
向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号: datayx
构建深度学习模型时,你必须做出许多看似随意的决定:应该堆叠多少层?每层应该 包含多少个单元或过滤器?激活应该使用 relu 还是其他函数?在某一层之后是否应该使用 BatchNormalization ?应该使用多大的 dropout 比率?还有很多。这些在架构层面的参数叫 作超参数(hyperparameter),以便将其与模型参数区分开来,后者通过反向传播进行训练。
在实践中,经验丰富的机器学习工程师和研究人员会培养出直觉,能够判断上述选择哪些 可行、哪些不可行。也就是说,他们学会了调节超参数的技巧。但是调节超参数并没有正式成 文的规则。如果你想要在某项任务上达到最佳性能,那么就不能满足于一个容易犯错的人随意 做出的选择。即使你拥有很好的直觉,最初的选择也几乎不可能是最优的。你可以手动调节你 的选择、重新训练模型,如此不停重复来改进你的选择,这也是机器学习工程师和研究人员大 部分时间都在做的事情。但是,整天调节超参数不应该是人类的工作,最好留给机器去做。
因此,你需要制定一个原则,系统性地自动探索可能的决策空间。你需要搜索架构空间, 并根据经验找到性能最佳的架构。这正是超参数自动优化领域的内容。这个领域是一个完整的 研究领域,而且很重要。
超参数优化的过程通常如下所示。
(1) 选择一组超参数(自动选择)。
(2) 构建相应的模型。
(3) 将模型在训练数据上拟合,并衡量其在验证数据上的最终性能。 (4) 选择要尝试的下一组超参数(自动选择)。
(5) 重复上述过程。
(6) 最后,衡量模型在测试数据上的性能。 这个过程的关键在于,给定许多组超参数,使用验证性能的历史来选择下一组需要评估的超参数的算法。
有多种不同的技术可供选择:贝叶斯优化、遗传算法、简单随机搜索等。 训练模型权重相对简单:在小批量数据上计算损失函数,然后用反向传播算法让权重向正确的方向移动。与此相反,更新超参数则非常具有挑战性。我们来考虑以下两点。
计算反馈信号(这组超参数在这个任务上是否得到了一个高性能的模型)的计算代价可能非常高,它需要在数据集上创建一个新模型并从头开始训练。
超参数空间通常由许多离散的决定组成,因而既不是连续的,也不是可微的。因此,你通常不能在超参数空间中做梯度下降。相反,你必须依赖不使用梯度的优化方法,而这些方法的效率比梯度下降要低很多。 这些挑战非常困难,而这个领域还很年轻,因此我们目前只能使用非常有限的工具来优化模型。通常情况下,随机搜索(随机选择需要评估的超参数,并重复这一过程)就是最好的 解决方案,虽然这也是最简单的解决方案。但我发现有一种工具确实比随机搜索更好,它就是 Hyperopt。它是一个用于超参数优化的 Python 库,其内部使用 Parzen 估计器的树来预测哪组超 参数可能会得到好的结果。另一个叫作 Hyperas 的库将 Hyperopt 与 Keras 模型集成在一起。
本文将介绍一种快速有效的方法用于实现机器学习模型的调参。有两种常用的调参方法:网格搜索和随机搜索。每一种都有自己的优点和缺点。网格搜索速度慢,但在搜索整个搜索空间方面效果很好,而随机搜索很快,但可能会错过搜索空间中的重要点。幸运的是,还有第三种选择:贝叶斯优化。本文我们将重点介绍贝叶斯优化的一个实现,一个名为hyperopt的 Python 模块。
使用贝叶斯优化进行调参可以让我们获得给定模型的最佳参数,例如逻辑回归模型。这也使我们能够执行最佳的模型选择。通常机器学习工程师或数据科学家将为少数模型(如决策树,支持向量机和 K 近邻)执行某种形式(网格搜索或随机搜索)的手动调参,然后比较准确率并选择最佳的一个来使用。该方法可能比较的是次优模型。也许数据科学家找到了决策树的最优参数,但却错过了 SVM 的最优参数。这意味着他们的模型比较是有缺陷的。如果 SVM 参数调整得很差,K 近邻可能每次都会击败 SVM。贝叶斯优化允许数据科学家找到所有模型的最佳参数,并因此比较最佳模型。这会得到更好的模型选择,因为你比较的是最佳的 k 近邻和最佳的决策树。只有这样你才能非常自信地进行模型选择,确保选择并使用的是实际最佳的模型。
本文涵盖的主题有:
目标函数
搜索空间
存储评估试验
可视化
经典数据集上的完整示例:Iris
要使用下面的代码,你必须安装hyperopt和pymongo
目标函数 - 一个启发性例子
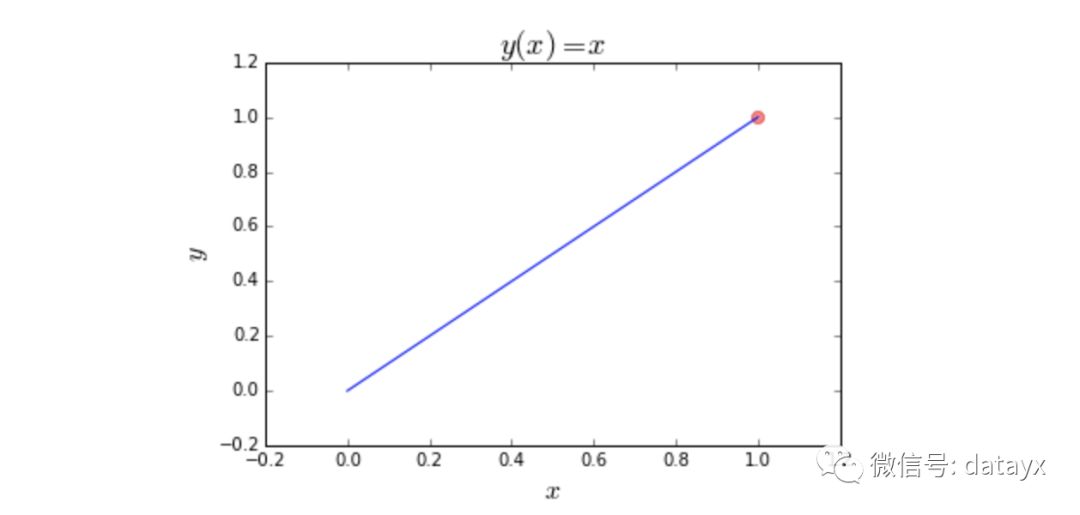
假设你有一个定义在某个范围内的函数,并且想把它最小化。也就是说,你想找到产生最低输出值的输入值。下面的简单例子找到x的值用于最小化线性函数y(x) = x
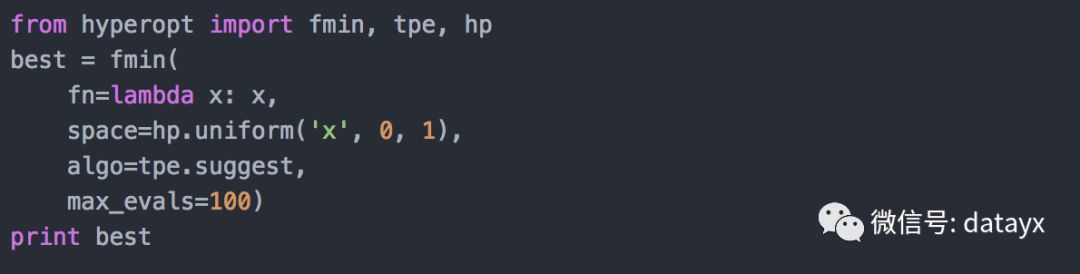
我们来分解一下这个例子。
函数fmin首先接受一个函数来最小化,记为fn,在这里用一个匿名函数lambda x: x来指定。该函数可以是任何有效的值返回函数,例如回归中的平均绝对误差。
下一个参数指定搜索空间,在本例中,它是0到1之间的连续数字范围,由hp.uniform('x', 0, 1)指定。hp.uniform是一个内置的hyperopt函数,它有三个参数:名称x,范围的下限和上限0和1。
algo参数指定搜索算法,本例中tpe表示 tree of Parzen estimators。algo参数也可以设置为hyperopt.random,但是这里我们没有涉及,因为它是众所周知的搜索策略。但在未来的文章中我们可能会涉及。
最后,我们指定fmin函数将执行的最大评估次数max_evals。这个fmin函数将返回一个python字典。
上述函数的一个输出示例是{'x': 0.000269455723739237}。
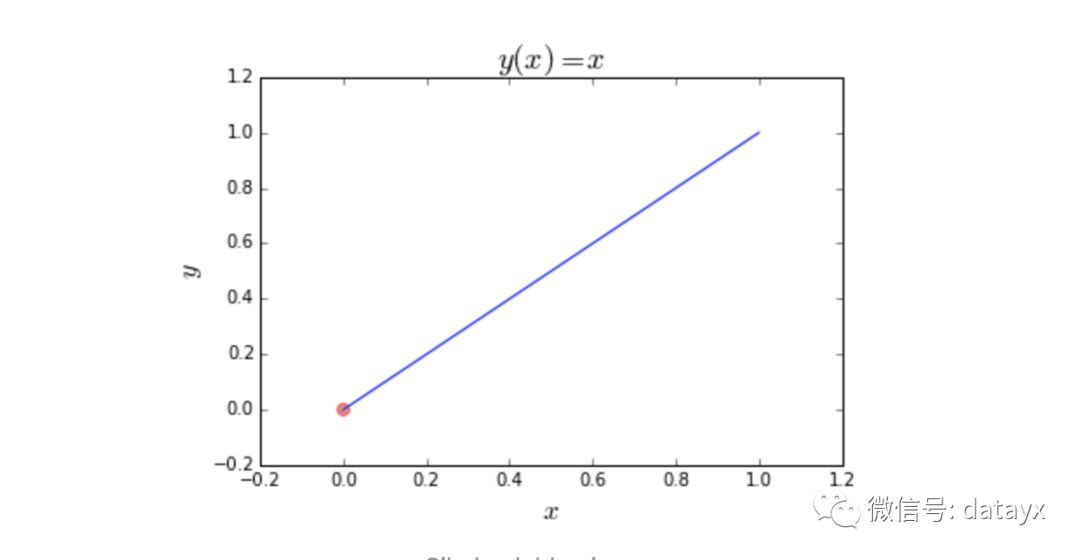
以下是该函数的图。红点是我们试图找到的点。
更复杂的例子
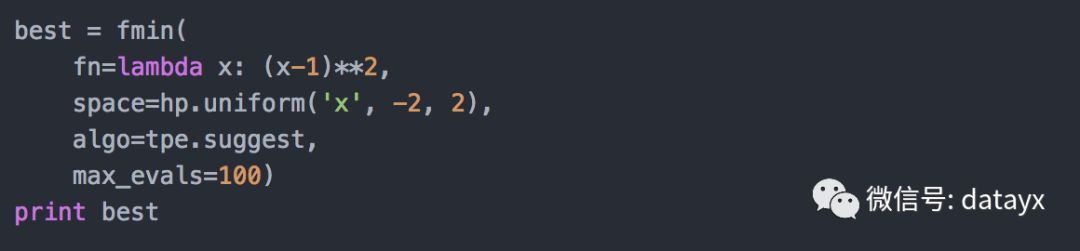
这有一个更复杂的目标函数:lambda x: (x-1)**2。这次我们试图最小化一个二次方程y(x)=(x-1)**2。所以我们改变搜索空间以包括我们已知的最优值(x=1)加上两边的一些次优范围:hp.uniform('x', -2, 2)。
现在我们有:
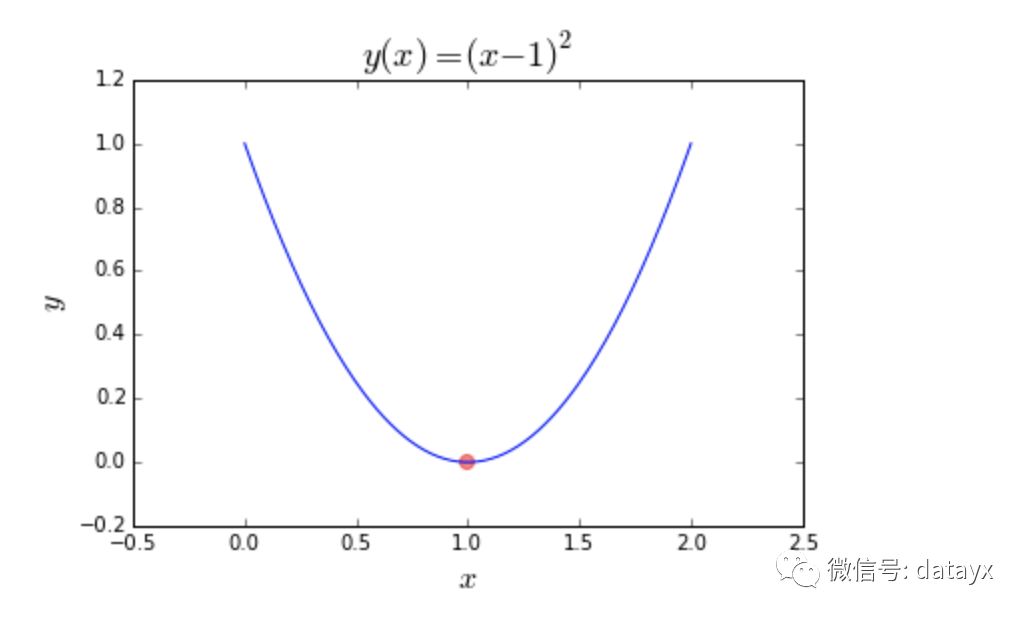
输出应该看起来像这样:

有时也许我们想要最大化目标函数,而不是最小化它。为此,我们只需要返回函数的负数。例如,我们有函数y(x) = -(x**2):

我们如何解决这个问题?我们采用目标函数lambda x: -(x**2)并返回负值,只需给出lambda x: -1*-(x**2)或者lambda x: (x**2)即可。
这里有一个和例子1类似,但我们不是最小化,而是试图最大化。
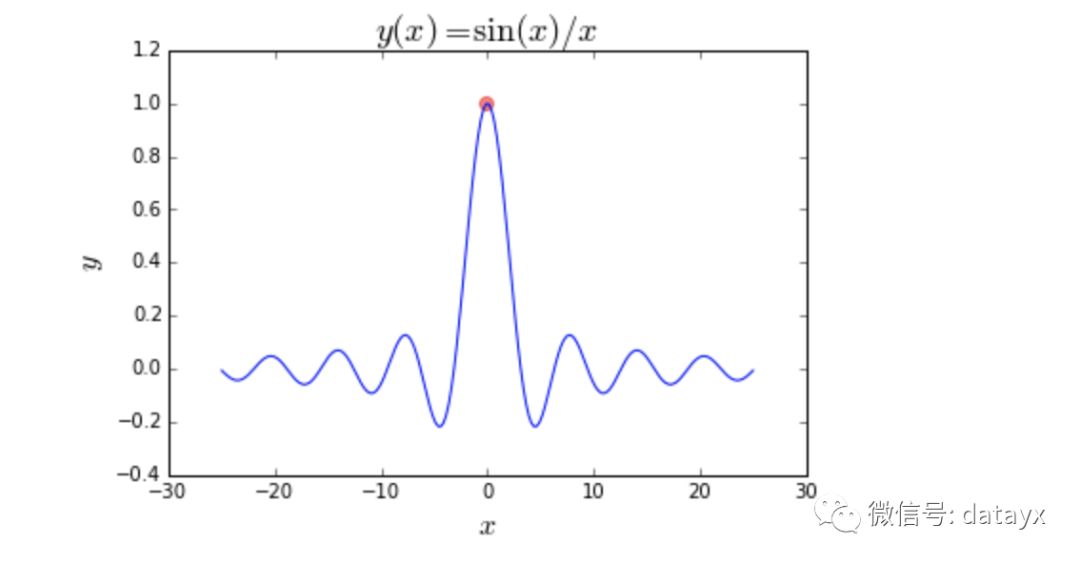
这里有许多(无限多且无限范围)局部最小值的函数,我们也试图将其最大化:
搜索空间
hyperopt模块包含一些方便的函数来指定输入参数的范围。我们已经见过hp.uniform。最初,这些是随机搜索空间,但随着hyperopt更多的学习(因为它从目标函数获得更多反馈),通过它认为提供给它最有意义的反馈,会调整并采样初始搜索空间的不同部分。
以下内容将在本文中使用:
hp.choice(label, options) 其中options应是 python 列表或元组。
hp.normal(label, mu, sigma) 其中mu和sigma分别是均值和标准差。
hp.uniform(label, low, high) 其中low和high是范围的下限和上限。
其他也是可用的,例如hp.normal,hp.lognormal,hp.quniform,但我们不会在这里使用它们。
为了查看搜索空间的一些例子,我们应该导入另一个函数,同时定义搜索空间。
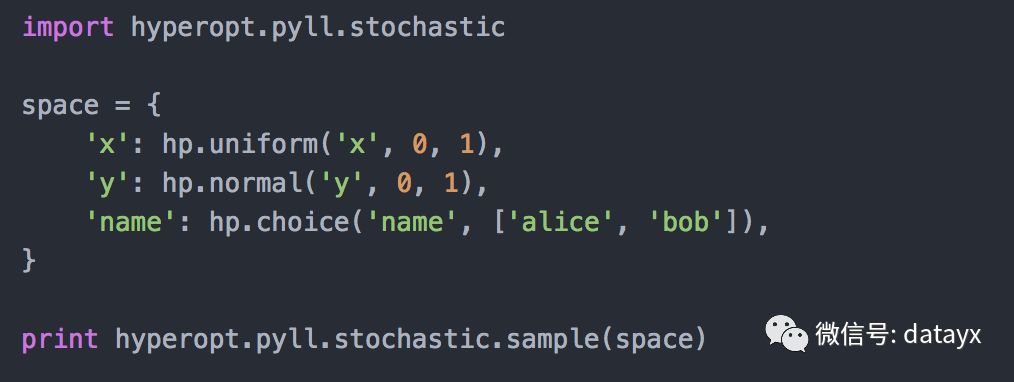
一个示例输出是:

尝试运行几次并查看不同的样本。
通过 Trials 捕获信息
如果能看到hyperopt黑匣子内发生了什么是极好的。Trials对象使我们能够做到这一点。我们只需要导入一些东西。
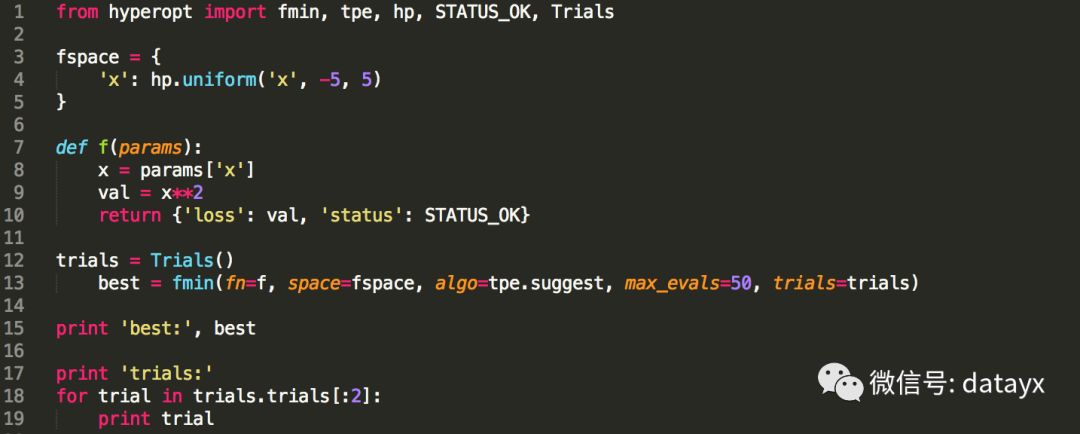
STATUS_OK和Trials是新导入的。Trials对象允许我们在每个时间步存储信息。然后我们可以将它们打印出来,并在给定的时间步查看给定参数的函数评估值。
这是上面代码的一个输出示例:

假设我们将`max_evals设为1000,输出应该如下所示。
[图片上传失败...(image-2f30d5-1524930959800)]
我们可以看到,最初算法从整个范围中均匀地选择值,但随着时间的推移以及参数对目标函数的影响了解越来越多,该算法越来越聚焦于它认为会取得最大收益的区域-一个接近零的范围。它仍然探索整个解空间,但频率有所下降。
现在让我们看看损失 vs. 值的图。
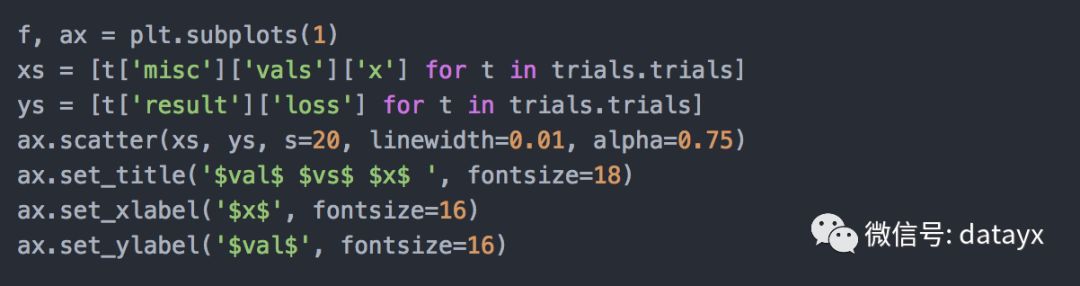
它给了我们所期望的,因为函数y(x)=x**2是确定的。
总结一下,让我们尝试一个更复杂的例子,伴随更多的随机性和更多的参数。
Iris 数据集
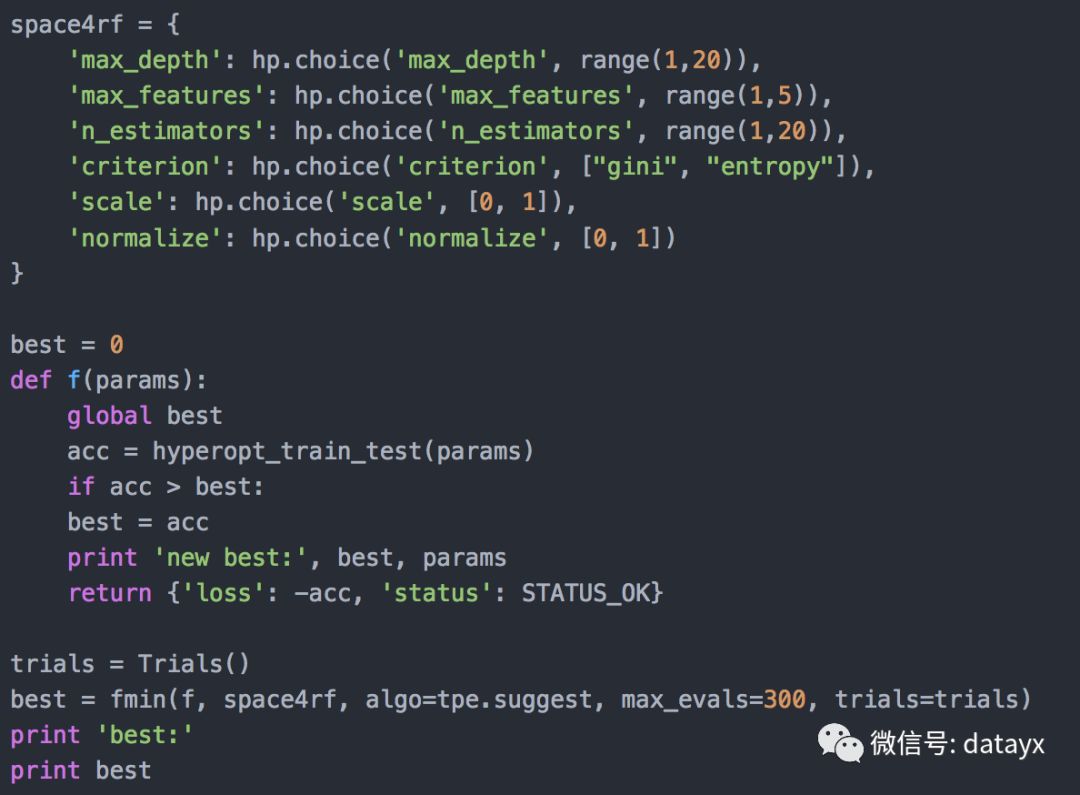
在本节中,我们将介绍4个使用hyperopt在经典数据集 Iris 上调参的完整示例。我们将涵盖 K 近邻(KNN),支持向量机(SVM),决策树和随机森林。需要注意的是,由于我们试图最大化交叉验证的准确率(acc请参见下面的代码),而hyperopt只知道如何最小化函数,所以必须对准确率取负。最小化函数f与最大化f的负数是相等的。
对于这项任务,我们将使用经典的Iris数据集,并进行一些有监督的机器学习。数据集有有4个输入特征和3个输出类别。数据被标记为属于类别0,1或2,其映射到不同种类的鸢尾花。输入有4列:萼片长度,萼片宽度,花瓣长度和花瓣宽度。输入的单位是厘米。我们将使用这4个特征来学习模型,预测三种输出类别之一。因为数据由sklearn提供,它有一个很好的DESCR属性,可以提供有关数据集的详细信息。尝试以下代码以获得更多细节信息。

让我们通过使用下面的代码可视化特征和类来更好地了解数据。如果你还没安装别忘了先执行pip install searborn。
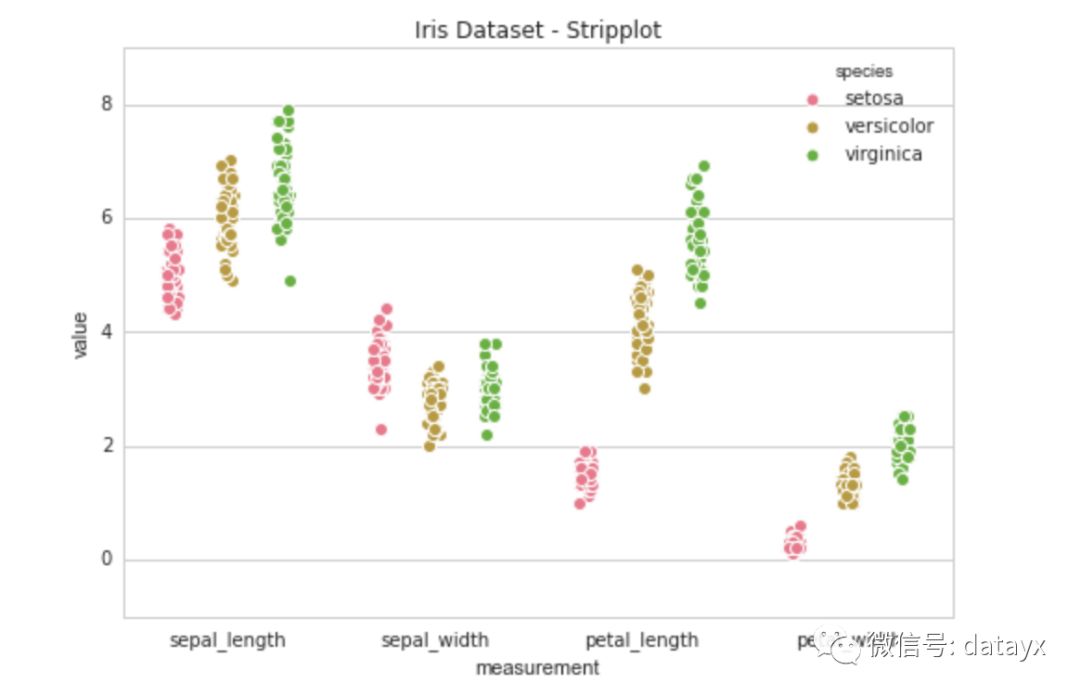
K 近邻
我们现在将使用hyperopt来找到 K近邻(KNN)机器学习模型的最佳参数。KNN 模型是基于训练数据集中 k 个最近数据点的大多数类别对来自测试集的数据点进行分类。关于这个算法的更多信息可以参考这里。下面的代码结合了我们所涵盖的一切。
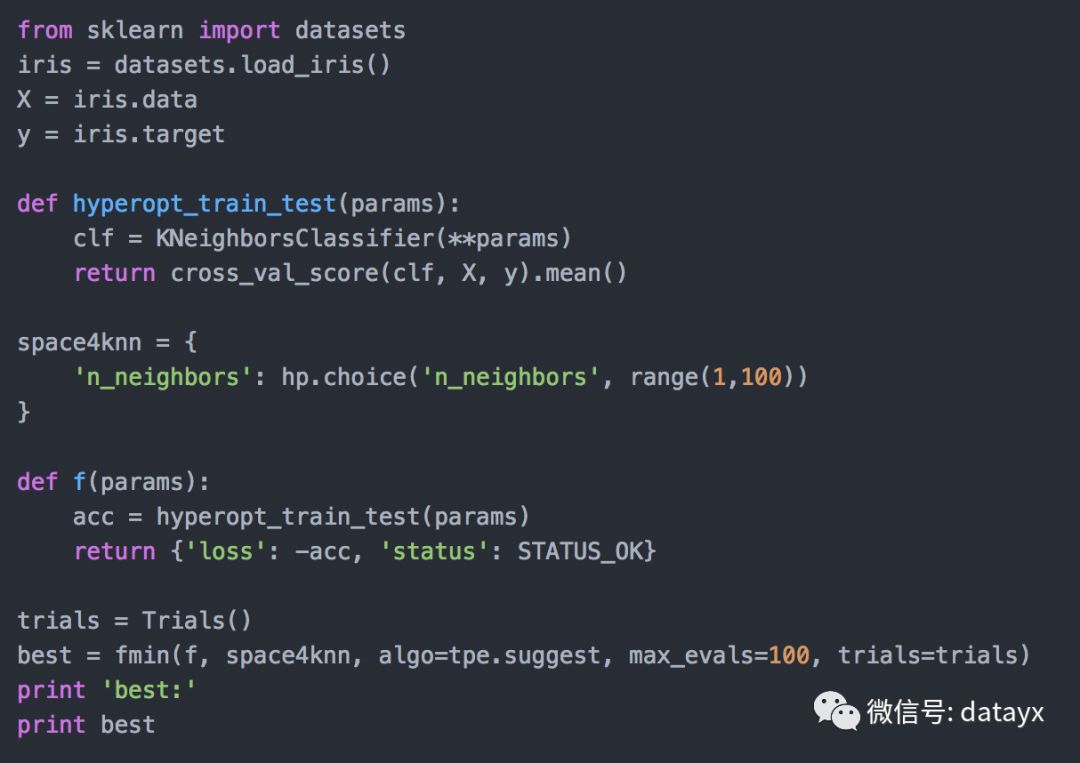
现在让我们看看输出结果的图。y轴是交叉验证分数,x轴是 k 近邻个数。下面是代码和它的图像:
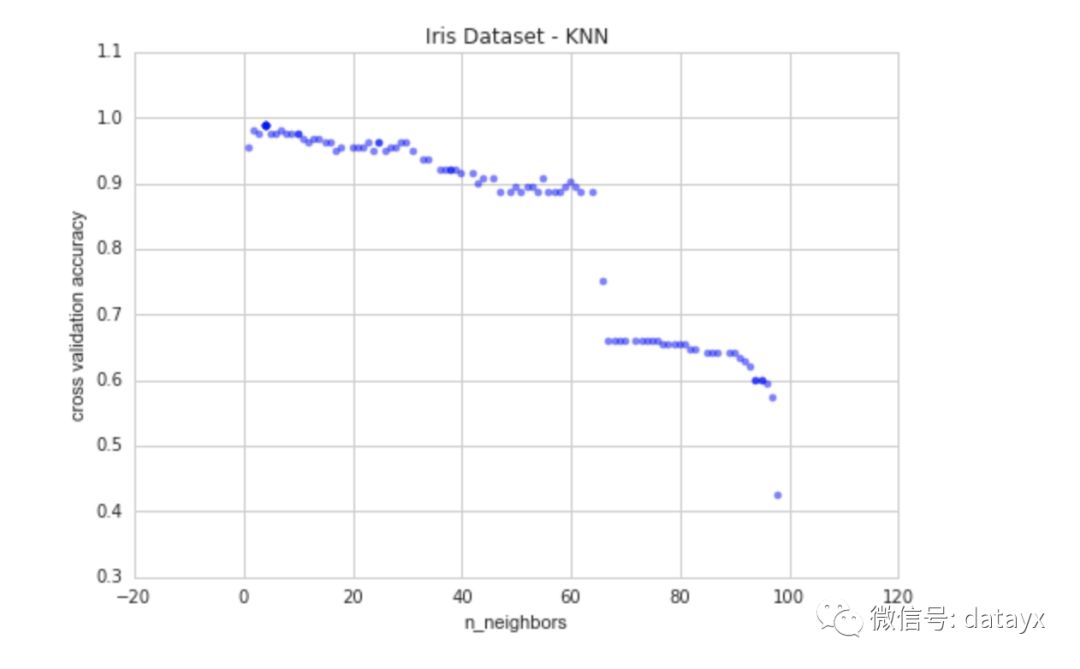
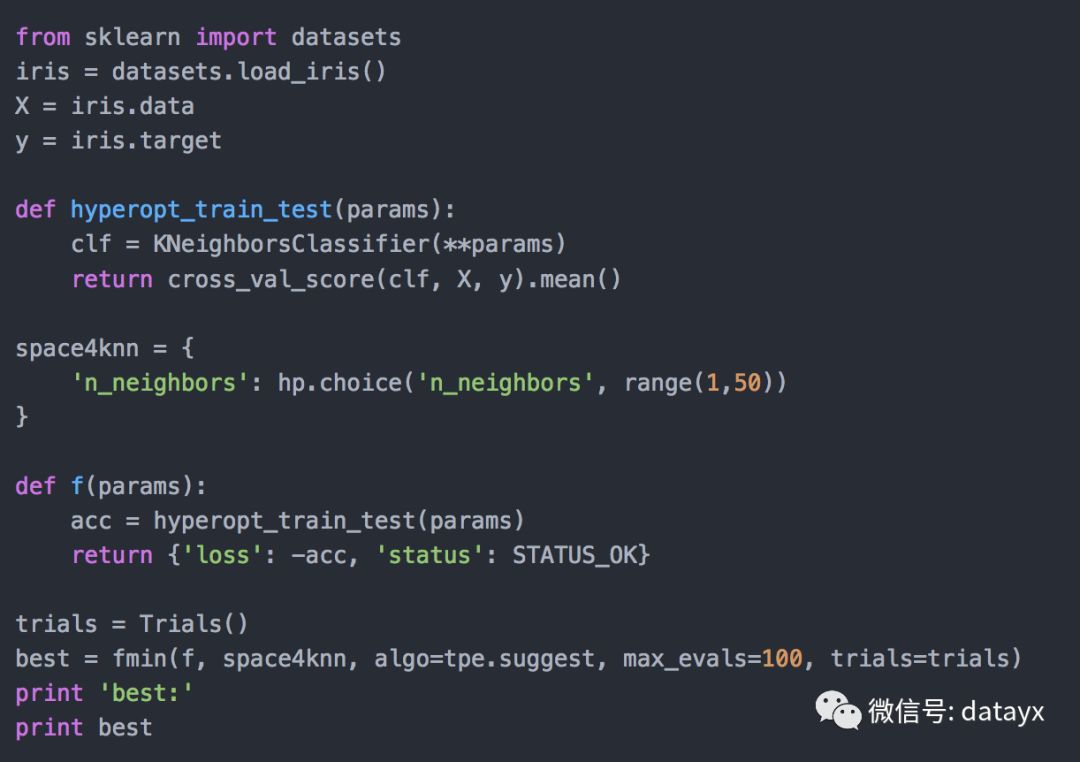
k大于63后,准确率急剧下降。这是因为数据集中每个类的数量。这三个类中每个类只有50个实例。所以让我们将'n_neighbors'的值限制为较小的值来进一步探索。
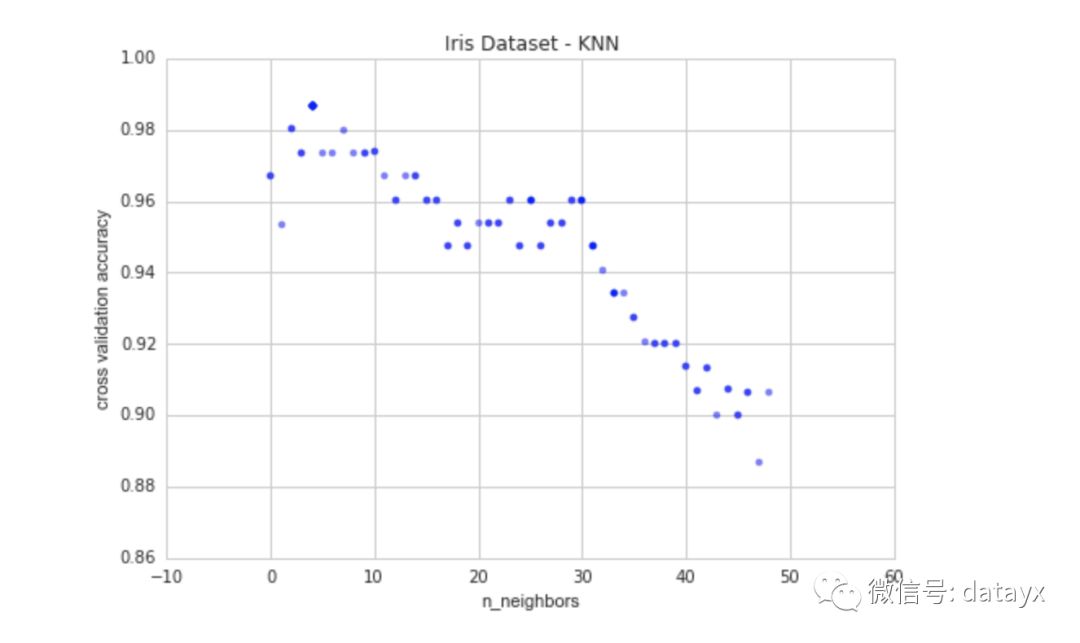
现在我们可以清楚地看到k有一个最佳值,k=4。
上面的模型没有做任何预处理。所以我们来归一化和缩放特征,看看是否有帮助。
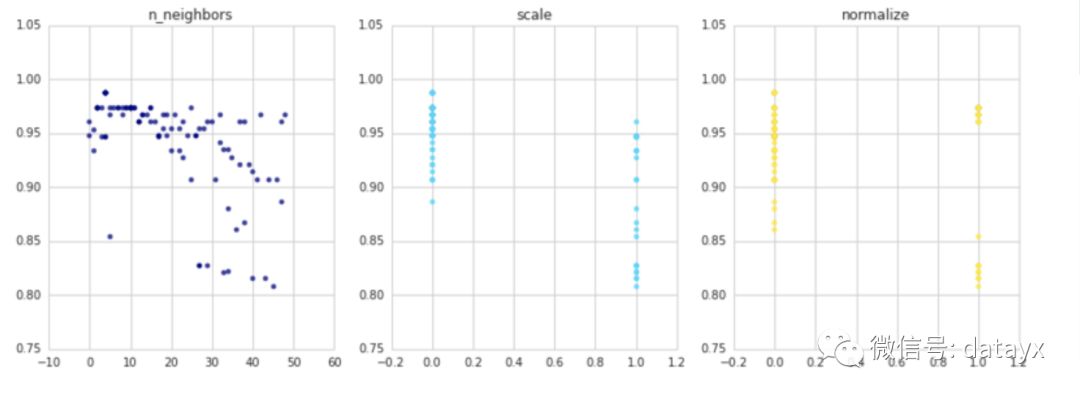
我们看到缩放和/或归一化数据并不会提高预测准确率。k的最佳值仍然为4,这得到98.6%的准确率。
所以这对于简单模型 KNN 调参很有用。让我们看看用支持向量机(SVM)能做什么。
支持向量机(SVM)
由于这是一个分类任务,我们将使用sklearn的SVC类。代码如下
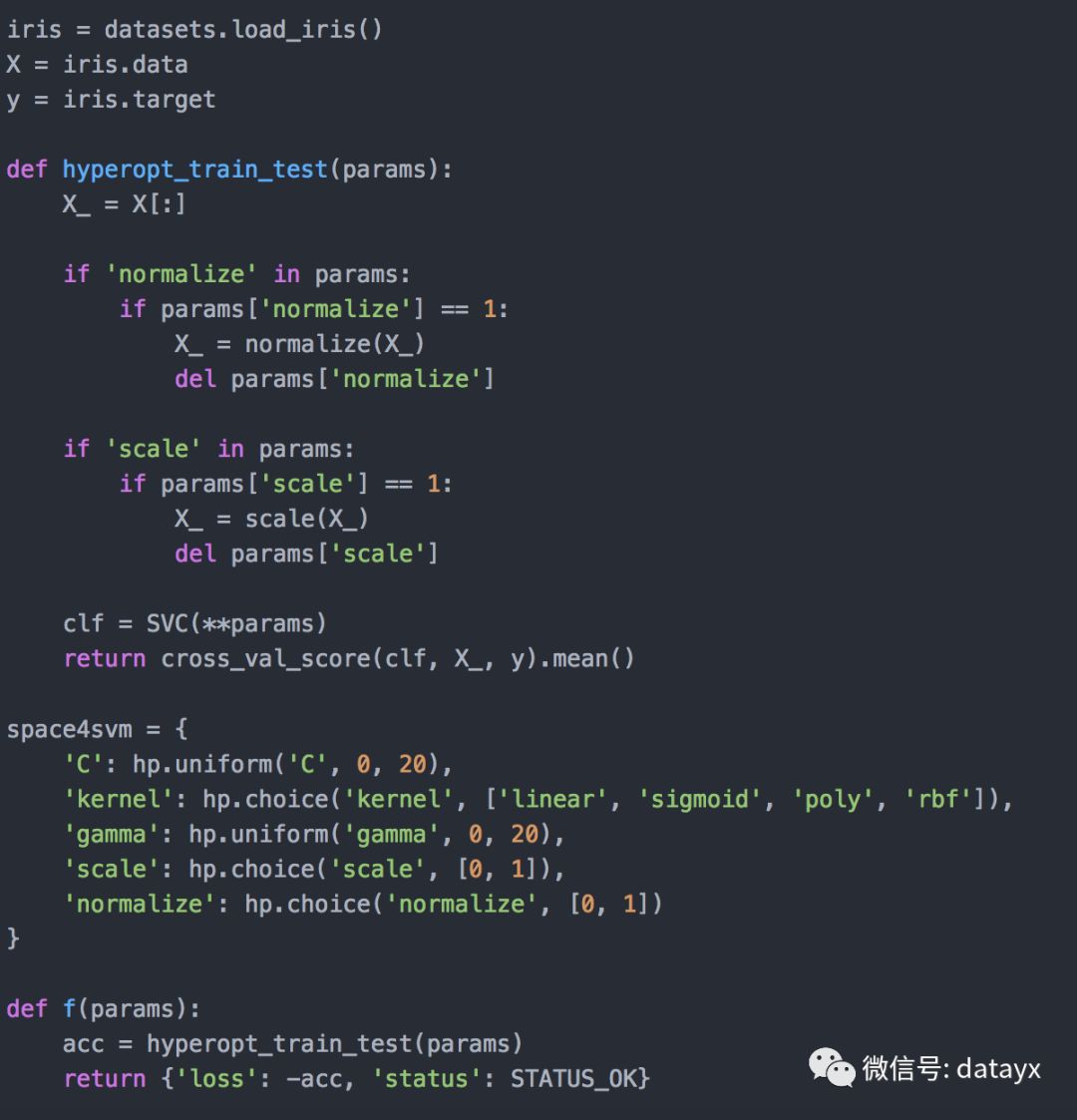
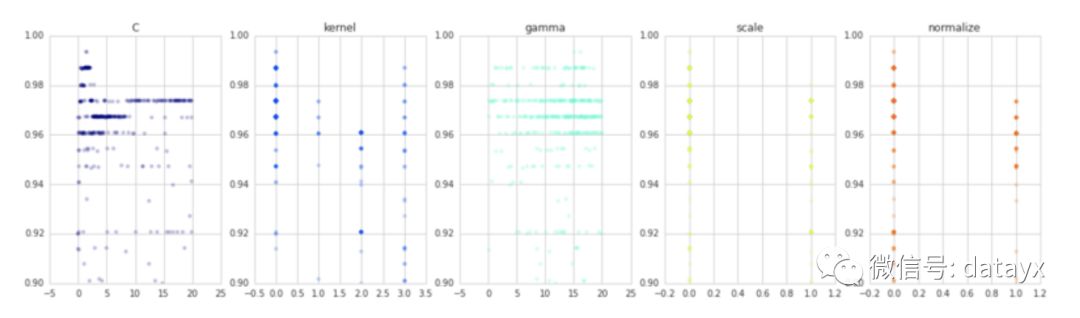
同样,缩放和归一化也没有帮助。核函数的首选是(linear),C的最佳值是1.4168540399911616,gamma的最佳值15.04230279483486。这组参数得到了99.3%的分类准确率。
随机森林
让我们来看看集成分类器随机森林发生了什么,随机森林只是在不同分区数据上训练的决策树集合,每个分区都对输出类进行投票,并将绝大多数类的选择为预测。
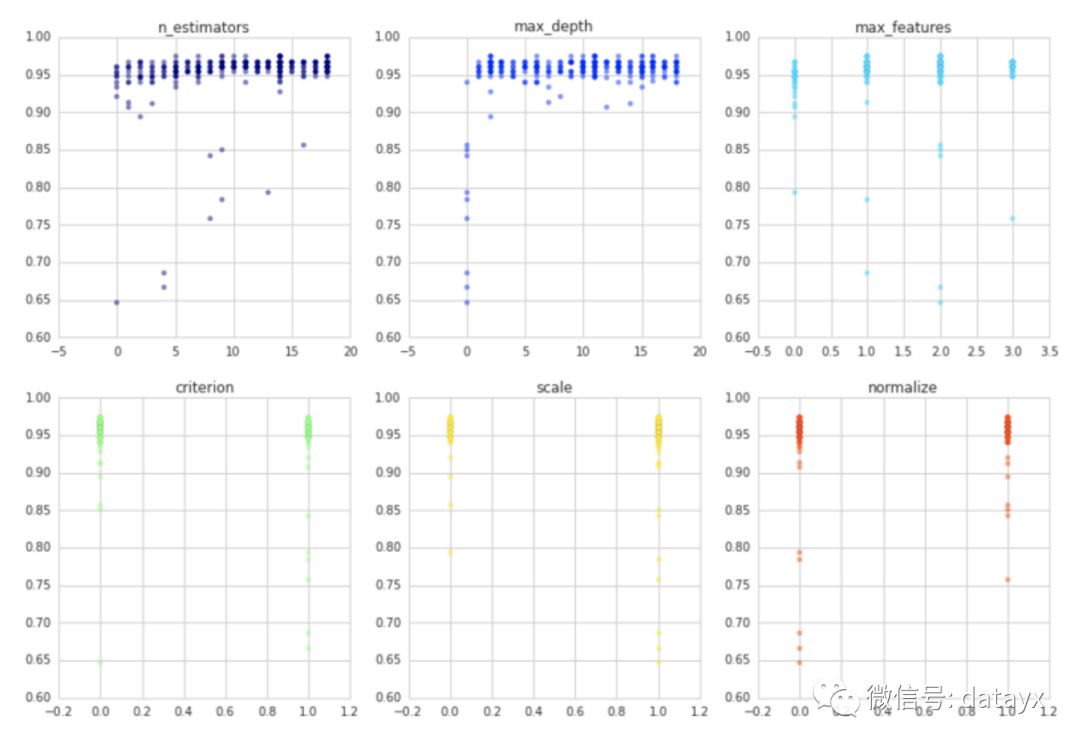
是时候把所有东西合为一体了
自动调整一个模型的参数(如SVM或KNN)非常有趣并且具有启发性,但同时调整它们并取得全局最佳模型则更有用。这使我们能够一次比较所有参数和所有模型,因此为我们提供了最佳模型。代码如下:
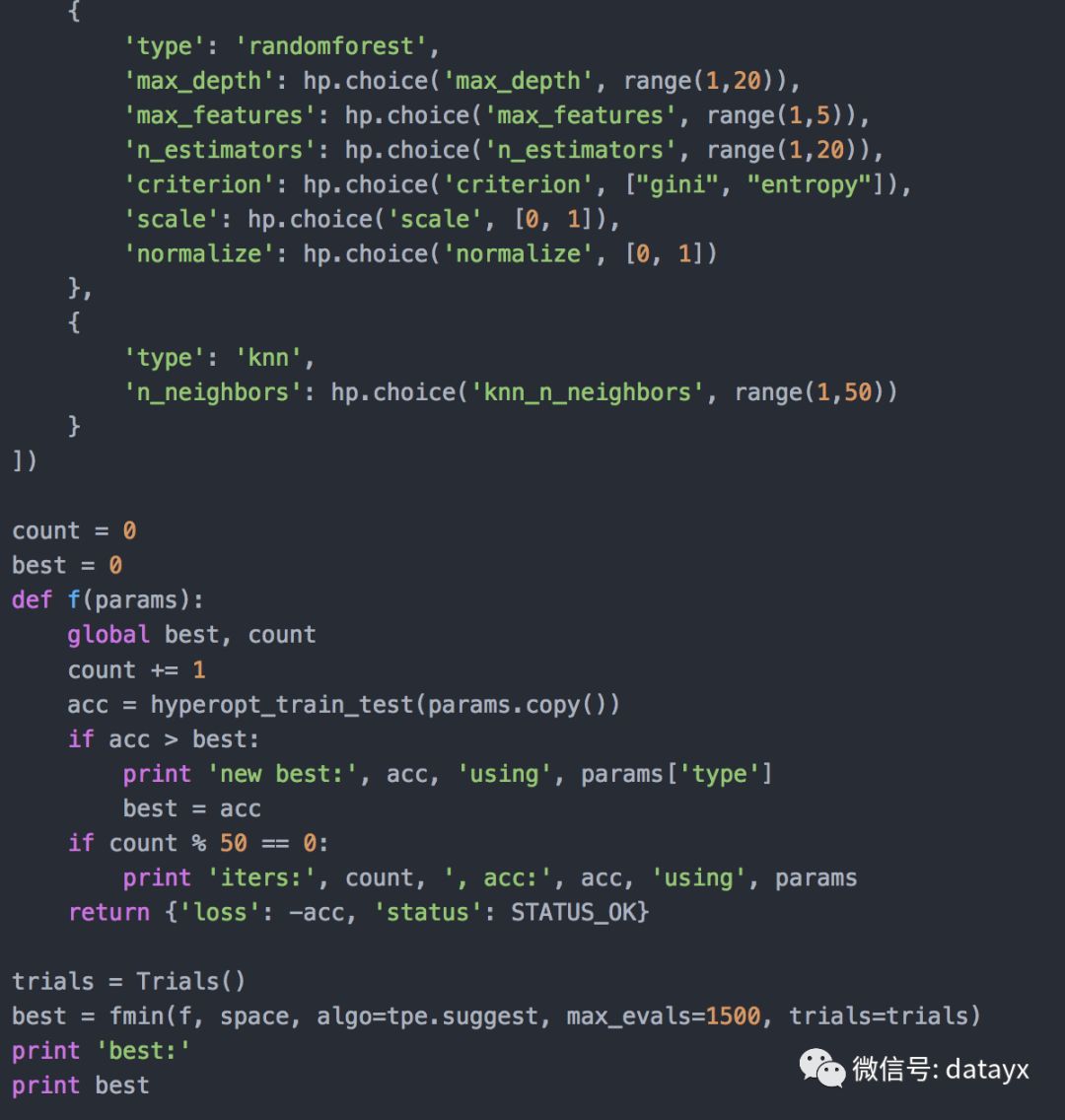
由于我们增加了评估数量,此代码需要一段时间才能运行完:max_evals=1500。当找到新的最佳准确率时,它还会添加到输出用于更新。好奇为什么使用这种方法没有找到前面的最佳模型:参数为kernel=linear,C=1.416,gamma=15.042的SVM。
卷积神经网络训练的典型超参数的列表
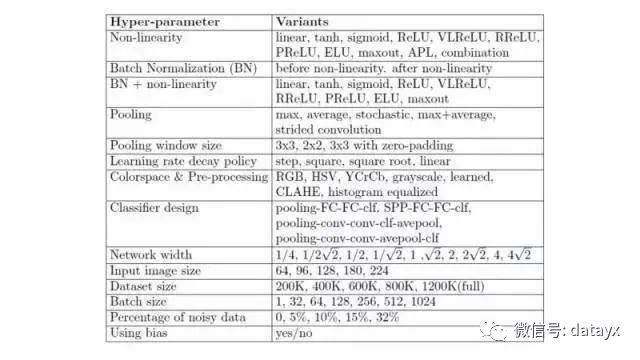
在开始训练一个模型之前,每个机器学习案例都要选择大量参数;而在使用深度学习时,参数的数量还会指数式增长。在上面的图中,你可以看到在训练计算机视觉卷积神经网络时你要选择的典型参数。
但有一个可以自动化这个选择过程的方法!非常简单,当你要选择一些参数和它们的值时,你可以:
启动网格搜索,尝试检查每种可能的参数组合,当有一种组合优化了你的标准时(比如损失函数达到最小值),就停止搜索。当然,在大多数情况下,你可等不了那么久,所以随机搜索是个好选择。这种方法可以随机检查超参数空间,但速度更快而且大多时候也更好。贝叶斯优化——我们为超参数分布设置一个先决条件,然后在观察不同实验的同时逐步更新它,这让我们可以更好地拟合超参数空间,从而更好地找到最小值。
在这篇文章中,我们将把最后一个选项看作是一个黑箱,并且重点关注实际实现和结果分析。
完整代码获取方式:
关注微信公众号 datayx 然后回复 自动调参 即可获取。
HFT 比特币预测
我使用的数据来自 Kaggle,这是用户 @Zielak 贴出的比特币过去 5 年的每分钟价格数据,数据集地址:https://www.kaggle.com/mczielinski/bitcoin-historical-data。
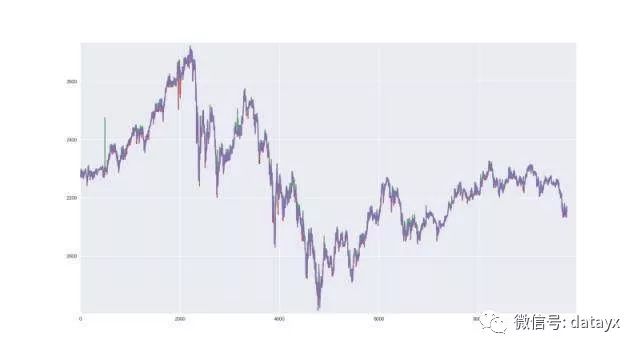
比特币价格的样本图
我们将取出其中最近 10000 分钟的一个子集,并尝试构建一个能够基于我们选择的一段历史数据预测未来 10 分钟价格变化的最好模型。
对于输入,我想使用 OHLCV 元组外加波动,并将这个数组展开以将其输入多层感知器(MLP)模型。
优化 MLP 参数
我们将使用 Hyperopt 库来做超参数优化,它带有随机搜索和 Tree of Parzen Estimators(贝叶斯优化的一个变体)的简单接口。Hyperopt 库地址:http://hyperopt.github.io/hyperopt
我们只需要定义超参数空间(词典中的关键词)和它们的选项集(值)。你可以定义离散的值选项(用于激活函数)或在某个范围内均匀采样(用于学习率)。
在我们的案例中,我想检查:
我们需要更复杂还是更简单的架构(神经元的数量)激活函数(看看 ReLU 是不是真的是最佳选择)学习率优化标准(也许我们可以最小化 logcosh 或 MAE,而不是 MSE)我们需要的穿过网络的时间窗口,以便预测接下来 10 分钟
当我们用 params 词典的对应值替换了层或数据准备或训练过程的真正参数后(我建议你阅读 GitHub 上的完整代码)
我们将检查网络训练的前 5 epoch 的性能。在运行了这个代码之后,我们将等待使用不同参数的 50 次迭代(实验)执行完成,Hyperopt 将为我们选出其中最好的选择,也就是:
best:{'units1': 1, 'loss': 1, 'units3': 0, 'units2': 0, 'activation': 1, 'window': 0, 'lr': 0}
这表示我们需要最后两层有 64 个神经元而第一层有 512 个神经元、使用 sigmoid 激活函数(有意思)、取经典的学习率 0.001、取 30 分钟的时间窗口来预测接下来的 10 分钟……很好。
结果
首先我们要构建一个「金字塔」模式的网络,我常常用这种模式来处理新数据。大多时候我也使用 ReLU 作为激活函数,并且为 Adam 优化器取标准的学习率 0.002.
看看表现如何,蓝色是我们的预测,而黑色是原始情况,差异很大,MSE = 0.0005,MAE = 0.017。
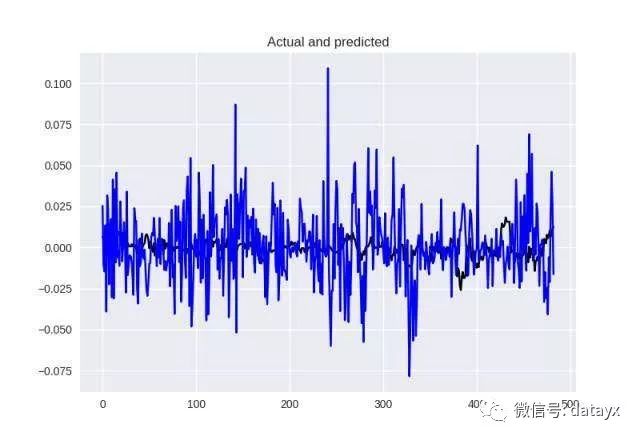
基本架构的结果
现在看看使用 Hyperopt 找到的超参数的模型在这些数据上表现如何:
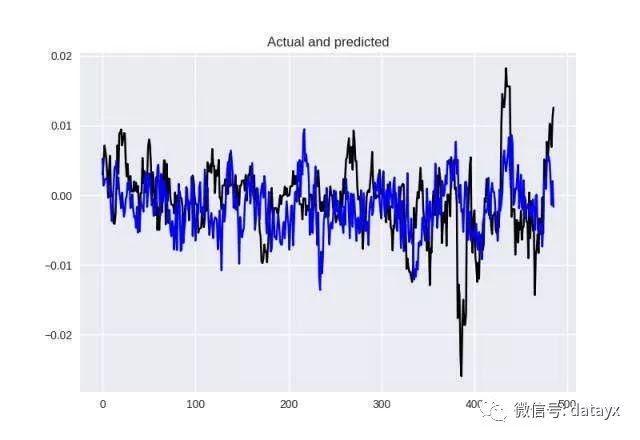
使用 Hyperopt 找的参数所得到的结果
在这个案例中,数值结果(MSE = 4.41154599032e-05,MAE = 0.00507)和视觉效果都好得多。
老实说,我认为这不是个好选择,尤其是我并不同意如此之短的训练时间窗口。我仍然想尝试 60 分钟,而且我认为对于回归而言,Log-Cosh 损失是更加有趣的损失函数选择。但我现在还是继续使用 sigmoid 激活函数,因为看起来这就是表现极大提升的关键。
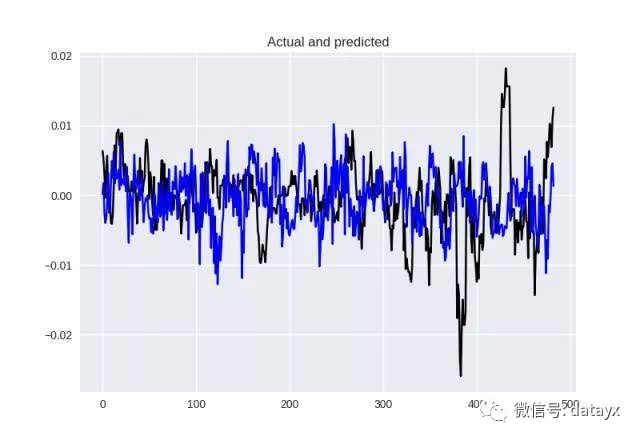
这里得到 MSE = 4.38998280095e-05 且 MAE = 0.00503,仅比用 Hyperbot 的结果好一点点,但视觉效果差多了(完全搞错了趋势)。
结论
我强烈推荐你为你训练的每个模型使用超参数搜索,不管你操作的是什么数据。有时候它会得到意料之外的结果,比如这里的超参数(还用 sigmoid?都 2017 年了啊?)和窗口大小(我没料到半小时的历史信息比一个小时还好)。
如果你继续深入研究一下Hyperopt,你会看到你也可以搜索隐藏层的数量、是否使用多任务学习和损失函数的系数。基本上来说,你只需要取你的数据的一个子集,思考你想调节的超参数,然后等你的计算机工作一段时间就可以了。这是自动化机器学习的第一步!
https://www.jianshu.com/p/35eed1567463
https://medium.com/@alexrachnog/neural-networks-for-algorithmic-trading-hyperparameters-optimization-cb2b4a29b8ee
阅读过本文的人还看了以下:
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

长按图片,识别二维码,点关注








