在深度学习中,梯度消失和梯度爆炸是训练深层神经网络时常见的两大问题,它们会严重影响网络的训练过程和性能。梯度消失,梯度趋零难更新;梯度爆炸,梯度过大不稳定。为了解决这些问题,可以采取多种策略,包括选择合适的激活函数、采用合适的权重初始化方法、引入批量归一化、使用残差连接、实施梯度裁剪以及使用更稳健的优化器等。这些策略可以有效地提高模型的训练效率和性能,从而推动深度学习技术的进一步发展。Vanishing Gradient & Exploding Gradient
什么是梯度消失(Vanishing Gradient)?梯度消失是指在深层神经网络的反向传播过程中,当网络通过链式法则计算梯度以更新权重时,梯度值随着层数的增加而迅速减小,最终趋近于零。这会导致靠近输入层的权重更新变得非常缓慢,甚至几乎不更新,从而阻止网络从输入数据中学习有效的特征表示。梯度消失的原因是什么?梯度消失的主要原因包括激活函数的选择、链式法则的应用、权重初始化不当以及网络层数过多
等。激活函数的选择:在使用某些激活函数(如Sigmoid和Tanh)时,当输入值非常大或非常小的时候,这些函数的导数(或梯度)会趋近于零。
链式法则的应用:在深度神经网络中,梯度是通过链式法则从输出层逐层反向传播到输入层的。每一层的梯度都是前一层梯度与该层激活函数导数的乘积。如果每一层的梯度都稍微减小一点,那么经过多层传播后,梯度值就会变得非常小,几乎为零。
权重初始化不当:如果网络权重的初始值设置得太小,那么在前向传播过程中,输入信号可能会迅速衰减,导致激活函数的输入值非常小,进而使得梯度在反向传播过程中也迅速减小。
网络层数过多:随着网络层数的增加,梯度需要通过更多的层进行反向传播。每一层都可能对梯度进行一定的衰减,因此层数越多,梯度消失的风险就越大。
为了缓解梯度消失问题,可以采取多种策略,如使用ReLU或其变体作为激活函数、采用合适的权重初始化策略、引入批量归一化(Batch Normalization)以及使用残差连接(Residual Connections)等。
什么是梯度爆炸(Exploding Gradient)?梯度爆炸是指在反向传播过程中,梯度值随着层数的增加而迅速增大,最终变得非常大,超出了神经网络的正常处理范围,从而导致模型参数更新不稳定,甚至训练失败。
梯度爆炸的原因是什么?梯度爆炸的原因主要包括权重初始化过大、网络层数过多以及学习率设置过高等。
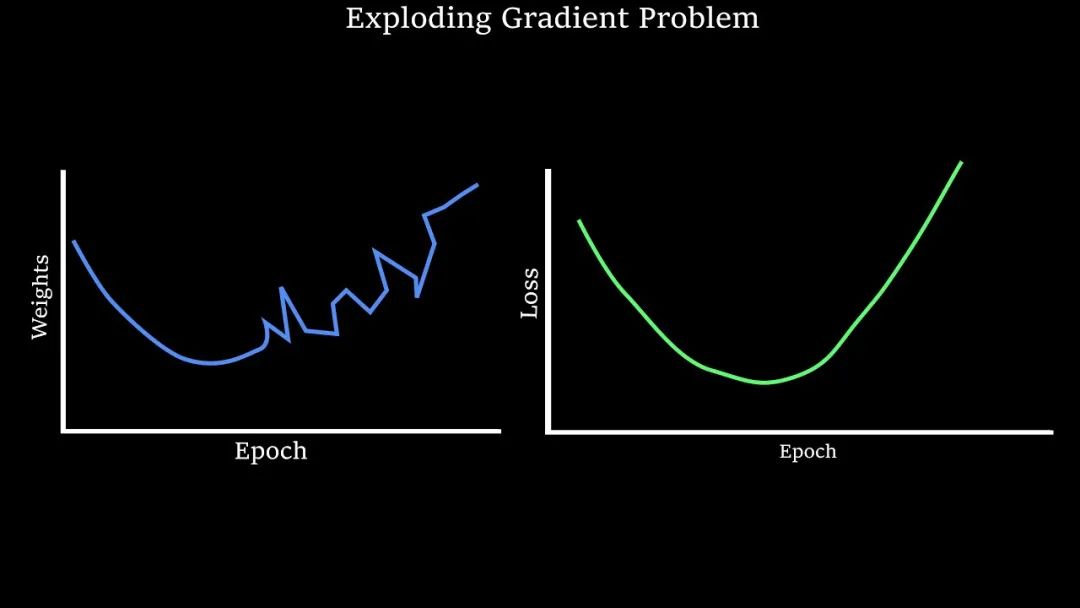
权重初始化过大:在神经网络中,如果权重的初始值设置得过大,那么在反向传播过程中,梯度值可能会因为权重的累积效应而迅速增大,导致梯度爆炸。
网络层数过多:在深层神经网络中,由于链式法则的应用,梯度需要通过多层进行反向传播。如果每一层的梯度都稍微增大一点,那么经过多层传播后,梯度值就会变得非常大,导致梯度爆炸。
学习率设置过高:学习率决定了模型参数更新的步长。如果学习率设置得过高,那么模型参数在更新时可能会因为步长过大而跳出最优解的范围,同时过高的学习率会使模型在更新参数时过于激进,从而加剧梯度的波动。
为了缓解梯度爆炸问题,可以采取多种策略,如使用梯度裁剪、合理初始化权重、调整学习率并选择稳定的优化算法来降低梯度爆炸的风险。
为了帮助更多人(AI初学者、IT从业者)从零构建AI底层架构,培养Meta Learning能力;提升AI认知,拥抱智能时代。
建立了 架构师带你玩转AI 知识星球
【架构师带你玩转AI】:公众号@架构师带你玩转AI 作者,资深架构师。2022年底,ChatGPT横空出世,人工智能时代来临。身为公司技术总监、研发团队Leader,深感未来20年属于智能时代。
公众号一周年之际,答谢粉丝,特申请了100份星球优惠券









