

大家好!又到了每周一狗熊会的深度学习时间了。在上一讲中,小编将关注重点首次切到了自然语言处理领域。我们介绍了自然语言处理领域的基本知识体系,对 one-hot 和词嵌入这两种基本的词汇表征方法进行了详细的介绍,对词嵌入代表方法词向量进行了阐述,并以 SVD 词向量模型进行了演示。本节小编将继续和大家一起学习基于神经网络模型的词向量表征方法,其中的代表模型就是著名的 word2vec。

从深度学习的角度看,假设我们将 NLP 的语言模型看作是一个监督学习问题:即给定上下文词 X,输出中间词 Y,或者给定中间词 X,输出上下文词 Y。基于输入 X 和输出 Y 之间的映射便是语言模型。这样的一个语言模型的目的便是检查 X 和 Y 放在一起是否符合自然语言法则,更通俗一点说就是 X 和 Y 搁一起是不是人话。

所以,基于监督学习的思想,本文的主角——word2vec 便是一种基于神经网络训练的自然语言模型。word2vec 是谷歌于 2013 年提出的一种 NLP 工具,其特点就是将词汇进行向量化,这样我们就可以定量的分析和挖掘词汇之间的联系。因而 word2vec 也是我们上一讲讲到的词嵌入表征的一种,只不过这种向量化表征需要经过神经网络训练得到。
word2vec 训练神经网络得到一个关于输入 X 和 输出 Y 之间的语言模型,我们的关注重点并不是说要把这个模型训练的有多好,而是要获取训练好的神经网络权重,这个权重就是我们要拿来对输入词汇 X 的向量化表示。一旦我们拿到了训练语料所有词汇的词向量,接下来开展 NLP 分析工作就相对容易一些了。
word2vec 通常有两个版本的语言模型。一种是给定上下文词,需要我们来预测中间目标词,这种模型叫做连续词袋模型(Continuous Bag-of-Wods Model,CBOW),另一种是给定一个词语,我们来根据这个词预测它的上下文,这种模型叫做 skip-gram 模型。而且每个模型都有两种策略,本文这里不做详细介绍。下面小编就分别来简单介绍一下这两种 word2vec 模型。
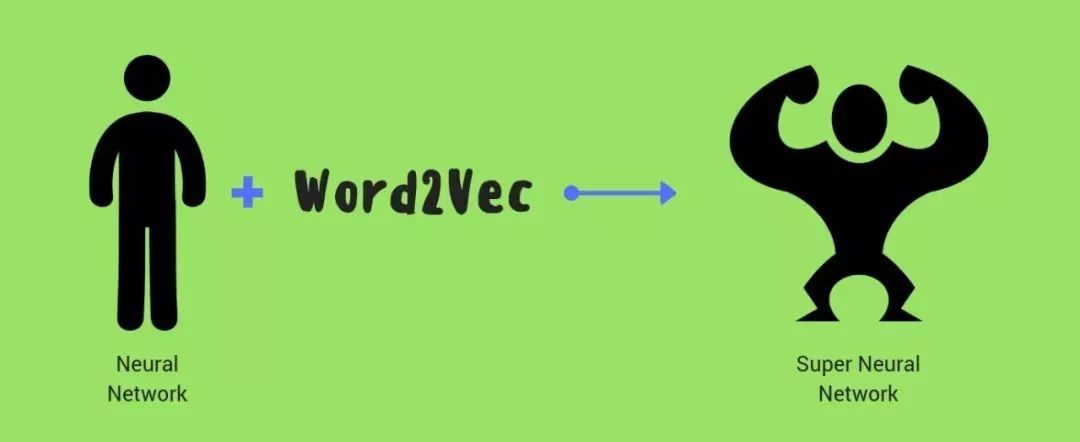
CBOW 模型的应用场景是要根据上下文预测中间词,所以我们的输入便是上下文词,当然原始的单词是无法作为输入的,这里的输入仍然是每个词汇的 one-hot 向量,输出 Y 为给定词汇表中每个词作为目标词的概率。参考 Rong Xin 大佬论文中给出的 CBOW 模型的结构图:
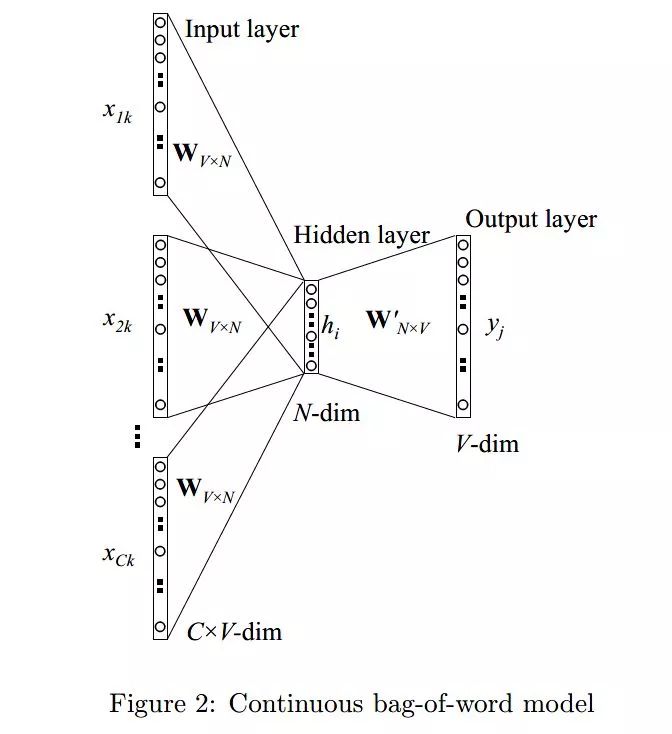
skip-gram 模型的应用场景是要根据中间词预测上下文词,所以我们的输入 X 是任意单词,输出 Y 为给定词汇表中每个词作为上下文词的概率。参考 Rong Xin 大佬论文中给出的 skip-gram 模型的结构图:
从 CBOW 和 skip-gram 模型的结构图可以看到,二者除了在输入输出上有所不同外,基本上没有太大区别。将 CBOW 的输入层换成输出层基本上就变成了 skip-gram 模型,二者可以理解为一种互为翻转的关系。关于 word2vec 这两种模型的更多数学细节小编这里不做更多讲解,感兴趣的朋友可以重点阅读本文给出的参考论文。
从监督学习的角度来说,word2vec 本质上是一个基于神经网络的多分类问题,当输出词语非常多时,我们则需要一些像分级 Softmax 和负采样之类的 trick 来加速训练。但从自然语言处理的角度来说,word2vec 关注的并不是神经网络模型本身,而是训练之后得到的词汇的向量化表征。这种表征使得最后的词向量维度要远远小于词汇表大小,所以 word2vec 从本质上来说是一种降维操作。我们把数以万计的词汇从高维空间中降维到低维空间中,大大方便了后续的 NLP 分析任务。
本节我们以 CBOW 模型为例展示一下 word2vec 是如何训练得到词向量的。先用一张图标出 CBOW 模型要训练的参数,很明显我们要训练得到输入层到隐藏层的权重以及隐藏层到输出层的权重。
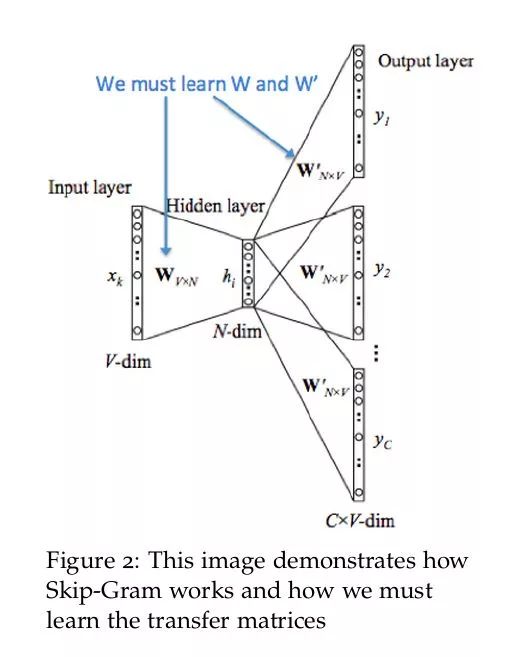
CBOW 模型训练的基本步骤包括:
将上下文词进行 one-hot 表征作为模型的输入,其中词汇表的维度为 V,上下文单词数量为 C ;
然后将所有上下文词汇的 one-hot 向量分别乘以共享的输入权重矩阵 W;
将上一步得到的各个向量相加取平均作为隐藏层向量;
将隐藏层向量乘以共享的输出权重矩阵 W‘;
将计算得到的向量做 softmax 激活处理得到 V 维的概率分布,取概率最大的索引作为预测的目标词。
下面以知乎大佬 crystalajj 提供的 PPT 为例看一下 CBOW 模型训练流程。假设语料为【I drink coffee everyday】,以【I drink everyday】作为上下文词,以【coffee】作为目标词。
将上下文词和目标词都进行 one-hot 表征作为输入:
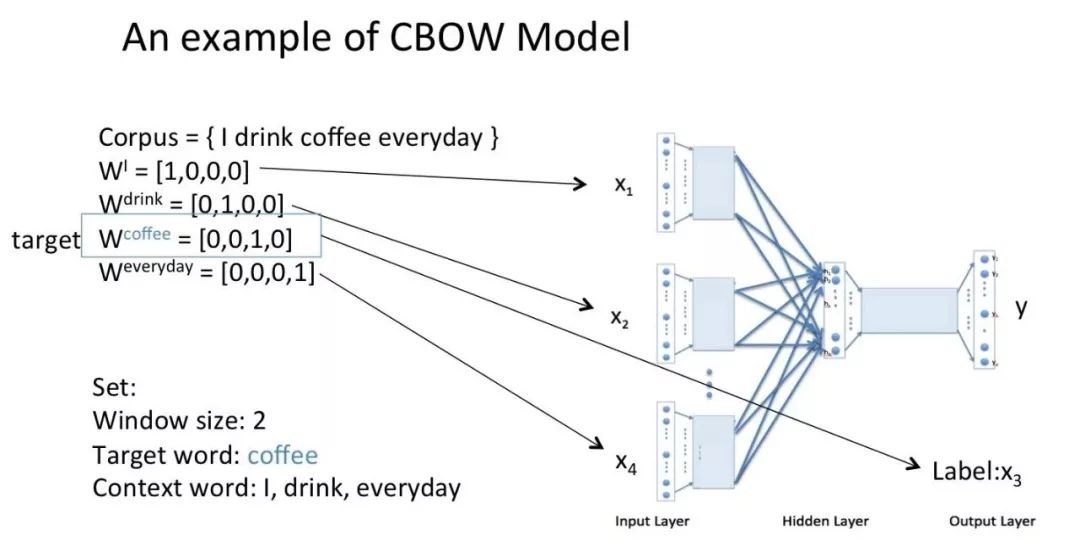
然后将 one-hot 表征结果分别乘以输入层权重矩阵,这个矩阵也叫嵌入矩阵,可以随机初始化生成。
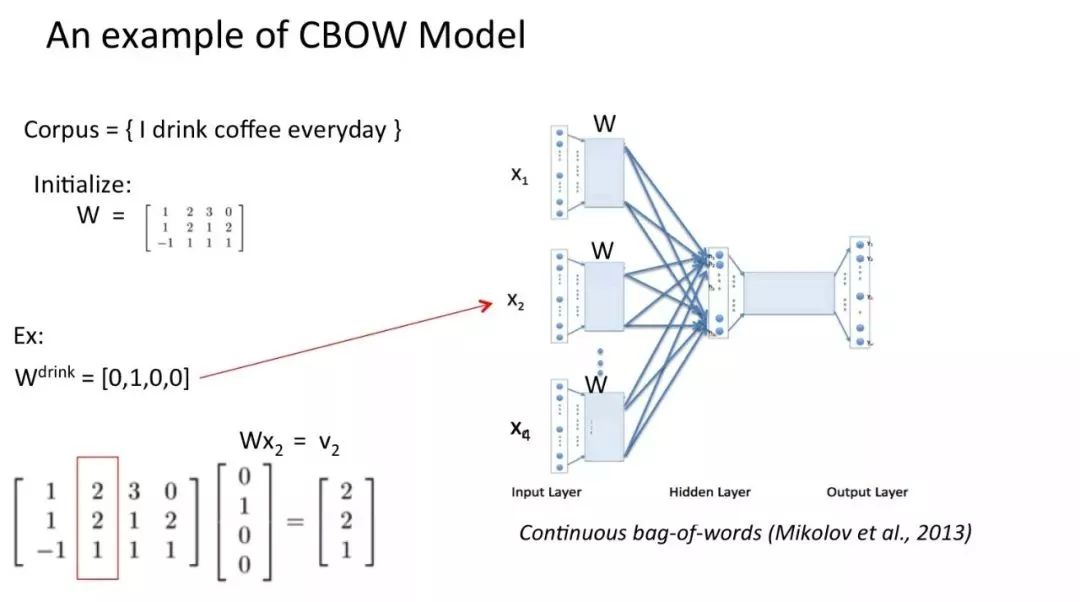
将得到的结果向量求平均作为隐藏层向量:
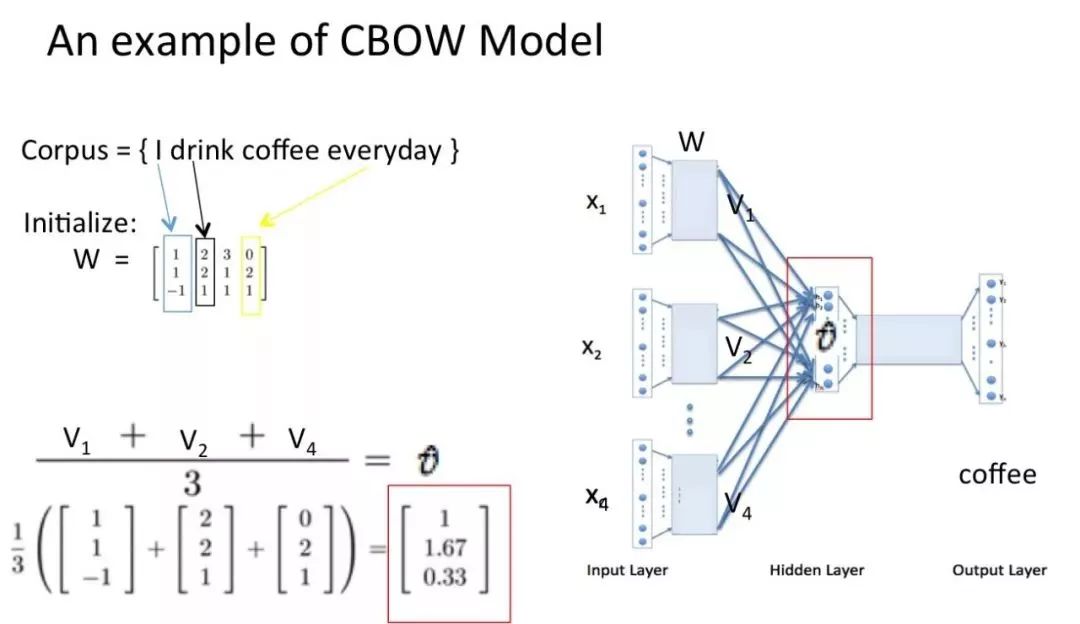
然后将隐藏层向量乘以输出层权重矩阵,这个矩阵也是嵌入矩阵,可以初始化得到。得到输出向量:
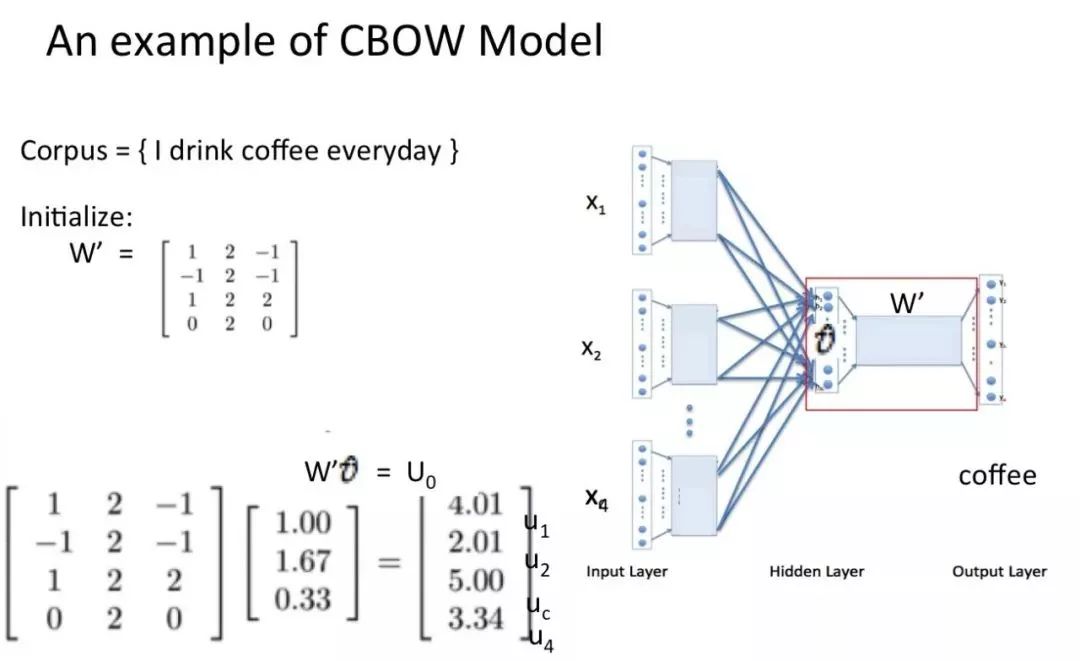
最后对输出向量做 softmax 激活处理得到实际输出,并将其与真实标签做比较,然后基于损失函数做梯度优化训练。
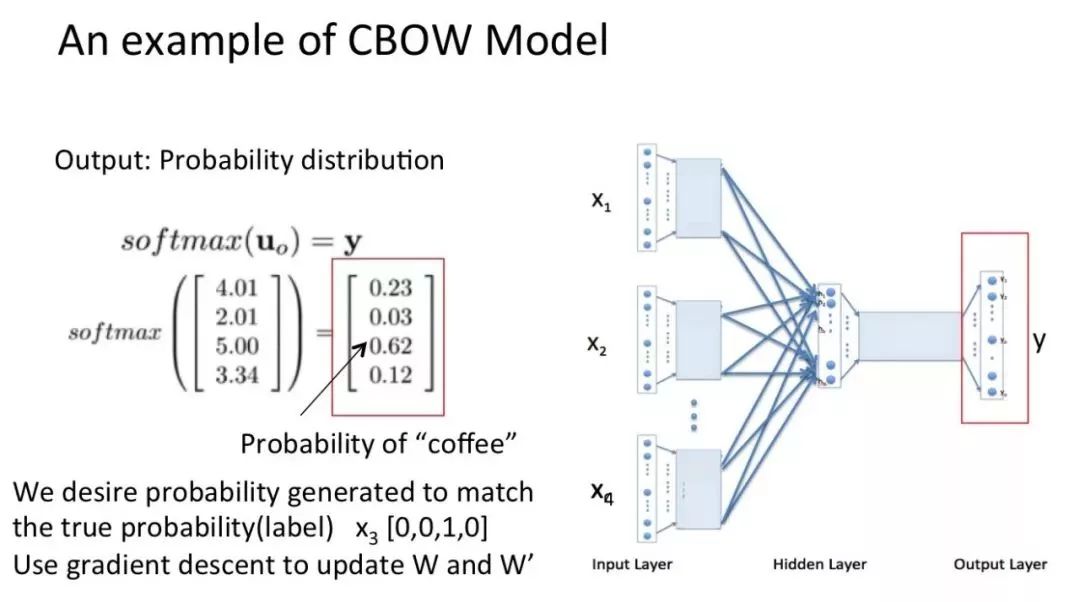
以上便是完整的 CBOW 模型计算过程,也是 word2vec 将词汇训练为词向量的基本方法之一。
无论是 skip-gram 模型还是 CBOW 模型,word2vec 一般而言都能提供较高质量的词向量表达,下图是以 50000 个单词训练得到的 128 维的 skip-gram 词向量压缩到 2 维空间中的可视化展示图:
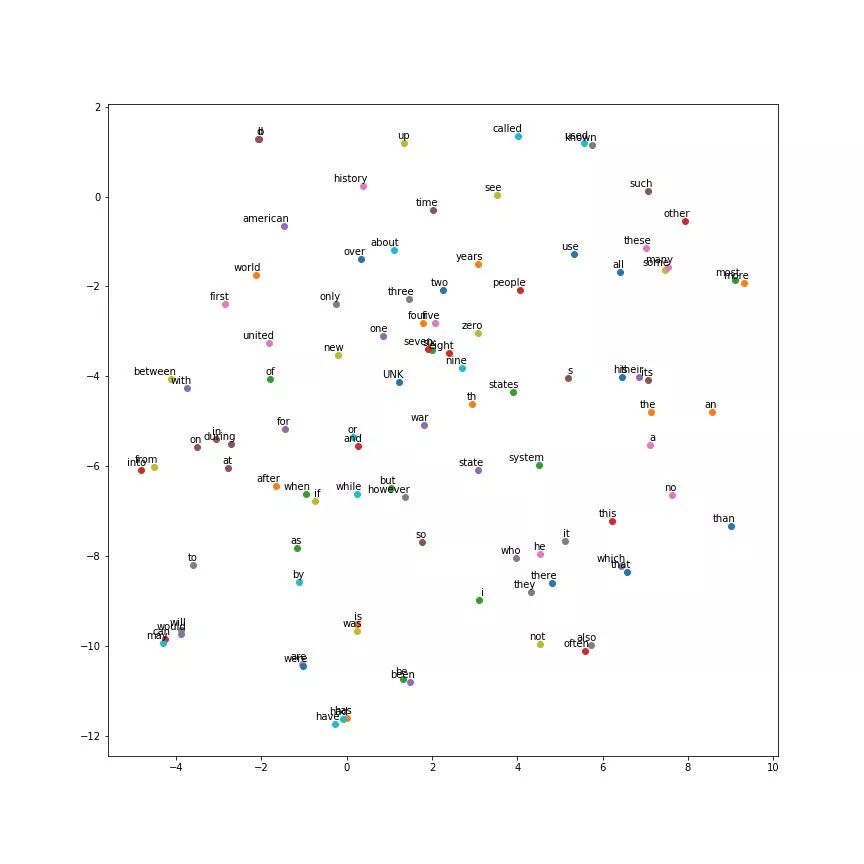
可以看到,意思相近的词基本上被聚到了一起,也证明了 word2vec 是一种可靠的词向量表征方式。
以上便是本讲内容。
在本节内容中,小编和大家重点介绍了 word2vec 模型,对 word2vec 的两种基本模型 CBOW 模型和 skip-gram 模型进行了简单的介绍,并以 CBOW 模型为例对 word2vec 训练得到词向量的过程进行了展示。咱们下一期见!
【参考资料】
deeplearningai.com
http://cs224d.stanford.edu/
https://www.zhihu.com/question/44832436/answer/266068967
https://cs224d.stanford.edu/lecture_notes/notes1.pdf
鲁伟,狗熊会人才计划一期学员。目前在杭州某软件公司从事数据分析和深度学习相关的研究工作,研究方向为贝叶斯统计、计算机视觉和迁移学习。

识别二维码,查看作者更多精彩文章
识别下方二维码成为狗熊会会员!
友情提示:
个人会员不提供数据、代码,
视频only!
个人会员网址:http://teach.xiong99.com.cn










