在进行机器学习时,我们往往要对数据进行聚类分析,聚类,说白了就是把相似的样品点/数据点进行归类,相似度高的样品点会放在一起,这样一个样本就会被分成几类。而聚类分析也有很多种方法,比如分解法、加入法、有序样品的聚类、模糊聚类法以及系统聚类法等。而本文要介绍的就是系统聚类法,以及如何用python来进行系统聚类分析。
首先来看一下系统聚类法的定义。系统聚类法(hierarchical clustering method),又叫分层聚类法,是目前最常用的聚类分析方法。其基本步骤如下:假设样本中有n个样品,那么就先将这n个样品看作n类,也就是一个样品一个类,然后将性质最接近的两类合并为一个新的类,这样就得到n-1个类,接着从中再找出最接近的两个类,让其进行合并,这样就变为n-2个类,让此过程持续进行下去,最后所有的样品都归为一类,把上述过程绘制成一张图,这个图就称为聚类图,从图中再决定分为多少类。其大致过程如图1所示。
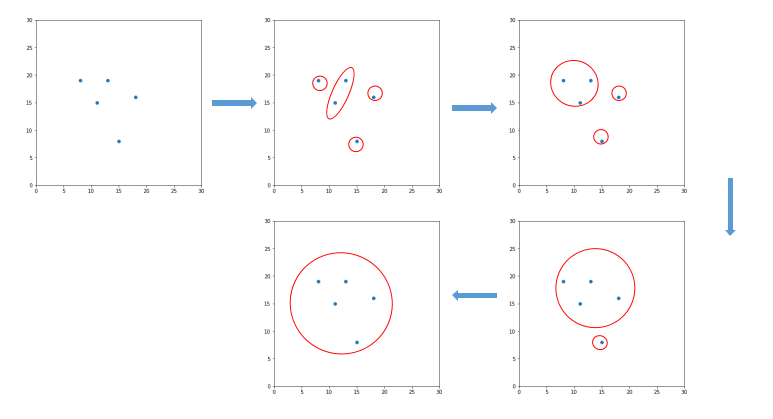
图1. 系统聚类分析示意图
而这里我们要确定各个样品的相似度,才能将其归类,那么如何确定其相似度呢?通常我们用的方法是计算各个样品点之间的距离,然后再根据距离来分类。这里我们根据距离来分类,同样也是有几种方法的,比如最短距离法、最长距离法、重心法、类平均法以及ward法。下面我们对这几种方法进行一个简单的介绍。
1. 最短距离法
最短距离法就是从两个类中找出距离最短的两个样品点,如图2所示。点3和点7是类G1和类G2中距离最短的两个点。计算公式如图4所示。
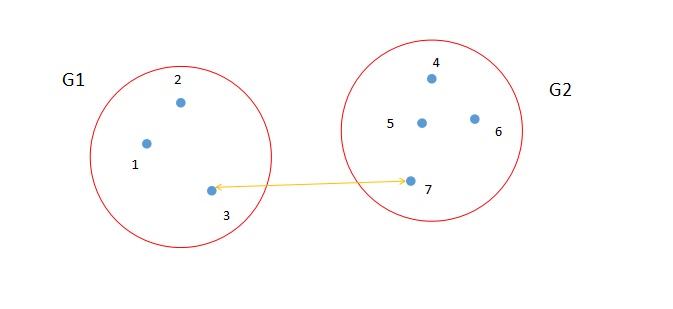
图2. 最短距离法示意图
2. 最长距离法
最长距离法就是从两个类中找出距离最长的两个样品点,如图3所示。点1和点6是类G1和类G2中距离最长的两个点。计算公式如图4所示。
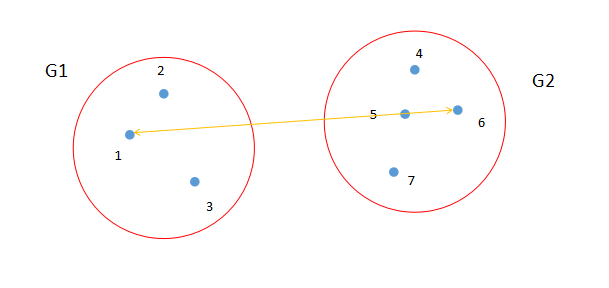
图3. 最长距离法示意图
3. 重心法
从物理的观点看,一个类用它的重心,也就是类样品的均值,来做代表比较合理,类之间的距离也就是重心之间的距离。若样品之间用欧氏距离,设某一步将类G1与G2合并成G3,它们各有n1、n2、n3个样品,其中n3=n1+n2,它们的重心用X1、X2和X3表示,则X3=1/n3(n1X1+n2X2)。重心法的计算公式参考图4。
4. 类平均法
这个顾名思义,就是取两个类之间所有点的距离的平均值。计算公式如图4所示。
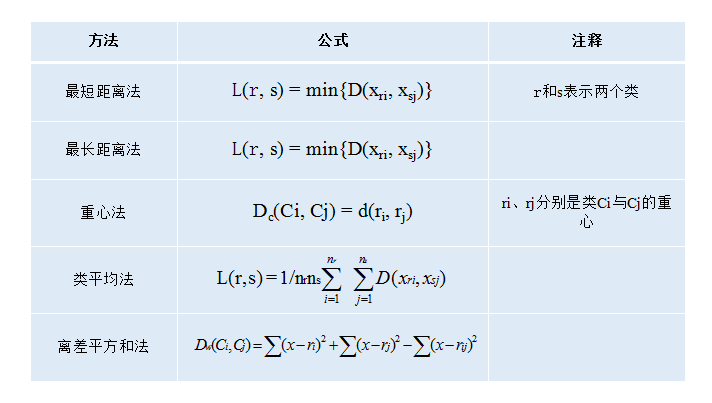
图4. 常用的距离计算方法
5. 离差平方和法
离差平方和法又叫Ward法,其思想源于方差分析,即如果类分得正确,同类样品的离差平方和应当较小,类与类之间的离差平方和应该较大。计算公式如图4所示。
在了解了系统聚类法的基本知识以后,我们就用python代码来展示一下系统聚类法的具体使用。
首先还是导入各种库。
import numpy as np
from matplotlib import pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
接下来是生成数据集。我们这次用的数据集是随机生成的,数量也不多,一共15个数据点,分为两个数据簇,一个有7个数据点,另一个有8个。之所以把数据点数量设置这么少,是因为便于看清数据分布,以及后面画图时容易看清图片的分类。代码如下。
state = np.random.RandomState(99) #设置随机状态
a = state.multivariate_normal([10, 10], [[1, 3], [3, 11]], size=7) #生成多元正态变量
b = state.multivariate_normal([-10, -10], [[1, 3], [3, 11]], size=8)
data = np.concatenate((a, b)) #把数据进行拼接
这里我们设置一个随机状态,便于重复试验。然后利用这个随机状态生成两个变量a和b,这两个变量就是前面说过的数据簇,a有7个数据点,b有8个,a和b都是多元正态变量,其中a的均值向量是[10, 10],b的均值向量是[-10, -10],两者协方差矩阵是[[1, 3], [3, 11]]。这里要注意的是协方差矩阵要是正定矩阵或半正定矩阵。然后对a与b进行拼接,得到变量data。
接下来要绘制数据点的分布。代码如下。
fig, ax = plt.subplots(figsize=(8,8)) #设置图片大小
ax.set_aspect('equal') #把两坐标轴的比例设为相等
plt.scatter(data[:,0], data[:,1])
plt.ylim([-30,30]) #设置Y轴数值范围
plt.xlim([-30,30])
plt.show()
这里代码比较简单,不再赘述,主要说一下ax.set_aspect('equal')这行代码,因为matplotlib默认情况下x轴和y轴的比例是不同的,也就是相同单位长度的线段,在显示时长度是不一样的,所以要把二者的比例设为一样,这样图片看起来更协调更准确。所绘制图片如图5所示,从图中可以明显看到两个数据簇,上面那个数据簇大概集中在坐标点[10, 10]附近,而下面那个大概集中在[-10, -10]附近,这和我们设置的是一样的。从图中可以很明显看出,这个数据集大概可以分为两类,即上面的数据簇分为一类,下面的数据簇分为另一类,但我们还要通过算法来计算一下。
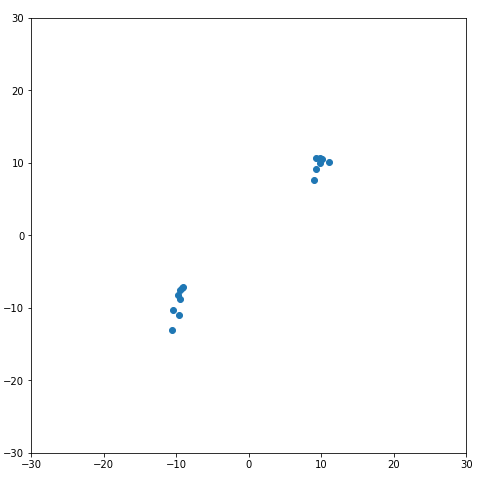
图5. 所用数据分布图
然后是数据处理,代码如下。
z = linkage(data, "average") #用average算法,即类平均法
数据处理只有这一行代码,非常简单,但难点也就在这。首先我们来看一下z的结果,如图6所示。

图6. 聚类计算结果
很多人第一次看到这个结果都是一脸懵逼,甚至是n脸懵逼,但其实里面的道理很简单。scipy官方对此有一些设定,比如该结果中第一行有4个数字,即11、13、0.14740505、2,前两个数字就是指“类”,刚开始每个点就是一个类,所以11和13这两个点就是两个类,第三个数字0.14740505就是这两个点的距离,这两个点被合并成一个类,所以这个新的类包含两个点(11和13),这也就是第四个点的数值2,而这个新的类就被算为类15。注意这里是类15,不是第15个类,因为我们原来的数据集中有15个点,按照顺序就是类0、类1、类2...类14,因为python是从0开始,所以这里类15就是指第16个类。z的第二行数据里,前两个数字是2和5,就是原来类2和类5,距离是0.3131184,包含2个点,这行数据和第一行类似。然后再看第三行数据,前两个数字是10和15,就是类10与类15,类15就是前面第一行合并成的新类,其包含11和13这两个点,类15与类10的距离是0.39165998,这个数字是类11和13与类10的平均距离,因为我们这里用的算法是average,类10、11和13合并为了一个新类,其包含3个点,所以第四个数字就是3。z中其他行的数据按照此规律以此类推。最后一行数据中,类26和27合并成一个新类,这个类包含了全部15个点,也就是这15个点最终划为了一个类,算法终止。
接下来就是画图,代码如下,其结果如图7所示。
fig, ax = plt.subplots(figsize=(8,8))
dendrogram(z, leaf_font_size=14) #画图
plt.title("Hierachial Clustering Dendrogram")
plt.xlabel("Cluster label")
plt.ylabel("Distance")
plt.axhline(y=10) #画一条分类线
plt.show()
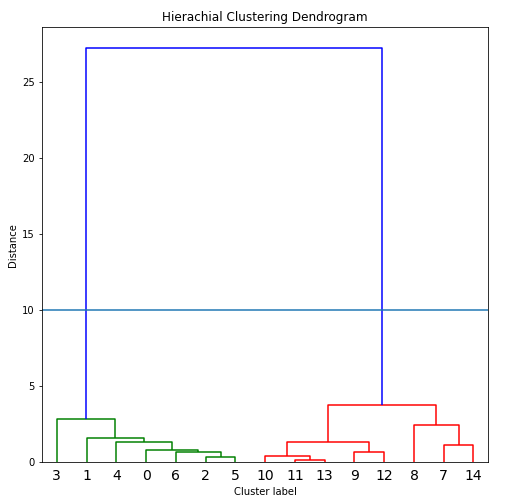
图7. 聚类结果图
从图中可以看出,这15个点可以分为两类,前面绿色的线连接的点代表一类,即点0到点6这7个点,后面红色的线连接的点代表第二类,即点7到点14这8个点。我们可以看到这个划分结果是非常正确的,和我们当时的设定是一样的。
系统聚类法的算法比较简单,实用性非常高,是目前使用最广泛的聚类方法,但该方法在处理极大数据量时会有所不足,所以最好配合其他算法来使用,同时使用者在使用时要根据自己的情况,来选择合适的距离计算方法。本文主要用类平均法来进行聚类操作,因为这个数据集非常简单,所以用其他距离计算方法得到的结果和这个是一样的。如果数据量比较大时,最终不同距离计算方法得到的结果可能不同,所以使用者要根据自己的情况来进行选择。








