么?
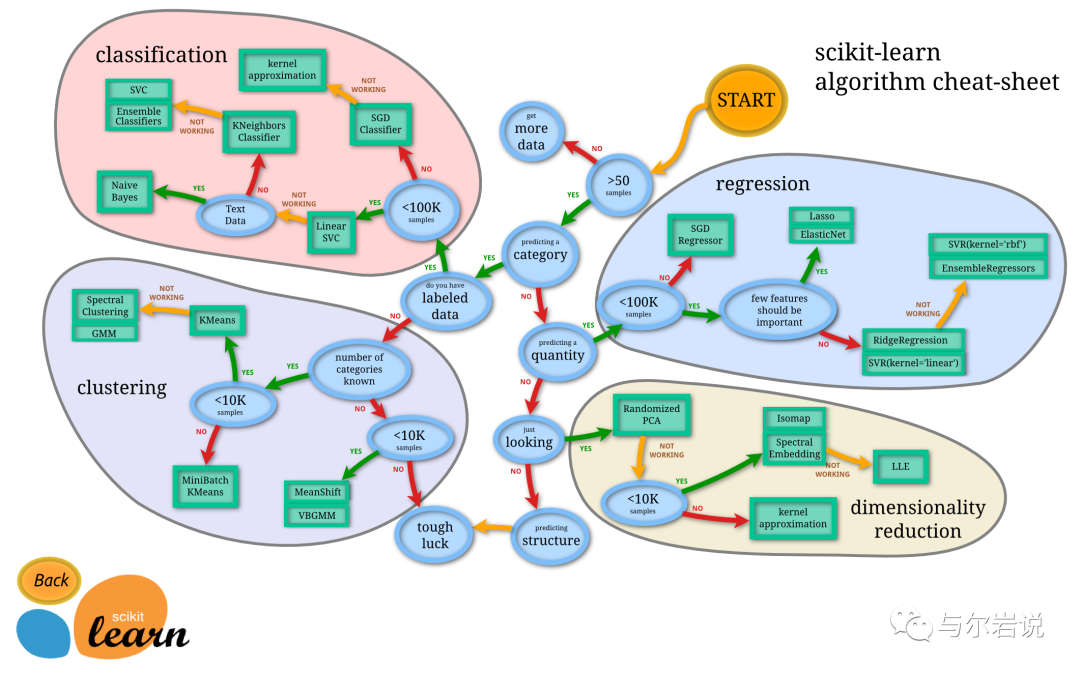
由图中,可以看到库的算法主要有四类:分类,回归,聚类,降维。其中:
常用的回归:线性、决策树、SVM、KNN ;集成回归:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
常用的分类:线性、决策树、SVM、KNN,朴素贝叶斯;集成分类:随机森林、Adaboost、GradientBoosting、Bagging、ExtraTrees
常用聚类:k均值(K-means)、层次聚类(Hierarchical clustering)、DBSCAN
常用降维:LinearDiscriminantAnalysis、PCA
4、使用sciket learn训练机器学习模型
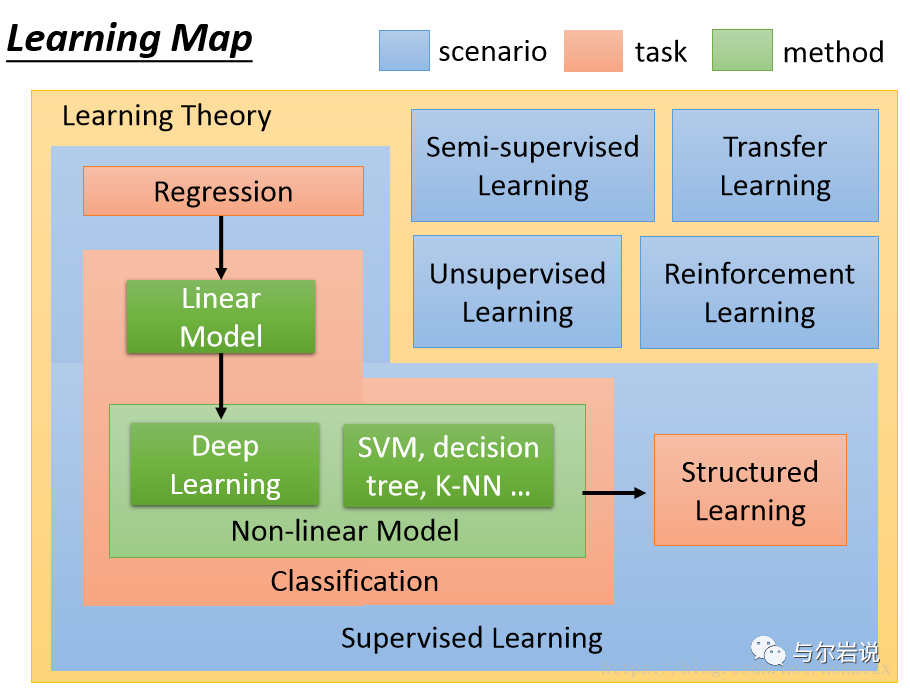
1、按任务类型分,机器学习模型可以分为回归模型、分类模型和结构化学习模型。回归模型又叫预测模型,输出是一个数值;分类模型又分为二分类模型和多分类模型,常见的二分类问题有垃圾邮件过滤,常见的多分类问题有文档自动归类;结构化学习模型的输出不再是一个固定长度的值,如图片语义分析,输出是图片的文字描述。
2、从方法的角度分,可以分为线性模型和非线性模型,线性模型较为简单,但作用不可忽视,线性模型是非线性模型的基础,很多非线性模型都是在线性模型的基础上变换而来的。非线性模型又可以分为传统机器学习模型,如SVM,KNN,决策树等,和深度学习模型。
3、按照学习理论分,机器学习模型可以分为有监督学习,半监督学习,无监督学习,迁移学习和强化学习。当训练样本带有标签时是有监督学习;训练样本部分有标签,部分无标签时是半监督学习;训练样本全部无标签时是无监督学习。
5、比较sciket learn中的机器学习模型
如何选择用于监督学习任务的模型?
如何为该模型选择最佳的调整参数?
如何在样本外数据上估计模型的可能性能?
6、数据分析全套组件:pandas seaborn scikit learn
7、参数调整、模型选择和功能选择的交叉验证
8、高效搜索最佳调谐参数
如何使用K-折叠交叉验证来搜索最佳调谐参数?
如何提高这一过程的效率?
如何一次搜索多个调优参数?
在做出真正的预测之前,您如何处理这些调整参数?
如何减少这个过程的计算开销?
全套代码下载:https://github.com/justmarkham/scikit-learn-videos
简单示例-波士顿房价预测
import matplotlib.pyplot as pltfrom sklearn import datasetsfrom sklearn.linear_model import LinearRegression
接着进行数据预处理,这在机器学习中是非常重要的一步。一般包含这几点:1.去除唯一属性;2.处理缺失值;3.特征编码;4.数据标准化;5.数据正则化;6.特征选择(降维)
loaded_data = datasets.load_boston()data_X = loaded_data.datadata_y = loaded_data.targetname_data = dataset.feature_names
接着,我们进行特征工程。特征工程真的很重要。如果特征工程做的好,不管是模型的建立或训练,还是最终的结果呈现,都是很好的。
for i in range(13): plt.subplot(7, 2, i+1) plt.scatter(x_data[:,i], y_data, s = 10) plt.title(name_data[i]) plt.show() print(name_data[i], np.corrcoef(x_data[:,i], y_data))
你会得到下面这样的不同特征与房价之间的特征图,你可以根据该图判断某一特征与房价之间的关系,并选择是否在后面建立模型的时候丢弃该特征。
经过上面散点图的分析,可以看到数据异常的变量需要特殊处理,根据散点图分析,房屋的’RM(每栋住宅的房间数)’,‘LSTAT(地区中有多少房东属于低收入人群)’,'PTRATIO(城镇中的教师学生比例)’特征与房价的相关性最大,所以,将其余不相关特征剔除。
i_ = []for i in range(len(y_data)): if y_data[i] == 50: i_.append(i) x_data = np.delete(x_data, [i], axis = 0) y_data = np.delete(y_data, [i], axis = 0) me_data = dataset.feature_namesj_ = []for i in range(13): if x_data[i] == 'RM' or 'PTRATIO' or 'LSTAT': continue j_.append(i) x_data = np.delete(x_data, j_, axis = 1) print(np.shape(y_data))print(np.shape(x_data))
然后将数据分割为训练集和测试集
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(x_data, y_data, random_state = 0, test_size = 0.20)print(len(X_train))print(len(X_test))print(len(y_train))print(len(y_test))
进行数据归一化
from sklearn import preprocessingmin_max_scaler = preprocessing.MinMaxScaler()X_train = min_max_scaler.fit_transform(X_train)X_test = min_max_scaler.fit_transform(X_test)y_train = min_max_scaler.fit_transform(y_train.reshape(-1,1)) y_test = min_max_scaler.fit_transform(y_test.reshape(-1,1))
线性回归
from sklearn import linear_modellr = linear_model.LinearRegression(fit_intercept=True, normalize=False)lr.fit(X_train, y_train)lr_y_predict = lr.predict(X_test)
from sklearn.metrics import r2_scorescore_lr = r2_score(y_test,lr_y_predict)
岭回归
from sklearn.linear_model import RidgeCVrr = RidgeCV(alphas=np.array([.1, .2, .3, .4]))rr.fit(X_train,y_train)rr_y_predict = rr.predict(X_test)
score_rr = r2_score(y_test,rr_y_predict)score_rr
LASSO回归
lassr = linear_model.Lasso(alpha=.0001)lassr.fit(X_train,y_train)lassr_y_predict=lassr.predict(X_test)
score_lassr = r2_score(y_test,lassr_y_predict)print(score_lassr)
SVR回归
from sklearn.svm import SVRsvr_rbf = SVR(kernel='rbf', C=100, gamma=0.1, epsilon=.1) svr_lin = SVR(kernel='linear', C=100, gamma='auto') svr_poly = SVR(kernel='poly', C=100, gamma='auto', degree=3, epsilon=.1, coef0=1) svr_rbf_y_predict=svr_rbf.fit(X_train, y_train).predict(X_test)score_svr_rbf = r2_score(y_test,svr_rbf_y_predict) svr_lin_y_predict=svr_lin.fit(X_train, y_train).predict(X_test)score_svr_lin = r2_score(y_test,svr_lin_y_predict) svr_poly_y_predict=svr_poly.fit(X_train, y_train).predict(X_test)score_svr_poly = r2_score(y_test,svr_poly_y_predict)
画图
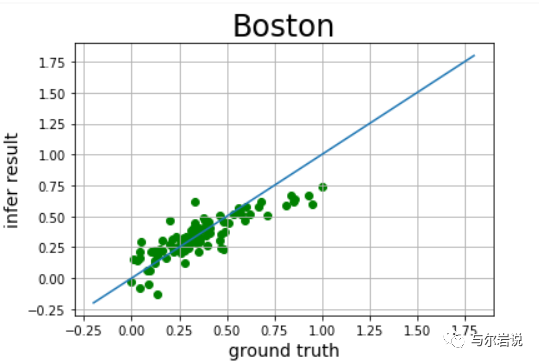
def draw_infer_result(groud_truths,infer_results): title='Boston' plt.title(title, fontsize=24) x = np.arange(-0.2,2) y = x plt.plot(x, y) plt.xlabel('ground truth', fontsize=14) plt.ylabel('infer result', fontsize=14) plt.scatter(groud_truths, infer_results,color='green',label='training cost') plt.grid() plt.show()